 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning on Lie Groups for Skeleton-based Action Recognition
Paper and Code
Apr 11, 2017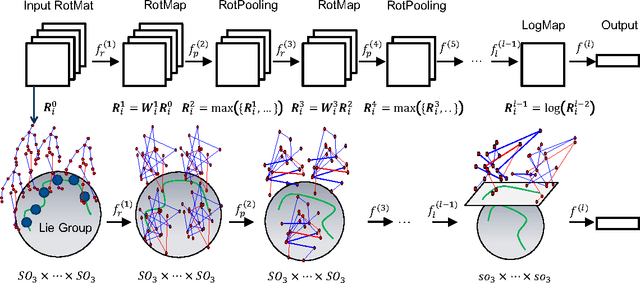
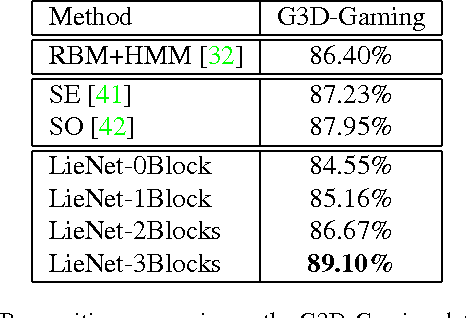
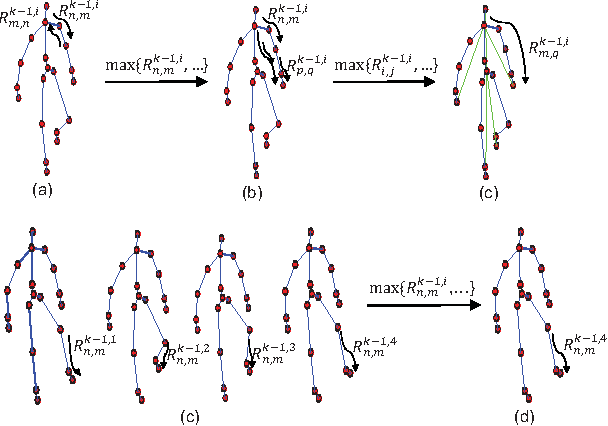
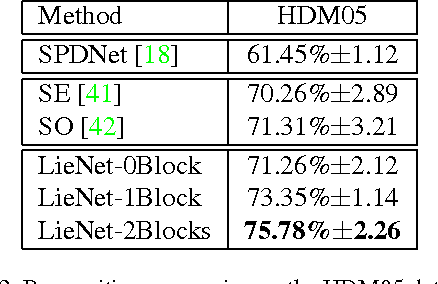
In recent years, skeleton-based action recognition has become a popular 3D classification problem. State-of-the-art methods typically first represent each motion sequence as a high-dimensional trajectory on a Lie group with an additional dynamic time warping, and then shallowly learn favorable Lie group features. In this paper we incorporate the Lie group structure into a deep network architecture to learn more appropriate Lie group features for 3D action recognition. Within the network structure, we design rotation mapping layers to transform the input Lie group features into desirable ones, which are aligned better in the temporal domain. To reduce the high feature dimensionality, the architecture is equipped with rotation pooling layers for the elements on the Lie group. Furthermore, we propose a logarithm mapping layer to map the resulting manifold data into a tangent space that facilitates the application of regular output layers for the final classification. Evaluations of the proposed network for standard 3D human action recognition datasets clearly demonstrate its superiority over existing shallow Lie group feature learning methods as well as most conventional deep learning methods.