 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChorus: Multi-Teacher Pretraining for Holistic 3D Gaussian Scene Encoding
Dec 22, 2025While 3DGS has emerged as a high-fidelity scene representation, encoding rich, general-purpose features directly from its primitives remains under-explored. We address this gap by introducing Chorus, a multi-teacher pretraining framework that learns a holistic feed-forward 3D Gaussian Splatting (3DGS) scene encoder by distilling complementary signals from 2D foundation models. Chorus employs a shared 3D encoder and teacher-specific projectors to learn from language-aligned, generalist, and object-aware teachers, encouraging a shared embedding space that captures signals from high-level semantics to fine-grained structure. We evaluate Chorus on a wide range of tasks: open-vocabulary semantic and instance segmentation, linear and decoder probing, as well as data-efficient supervision. Besides 3DGS, we also test Chorus on several benchmarks that only support point clouds by pretraining a variant using only Gaussians' centers, colors, estimated normals as inputs. Interestingly, this encoder shows strong transfer and outperforms the point clouds baseline while using 39.9 times fewer training scenes. Finally, we propose a render-and-distill adaptation that facilitates out-of-domain finetuning. Our code and model will be released upon publication.
SceneSplat++: A Large Dataset and Comprehensive Benchmark for Language Gaussian Splatting
Jun 10, 20253D Gaussian Splatting (3DGS) serves as a highly performant and efficient encoding of scene geometry, appearance, and semantics. Moreover, grounding language in 3D scenes has proven to be an effective strategy for 3D scene understanding. Current Language Gaussian Splatting line of work fall into three main groups: (i) per-scene optimization-based, (ii) per-scene optimization-free, and (iii) generalizable approach. However, most of them are evaluated only on rendered 2D views of a handful of scenes and viewpoints close to the training views, limiting ability and insight into holistic 3D understanding. To address this gap, we propose the first large-scale benchmark that systematically assesses these three groups of methods directly in 3D space, evaluating on 1060 scenes across three indoor datasets and one outdoor dataset. Benchmark results demonstrate a clear advantage of the generalizable paradigm, particularly in relaxing the scene-specific limitation, enabling fast feed-forward inference on novel scenes, and achieving superior segmentation performance. We further introduce GaussianWorld-49K a carefully curated 3DGS dataset comprising around 49K diverse indoor and outdoor scenes obtained from multiple sources, with which we demonstrate the generalizable approach could harness strong data priors. Our codes, benchmark, and datasets will be made public to accelerate research in generalizable 3DGS scene understanding.
G-MEMP: Gaze-Enhanced Multimodal Ego-Motion Prediction in Driving
Dec 13, 2023Understanding the decision-making process of drivers is one of the keys to ensuring road safety. While the driver intent and the resulting ego-motion trajectory are valuable in developing driver-assistance systems, existing methods mostly focus on the motions of other vehicles. In contrast, we focus on inferring the ego trajectory of a driver's vehicle using their gaze data. For this purpose, we first collect a new dataset, GEM, which contains high-fidelity ego-motion videos paired with drivers' eye-tracking data and GPS coordinates. Next, we develop G-MEMP, a novel multimodal ego-trajectory prediction network that combines GPS and video input with gaze data. We also propose a new metric called Path Complexity Index (PCI) to measure the trajectory complexity. We perform extensive evaluations of the proposed method on both GEM and DR(eye)VE, an existing benchmark dataset. The results show that G-MEMP significantly outperforms state-of-the-art methods in both benchmarks. Furthermore, ablation studies demonstrate over 20% improvement in average displacement using gaze data, particularly in challenging driving scenarios with a high PCI. The data, code, and models can be found at https://eth-ait.github.io/g-memp/.
