 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural 4D Evolution under Large Topological Changes from 2D Images
Nov 22, 2024In the literature, it has been shown that the evolution of the known explicit 3D surface to the target one can be learned from 2D images using the instantaneous flow field, where the known and target 3D surfaces may largely differ in topology. We are interested in capturing 4D shapes whose topology changes largely over time. We encounter that the straightforward extension of the existing 3D-based method to the desired 4D case performs poorly. In this work, we address the challenges in extending 3D neural evolution to 4D under large topological changes by proposing two novel modifications. More precisely, we introduce (i) a new architecture to discretize and encode the deformation and learn the SDF and (ii) a technique to impose the temporal consistency. (iii) Also, we propose a rendering scheme for color prediction based on Gaussian splatting. Furthermore, to facilitate learning directly from 2D images, we propose a learning framework that can disentangle the geometry and appearance from RGB images. This method of disentanglement, while also useful for the 4D evolution problem that we are concentrating on, is also novel and valid for static scenes. Our extensive experiments on various data provide awesome results and, most importantly, open a new approach toward reconstructing challenging scenes with significant topological changes and deformations. Our source code and the dataset are publicly available at https://github.com/insait-institute/N4DE.
Gradient Obfuscation Checklist Test Gives a False Sense of Security
Jun 03, 2022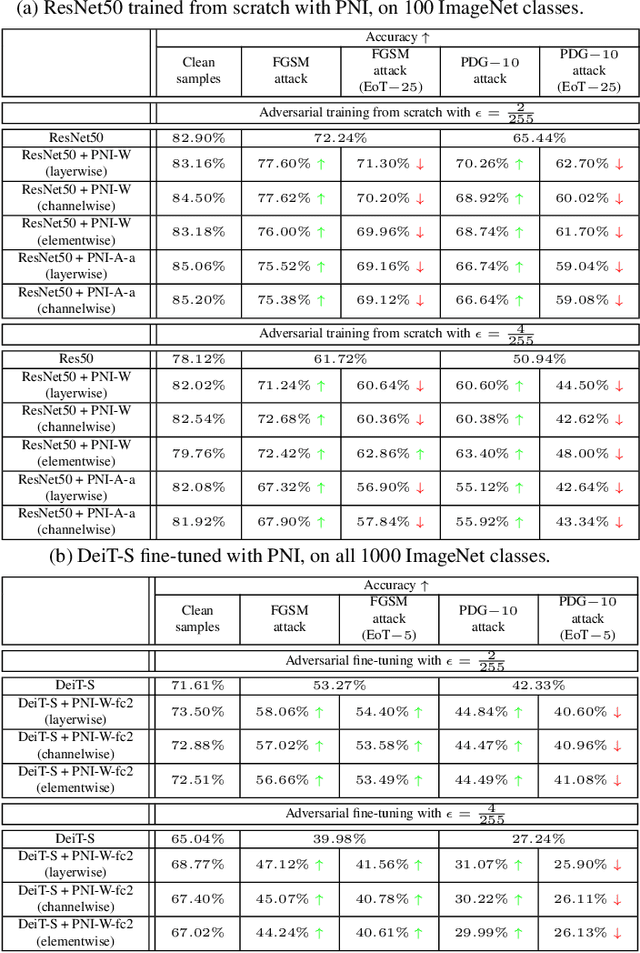
One popular group of defense techniques against adversarial attacks is based on injecting stochastic noise into the network. The main source of robustness of such stochastic defenses however is often due to the obfuscation of the gradients, offering a false sense of security. Since most of the popular adversarial attacks are optimization-based, obfuscated gradients reduce their attacking ability, while the model is still susceptible to stronger or specifically tailored adversarial attacks. Recently, five characteristics have been identified, which are commonly observed when the improvement in robustness is mainly caused by gradient obfuscation. It has since become a trend to use these five characteristics as a sufficient test, to determine whether or not gradient obfuscation is the main source of robustness. However, these characteristics do not perfectly characterize all existing cases of gradient obfuscation, and therefore can not serve as a basis for a conclusive test. In this work, we present a counterexample, showing this test is not sufficient for concluding that gradient obfuscation is not the main cause of improvements in robustness.
Coarse-to-Fine Feature Mining for Video Semantic Segmentation
Apr 07, 2022
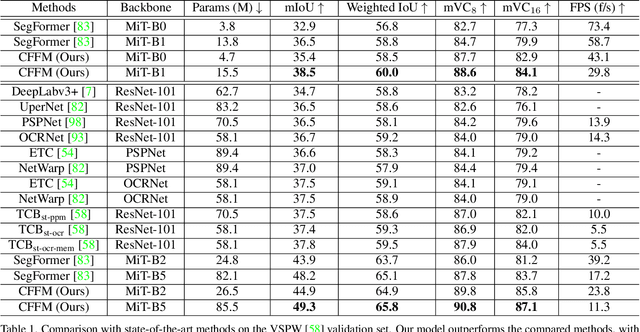
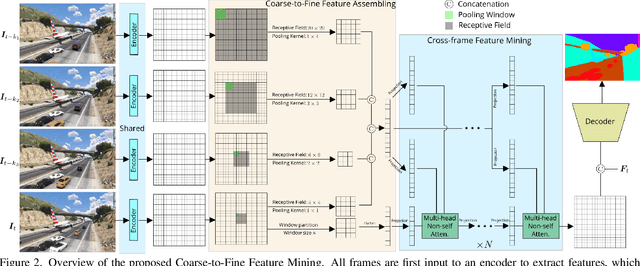
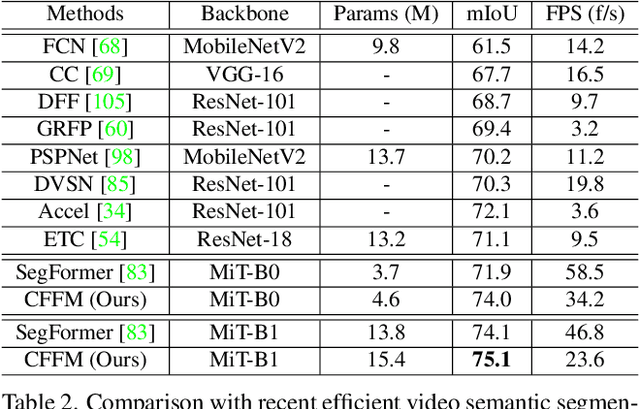
The contextual information plays a core role in semantic segmentation. As for video semantic segmentation, the contexts include static contexts and motional contexts, corresponding to static content and moving content in a video clip, respectively. The static contexts are well exploited in image semantic segmentation by learning multi-scale and global/long-range features. The motional contexts are studied in previous video semantic segmentation. However, there is no research about how to simultaneously learn static and motional contexts which are highly correlated and complementary to each other. To address this problem, we propose a Coarse-to-Fine Feature Mining (CFFM) technique to learn a unified presentation of static contexts and motional contexts. This technique consists of two parts: coarse-to-fine feature assembling and cross-frame feature mining. The former operation prepares data for further processing, enabling the subsequent joint learning of static and motional contexts. The latter operation mines useful information/contexts from the sequential frames to enhance the video contexts of the features of the target frame. The enhanced features can be directly applied for the final prediction. Experimental results on popular benchmarks demonstrate that the proposed CFFM performs favorably against state-of-the-art methods for video semantic segmentation. Our implementation is available at https://github.com/GuoleiSun/VSS-CFFM
Spatially Multi-conditional Image Generation
Mar 25, 2022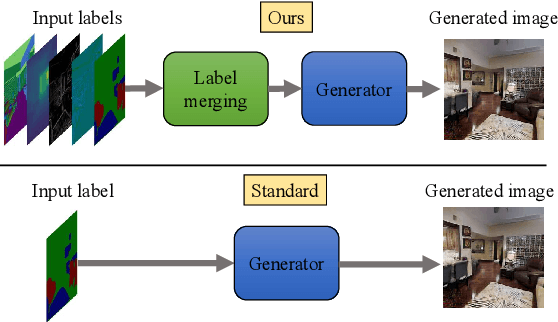


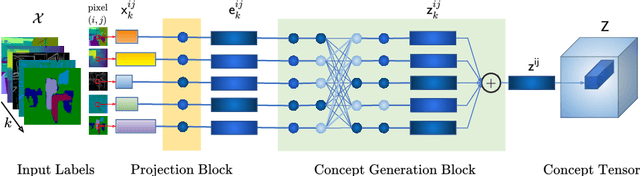
In most scenarios, conditional image generation can be thought of as an inversion of the image understanding process. Since generic image understanding involves the solving of multiple tasks, it is natural to aim at the generation of images via multi-conditioning. However, multi-conditional image generation is a very challenging problem due to the heterogeneity and the sparsity of the (in practice) available conditioning labels. In this work, we