Model-aware 3D Eye Gaze from Weak and Few-shot Supervisions
Nov 20, 2023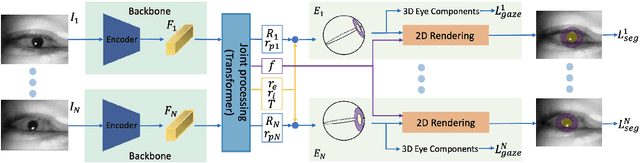
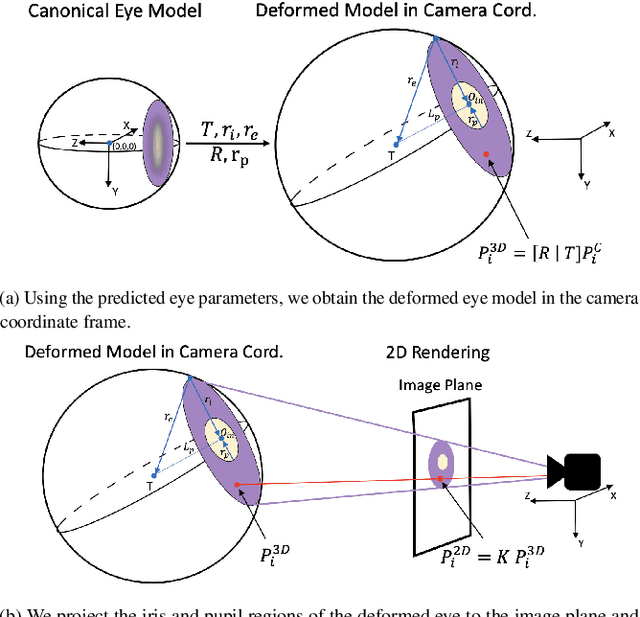
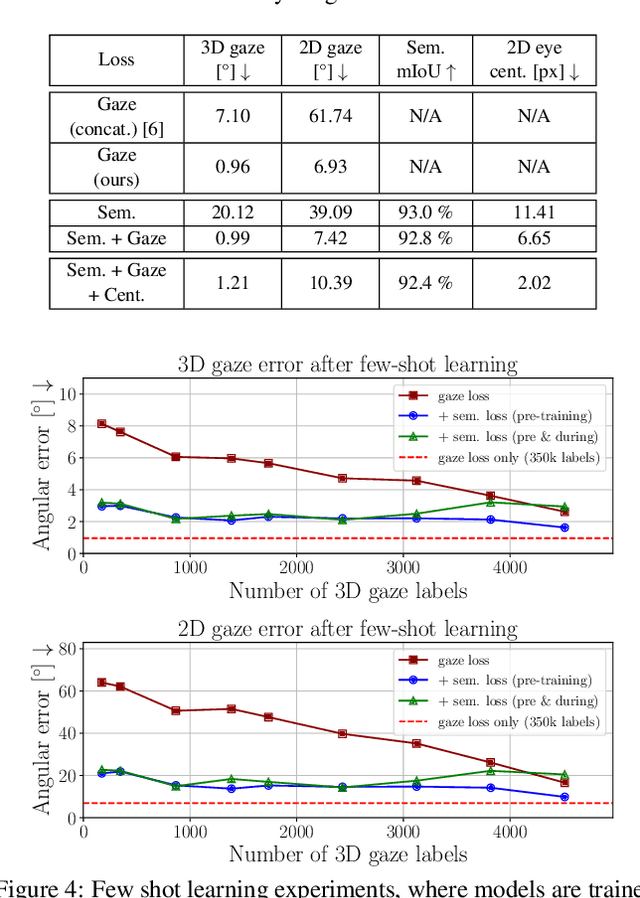
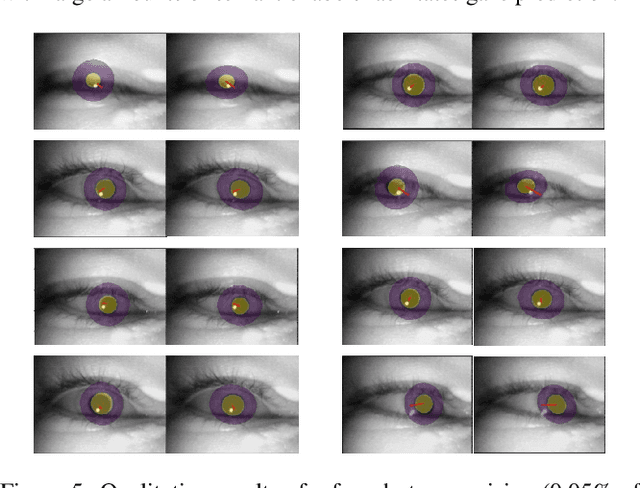
The task of predicting 3D eye gaze from eye images can be performed either by (a) end-to-end learning for image-to-gaze mapping or by (b) fitting a 3D eye model onto images. The former case requires 3D gaze labels, while the latter requires eye semantics or landmarks to facilitate the model fitting. Although obtaining eye semantics and landmarks is relatively easy, fitting an accurate 3D eye model on them remains to be very challenging due to its ill-posed nature in general. On the other hand, obtaining large-scale 3D gaze data is cumbersome due to the required hardware setups and computational demands. In this work, we propose to predict 3D eye gaze from weak supervision of eye semantic segmentation masks and direct supervision of a few 3D gaze vectors. The proposed method combines the best of both worlds by leveraging large amounts of weak annotations--which are easy to obtain, and only a few 3D gaze vectors--which alleviate the difficulty of fitting 3D eye models on the semantic segmentation of eye images. Thus, the eye gaze vectors, used in the model fitting, are directly supervised using the few-shot gaze labels. Additionally, we propose a transformer-based network architecture, that serves as a solid baseline for our improvements. Our experiments in diverse settings illustrate the significant benefits of the proposed method, achieving about 5 degrees lower angular gaze error over the baseline, when only 0.05% 3D annotations of the training images are used. The source code is available at https://github.com/dimitris-christodoulou57/Model-aware_3D_Eye_Gaze.
Neural Radiance Fields for Manhattan Scenes with Unknown Manhattan Frame
Dec 02, 2022