propose a novel neural architecture to address the problem of heterogeneity and sparsity of the spatially multi-conditional labels. Our choice of spatial conditioning, such as by semantics and depth, is driven by the promise it holds for better control of the image generation process. The proposed method uses a transformer-like architecture operating pixel-wise, which receives the available labels as input tokens to merge them in a learned homogeneous space of labels. The merged labels are then used for image generation via conditional generative adversarial training. In this process, the sparsity of the labels is handled by simply dropping the input tokens corresponding to the missing labels at the desired locations, thanks to the proposed pixel-wise operating architecture. Our experiments on three benchmark datasets demonstrate the clear superiority of our method over the state-of-the-art and the compared baselines.
Stochastic Layers in Vision Transformers
Dec 30, 2021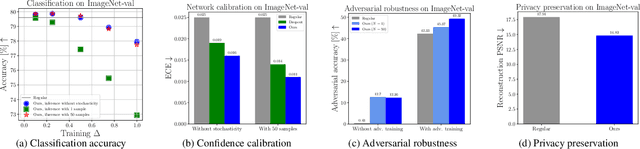
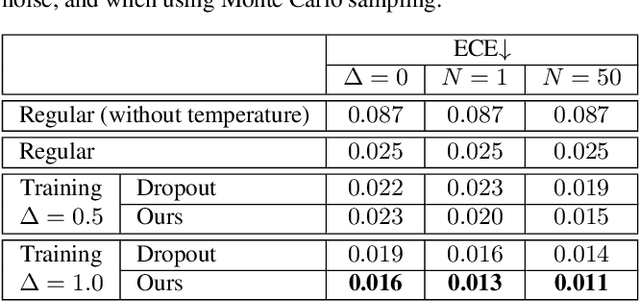

We introduce fully stochastic layers in vision transformers, without causing any severe drop in performance. The additional stochasticity boosts the robustness of visual features and strengthens privacy. In this process, linear layers with fully stochastic parameters are used, both during training and inference, to transform the feature activations of each multilayer perceptron. Such stochastic linear operations preserve the topological structure, formed by the set of tokens passing through the shared multilayer perceptron. This operation encourages the learning of the recognition task to rely on the topological structures of the tokens, instead of their values, which in turn offers the desired robustness and privacy of the visual features. In this paper, we use our features for three different applications, namely, adversarial robustness, network calibration, and feature privacy. Our features offer exciting results on those tasks. Furthermore, we showcase an experimental setup for federated and transfer learning, where the vision transformers with stochastic layers are again shown to be well behaved. Our source code will be made publicly available.
Boosting Crowd Counting with Transformers
May 23, 2021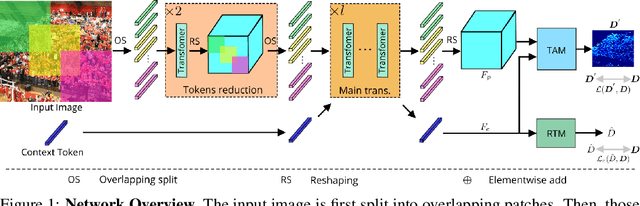
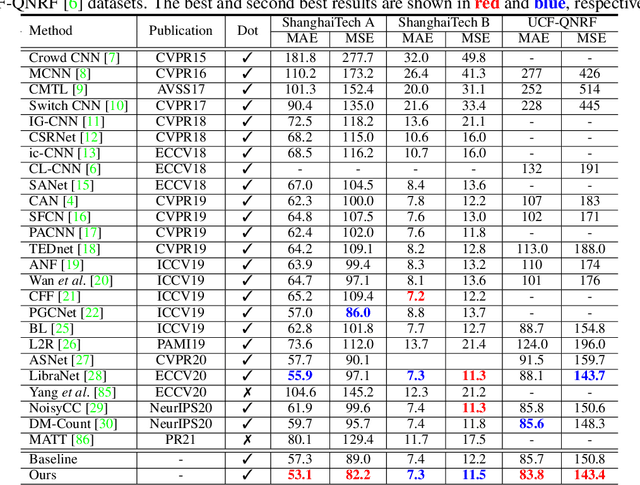
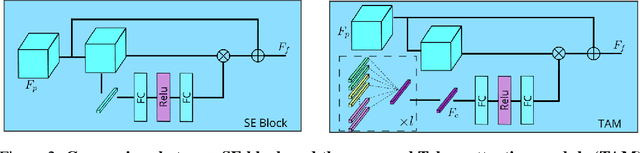
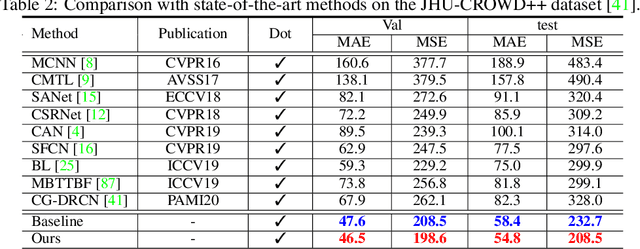
Significant progress on the crowd counting problem has been achieved by integrating larger context into convolutional neural networks (CNNs). This indicates that global scene context is essential, despite the seemingly bottom-up nature of the problem. This may be explained by the fact that context knowledge can adapt and improve local feature extraction to a given scene. In this paper, we therefore investigate the role of global context for crowd counting. Specifically, a pure transformer is used to extract features with global information from overlapping image patches. Inspired by classification, we add a context token to the input sequence, to facilitate information exchange with tokens corresponding to image patches throughout transformer layers. Due to the fact that transformers do not explicitly model the tried-and-true channel-wise interactions, we propose a token-attention module (TAM) to recalibrate encoded features through channel-wise attention informed by the context token. Beyond that, it is adopted to predict the total person count of the image through regression-token module (RTM). Extensive experiments demonstrate that our method achieves state-of-the-art performance on various datasets, including ShanghaiTech, UCF-QNRF, JHU-CROWD++ and NWPU. On the large-scale JHU-CROWD++ dataset, our method improves over the previous best results by 26.9% and 29.9% in terms of MAE and MSE, respectively.