Novel view synthesis and 3D modeling using implicit neural field representation are shown to be very effective for calibrated multi-view cameras. Such representations are known to benefit from additional geometric and semantic supervision. Most existing methods that exploit additional supervision require dense pixel-wise labels or localized scene priors. These methods cannot benefit from high-level vague scene priors provided in terms of scenes' descriptions. In this work, we aim to leverage the geometric prior of Manhattan scenes to improve the implicit neural radiance field representations. More precisely, we assume that only the knowledge of the scene (under investigation) being Manhattan is known - with no additional information whatsoever - with an unknown Manhattan coordinate frame. Such high-level prior is then used to self-supervise the surface normals derived explicitly in the implicit neural fields. Our modeling allows us to group the derived normals, followed by exploiting their orthogonality constraints for self-supervision. Our exhaustive experiments on datasets of diverse indoor scenes demonstrate the significant benefit of the proposed method over the established baselines.
Gradient Obfuscation Checklist Test Gives a False Sense of Security
Jun 03, 2022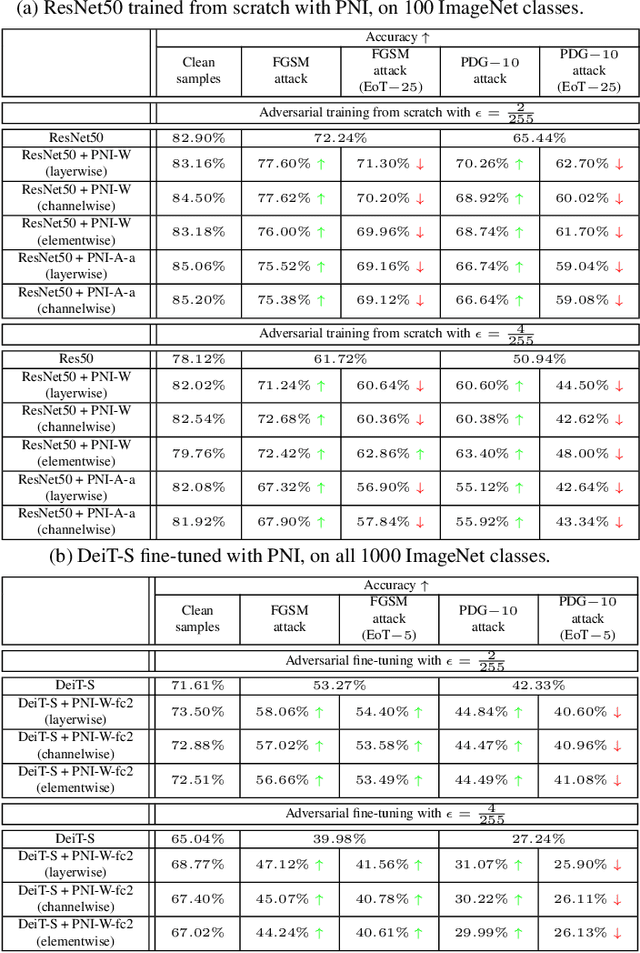
One popular group of defense techniques against adversarial attacks is based on injecting stochastic noise into the network. The main source of robustness of such stochastic defenses however is often due to the obfuscation of the gradients, offering a false sense of security. Since most of the popular adversarial attacks are optimization-based, obfuscated gradients reduce their attacking ability, while the model is still susceptible to stronger or specifically tailored adversarial attacks. Recently, five characteristics have been identified, which are commonly observed when the improvement in robustness is mainly caused by gradient obfuscation. It has since become a trend to use these five characteristics as a sufficient test, to determine whether or not gradient obfuscation is the main source of robustness. However, these characteristics do not perfectly characterize all existing cases of gradient obfuscation, and therefore can not serve as a basis for a conclusive test. In this work, we present a counterexample, showing this test is not sufficient for concluding that gradient obfuscation is not the main cause of improvements in robustness.