Automatic Programming Through Combinatorial Evolution
Feb 20, 2021
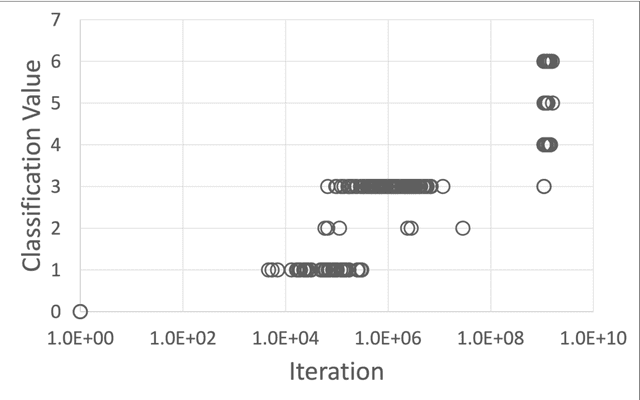

It has been already shown that combinatorial evolution - the creation of new things through the combination of existing things - can be a powerful way to evolve rather than design technical objects such as electronic circuits in a computer simulation. Intriguingly, only a few iterations seem to be required to already achieve complex objects. In the present paper we want to employ combinatorial evolution in software development. Our research question is whether it is possible to generate computer programs of increasing complexity using automatic programming through combinatorial evolution. Specifically, we ask what kind of basic code blocks are needed at the beginning, how are these code blocks implemented to allow them to combine, and how can code complexity be measured. We implemented a computer program simulating combinatorial evolution of code blocks stored in a database to make them available for combinations. Automatic programming is achieved by evaluating regular expressions. We found that reserved key words of a programming language are suitable for defining the basic code blocks at the beginning of the simulation. We also found that placeholders can be used to combine code blocks and that code complexity can be described in terms of the importance to the programming language. As in the previous combinatorial evolution simulation of electronic circuits, complexity increased from simple keywords and special characters to more complex variable declarations, to class definitions, to methods, and to classes containing methods and variable declarations. Combinatorial evolution, therefore, seems to be a promising approach for automatic programming.
Unsupervised Monocular Depth Reconstruction of Non-Rigid Scenes
Dec 31, 2020
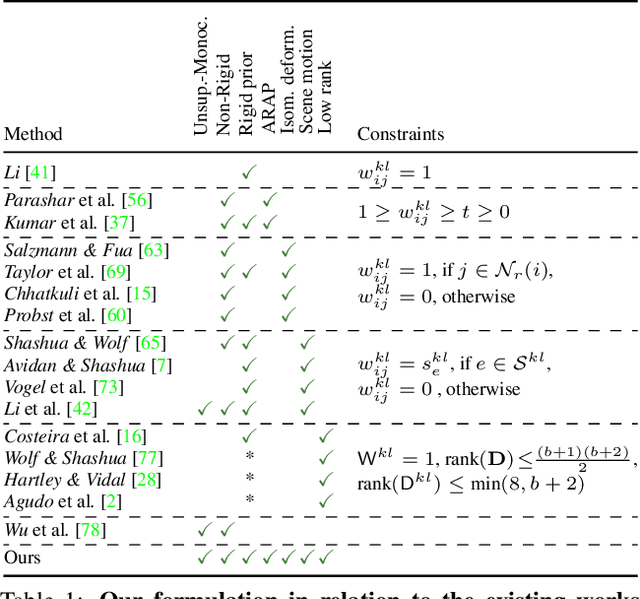
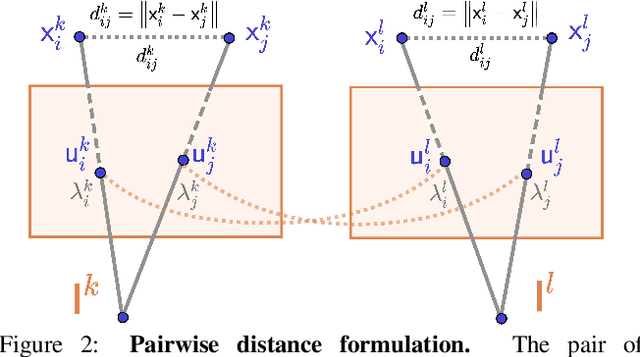
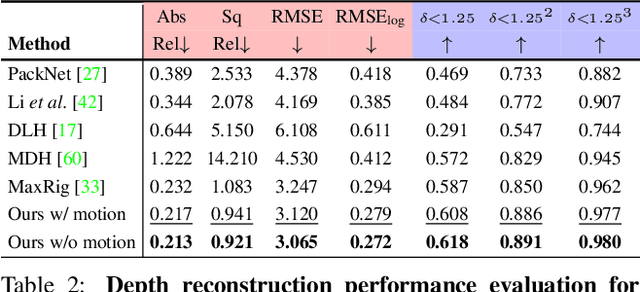
Monocular depth reconstruction of complex and dynamic scenes is a highly challenging problem. While for rigid scenes learning-based methods have been offering promising results even in unsupervised cases, there exists little to no literature addressing the same for dynamic and deformable scenes. In this work, we present an unsupervised monocular framework for dense depth estimation of dynamic scenes, which jointly reconstructs rigid and non-rigid parts without explicitly modelling the camera motion. Using dense correspondences, we derive a training objective that aims to opportunistically preserve pairwise distances between reconstructed 3D points. In this process, the dense depth map is learned implicitly using the as-rigid-as-possible hypothesis. Our method provides promising results, demonstrating its capability of reconstructing 3D from challenging videos of non-rigid scenes. Furthermore, the proposed method also provides unsupervised motion segmentation results as an auxiliary output.
CompositeTasking: Understanding Images by Spatial Composition of Tasks
Dec 16, 2020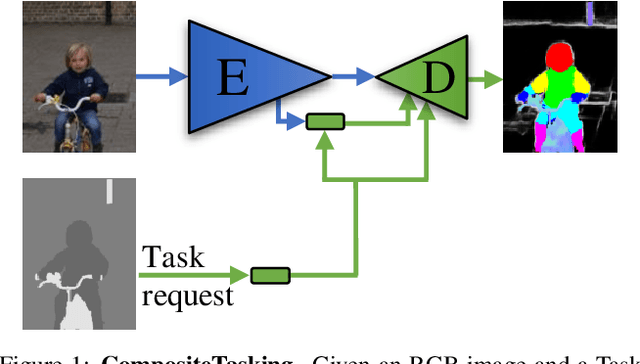
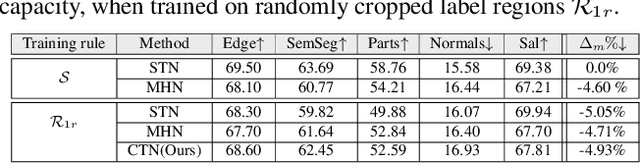
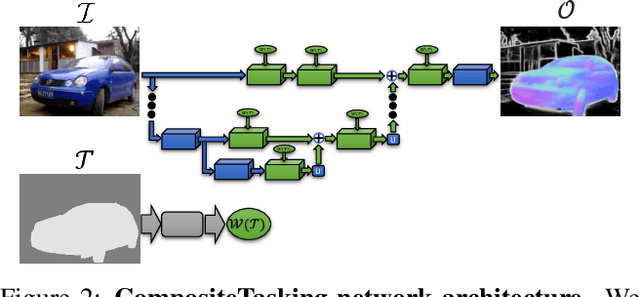
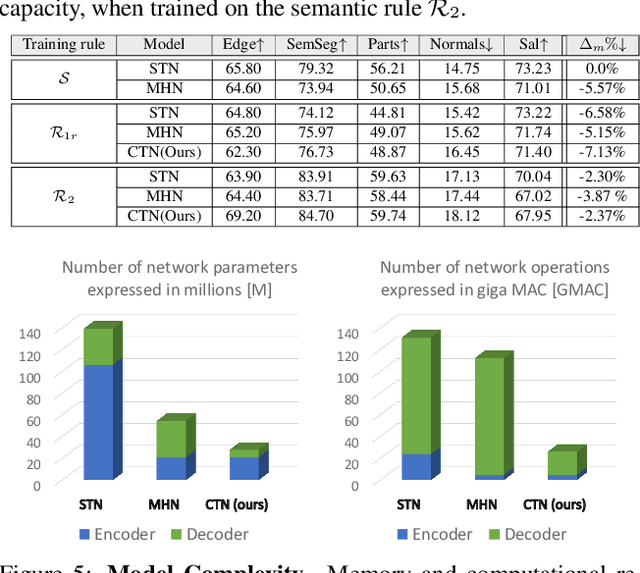
We define the concept of CompositeTasking as the fusion of multiple, spatially distributed tasks, for various aspects of image understanding. Learning to perform spatially distributed tasks is motivated by the frequent availability of only sparse labels across tasks, and the desire for a compact multi-tasking network. To facilitate CompositeTasking, we introduce a novel task conditioning model -- a single encoder-decoder network that performs multiple, spatially varying tasks at once. The proposed network takes a pair of an image and a set of pixel-wise dense tasks as inputs, and makes the task related predictions for each pixel, which includes the decision of applying which task where. As to the latter, we learn the composition of tasks that needs to be performed according to some CompositeTasking rules. It not only offers us a compact network for multi-tasking, but also allows for task-editing. The strength of the proposed method is demonstrated by only having to supply sparse supervision per task. The obtained results are on par with our baselines that use dense supervision and a multi-headed multi-tasking design. The source code will be made publicly available at www.github.com/nikola3794/composite-tasking .