Spatially Multi-conditional Image Generation
Mar 25, 2022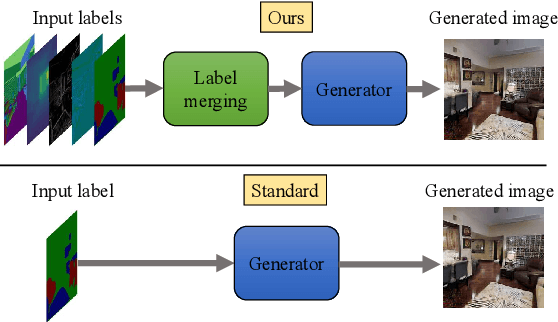


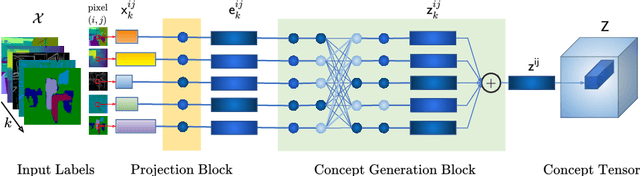
In most scenarios, conditional image generation can be thought of as an inversion of the image understanding process. Since generic image understanding involves the solving of multiple tasks, it is natural to aim at the generation of images via multi-conditioning. However, multi-conditional image generation is a very challenging problem due to the heterogeneity and the sparsity of the (in practice) available conditioning labels. In this work, we propose a novel neural architecture to address the problem of heterogeneity and sparsity of the spatially multi-conditional labels. Our choice of spatial conditioning, such as by semantics and depth, is driven by the promise it holds for better control of the image generation process. The proposed method uses a transformer-like architecture operating pixel-wise, which receives the available labels as input tokens to merge them in a learned homogeneous space of labels. The merged labels are then used for image generation via conditional generative adversarial training. In this process, the sparsity of the labels is handled by simply dropping the input tokens corresponding to the missing labels at the desired locations, thanks to the proposed pixel-wise operating architecture. Our experiments on three benchmark datasets demonstrate the clear superiority of our method over the state-of-the-art and the compared baselines.
Stochastic Layers in Vision Transformers
Dec 30, 2021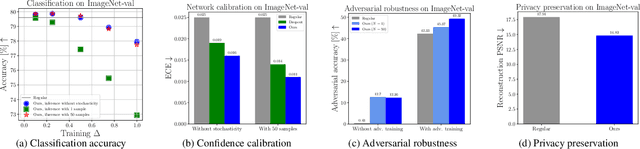
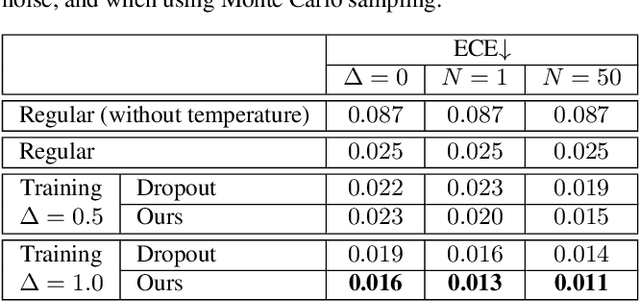

We introduce fully stochastic layers in vision transformers, without causing any severe drop in performance. The additional stochasticity boosts the robustness of visual features and strengthens privacy. In this process, linear layers with fully stochastic parameters are used, both during training and inference, to transform the feature activations of each multilayer perceptron. Such stochastic linear operations preserve the topological structure, formed by the set of tokens passing through the shared multilayer perceptron. This operation encourages the learning of the recognition task to rely on the topological structures of the tokens, instead of their values, which in turn offers the desired robustness and privacy of the visual features. In this paper, we use our features for three different applications, namely, adversarial robustness, network calibration, and feature privacy. Our features offer exciting results on those tasks. Furthermore, we showcase an experimental setup for federated and transfer learning, where the vision transformers with stochastic layers are again shown to be well behaved. Our source code will be made publicly available.