Convex Relaxations for Consensus and Non-Minimal Problems in 3D Vision
Sep 26, 2019
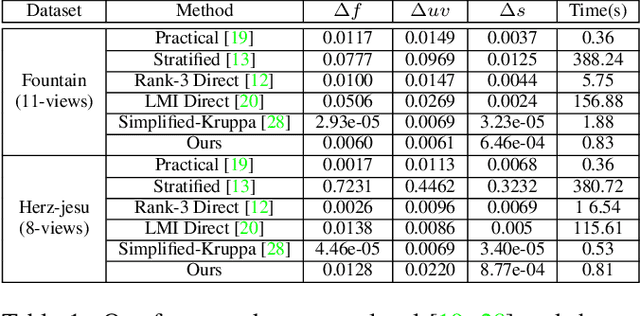
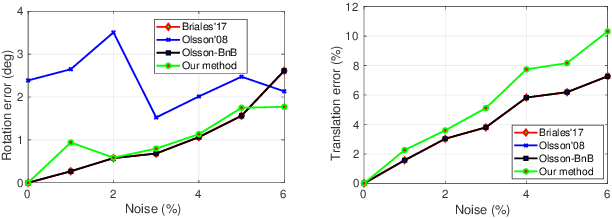
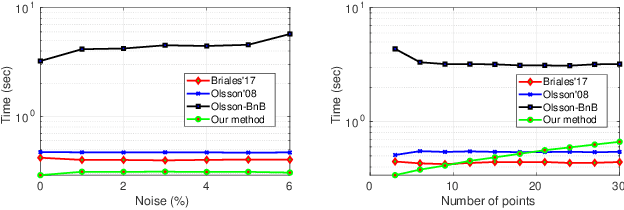
In this paper, we formulate a generic non-minimal solver using the existing tools of Polynomials Optimization Problems (POP) from computational algebraic geometry. The proposed method exploits the well known Shor's or Lasserre's relaxations, whose theoretical aspects are also discussed. Notably, we further exploit the POP formulation of non-minimal solver also for the generic consensus maximization problems in 3D vision. Our framework is simple and straightforward to implement, which is also supported by three diverse applications in 3D vision, namely rigid body transformation estimation, Non-Rigid Structure-from-Motion (NRSfM), and camera autocalibration. In all three cases, both non-minimal and consensus maximization are tested, which are also compared against the state-of-the-art methods. Our results are competitive to the compared methods, and are also coherent with our theoretical analysis. The main contribution of this paper is the claim that a good approximate solution for many polynomial problems involved in 3D vision can be obtained using the existing theory of numerical computational algebra. This claim leads us to reason about why many relaxed methods in 3D vision behave so well? And also allows us to offer a generic relaxed solver in a rather straightforward way. We further show that the convex relaxation of these polynomials can easily be used for maximizing consensus in a deterministic manner. We support our claim using several experiments for aforementioned three diverse problems in 3D vision.