Boosting Crowd Counting with Transformers
May 23, 2021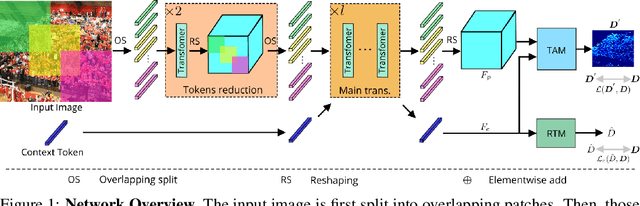
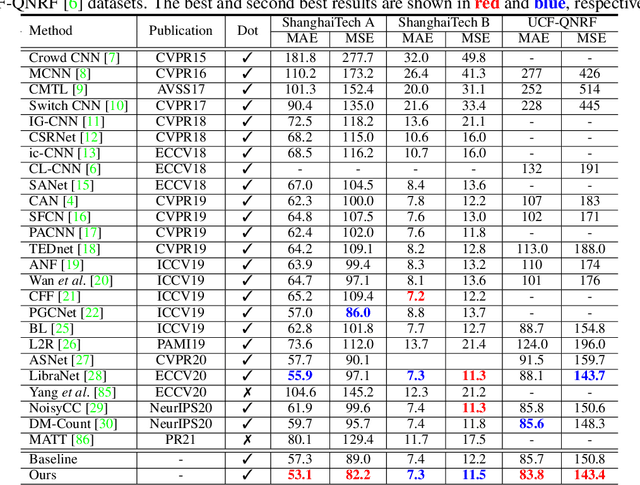
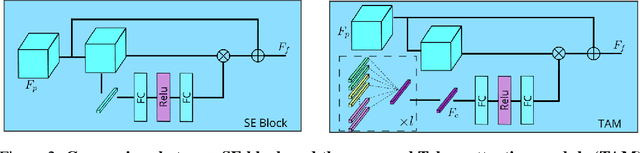
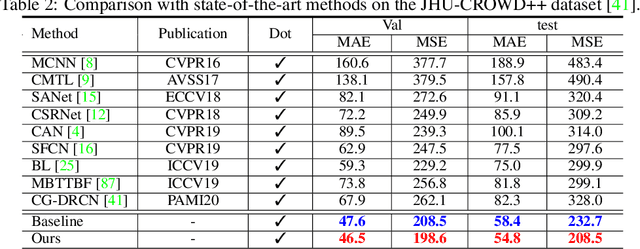
Significant progress on the crowd counting problem has been achieved by integrating larger context into convolutional neural networks (CNNs). This indicates that global scene context is essential, despite the seemingly bottom-up nature of the problem. This may be explained by the fact that context knowledge can adapt and improve local feature extraction to a given scene. In this paper, we therefore investigate the role of global context for crowd counting. Specifically, a pure transformer is used to extract features with global information from overlapping image patches. Inspired by classification, we add a context token to the input sequence, to facilitate information exchange with tokens corresponding to image patches throughout transformer layers. Due to the fact that transformers do not explicitly model the tried-and-true channel-wise interactions, we propose a token-attention module (TAM) to recalibrate encoded features through channel-wise attention informed by the context token. Beyond that, it is adopted to predict the total person count of the image through regression-token module (RTM). Extensive experiments demonstrate that our method achieves state-of-the-art performance on various datasets, including ShanghaiTech, UCF-QNRF, JHU-CROWD++ and NWPU. On the large-scale JHU-CROWD++ dataset, our method improves over the previous best results by 26.9% and 29.9% in terms of MAE and MSE, respectively.
CompositeTasking: Understanding Images by Spatial Composition of Tasks
Dec 16, 2020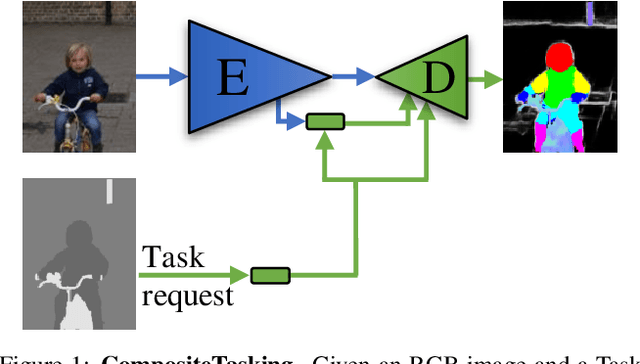
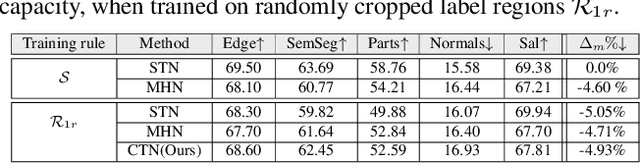
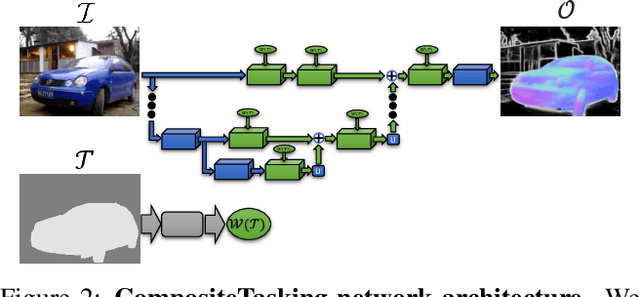
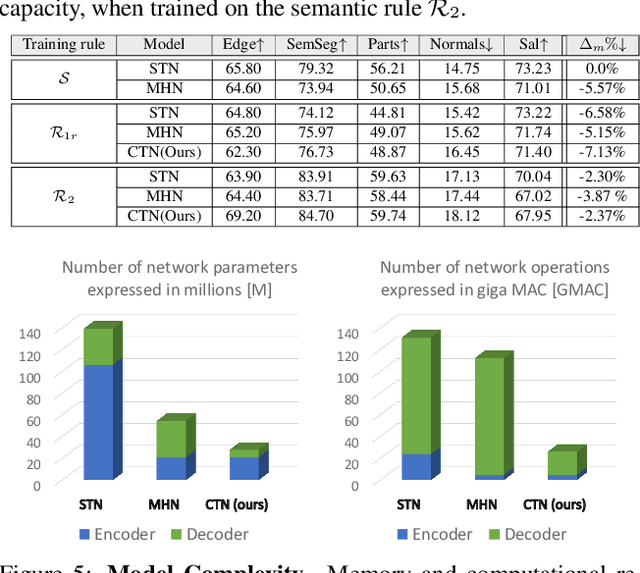
We define the concept of CompositeTasking as the fusion of multiple, spatially distributed tasks, for various aspects of image understanding. Learning to perform spatially distributed tasks is motivated by the frequent availability of only sparse labels across tasks, and the desire for a compact multi-tasking network. To facilitate CompositeTasking, we introduce a novel task conditioning model -- a single encoder-decoder network that performs multiple, spatially varying tasks at once. The proposed network takes a pair of an image and a set of pixel-wise dense tasks as inputs, and makes the task related predictions for each pixel, which includes the decision of applying which task where. As to the latter, we learn the composition of tasks that needs to be performed according to some CompositeTasking rules. It not only offers us a compact network for multi-tasking, but also allows for task-editing. The strength of the proposed method is demonstrated by only having to supply sparse supervision per task. The obtained results are on par with our baselines that use dense supervision and a multi-headed multi-tasking design. The source code will be made publicly available at www.github.com/nikola3794/composite-tasking .