 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChorus: Multi-Teacher Pretraining for Holistic 3D Gaussian Scene Encoding
Dec 22, 2025While 3DGS has emerged as a high-fidelity scene representation, encoding rich, general-purpose features directly from its primitives remains under-explored. We address this gap by introducing Chorus, a multi-teacher pretraining framework that learns a holistic feed-forward 3D Gaussian Splatting (3DGS) scene encoder by distilling complementary signals from 2D foundation models. Chorus employs a shared 3D encoder and teacher-specific projectors to learn from language-aligned, generalist, and object-aware teachers, encouraging a shared embedding space that captures signals from high-level semantics to fine-grained structure. We evaluate Chorus on a wide range of tasks: open-vocabulary semantic and instance segmentation, linear and decoder probing, as well as data-efficient supervision. Besides 3DGS, we also test Chorus on several benchmarks that only support point clouds by pretraining a variant using only Gaussians' centers, colors, estimated normals as inputs. Interestingly, this encoder shows strong transfer and outperforms the point clouds baseline while using 39.9 times fewer training scenes. Finally, we propose a render-and-distill adaptation that facilitates out-of-domain finetuning. Our code and model will be released upon publication.
Multimodal Spatial Reasoning in the Large Model Era: A Survey and Benchmarks
Oct 29, 2025Humans possess spatial reasoning abilities that enable them to understand spaces through multimodal observations, such as vision and sound. Large multimodal reasoning models extend these abilities by learning to perceive and reason, showing promising performance across diverse spatial tasks. However, systematic reviews and publicly available benchmarks for these models remain limited. In this survey, we provide a comprehensive review of multimodal spatial reasoning tasks with large models, categorizing recent progress in multimodal large language models (MLLMs) and introducing open benchmarks for evaluation. We begin by outlining general spatial reasoning, focusing on post-training techniques, explainability, and architecture. Beyond classical 2D tasks, we examine spatial relationship reasoning, scene and layout understanding, as well as visual question answering and grounding in 3D space. We also review advances in embodied AI, including vision-language navigation and action models. Additionally, we consider emerging modalities such as audio and egocentric video, which contribute to novel spatial understanding through new sensors. We believe this survey establishes a solid foundation and offers insights into the growing field of multimodal spatial reasoning. Updated information about this survey, codes and implementation of the open benchmarks can be found at https://github.com/zhengxuJosh/Awesome-Spatial-Reasoning.
SceneSplat++: A Large Dataset and Comprehensive Benchmark for Language Gaussian Splatting
Jun 10, 20253D Gaussian Splatting (3DGS) serves as a highly performant and efficient encoding of scene geometry, appearance, and semantics. Moreover, grounding language in 3D scenes has proven to be an effective strategy for 3D scene understanding. Current Language Gaussian Splatting line of work fall into three main groups: (i) per-scene optimization-based, (ii) per-scene optimization-free, and (iii) generalizable approach. However, most of them are evaluated only on rendered 2D views of a handful of scenes and viewpoints close to the training views, limiting ability and insight into holistic 3D understanding. To address this gap, we propose the first large-scale benchmark that systematically assesses these three groups of methods directly in 3D space, evaluating on 1060 scenes across three indoor datasets and one outdoor dataset. Benchmark results demonstrate a clear advantage of the generalizable paradigm, particularly in relaxing the scene-specific limitation, enabling fast feed-forward inference on novel scenes, and achieving superior segmentation performance. We further introduce GaussianWorld-49K a carefully curated 3DGS dataset comprising around 49K diverse indoor and outdoor scenes obtained from multiple sources, with which we demonstrate the generalizable approach could harness strong data priors. Our codes, benchmark, and datasets will be made public to accelerate research in generalizable 3DGS scene understanding.
CityLoc: 6 DoF Localization of Text Descriptions in Large-Scale Scenes with Gaussian Representation
Jan 15, 2025Localizing text descriptions in large-scale 3D scenes is inherently an ambiguous task. This nonetheless arises while describing general concepts, e.g. all traffic lights in a city. To facilitate reasoning based on such concepts, text localization in the form of distribution is required. In this paper, we generate the distribution of the camera poses conditioned upon the textual description. To facilitate such generation, we propose a diffusion-based architecture that conditionally diffuses the noisy 6DoF camera poses to their plausible locations. The conditional signals are derived from the text descriptions, using the pre-trained text encoders. The connection between text descriptions and pose distribution is established through pretrained Vision-Language-Model, i.e. CLIP. Furthermore, we demonstrate that the candidate poses for the distribution can be further refined by rendering potential poses using 3D Gaussian splatting, guiding incorrectly posed samples towards locations that better align with the textual description, through visual reasoning. We demonstrate the effectiveness of our method by comparing it with both standard retrieval methods and learning-based approaches. Our proposed method consistently outperforms these baselines across all five large-scale datasets. Our source code and dataset will be made publicly available.
Spectrally Pruned Gaussian Fields with Neural Compensation
May 01, 2024Recently, 3D Gaussian Splatting, as a novel 3D representation, has garnered attention for its fast rendering speed and high rendering quality. However, this comes with high memory consumption, e.g., a well-trained Gaussian field may utilize three million Gaussian primitives and over 700 MB of memory. We credit this high memory footprint to the lack of consideration for the relationship between primitives. In this paper, we propose a memory-efficient Gaussian field named SUNDAE with spectral pruning and neural compensation. On one hand, we construct a graph on the set of Gaussian primitives to model their relationship and design a spectral down-sampling module to prune out primitives while preserving desired signals. On the other hand, to compensate for the quality loss of pruning Gaussians, we exploit a lightweight neural network head to mix splatted features, which effectively compensates for quality losses while capturing the relationship between primitives in its weights. We demonstrate the performance of SUNDAE with extensive results. For example, SUNDAE can achieve 26.80 PSNR at 145 FPS using 104 MB memory while the vanilla Gaussian splatting algorithm achieves 25.60 PSNR at 160 FPS using 523 MB memory, on the Mip-NeRF360 dataset. Codes are publicly available at https://runyiyang.github.io/projects/SUNDAE/.
GaussianGrasper: 3D Language Gaussian Splatting for Open-vocabulary Robotic Grasping
Mar 14, 2024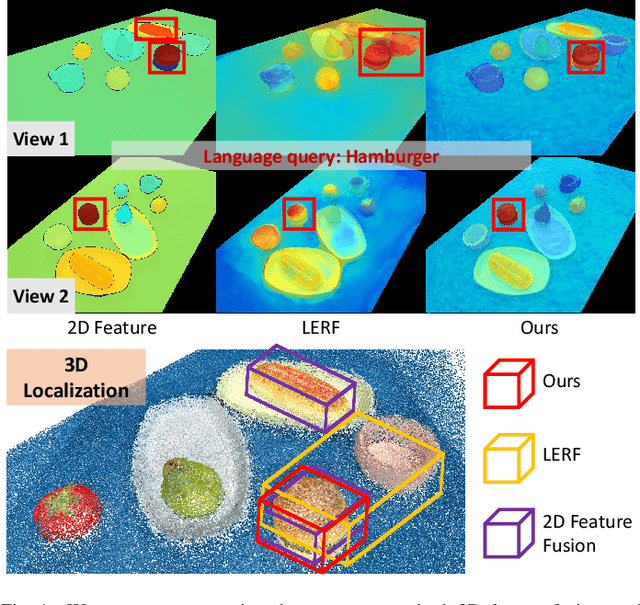
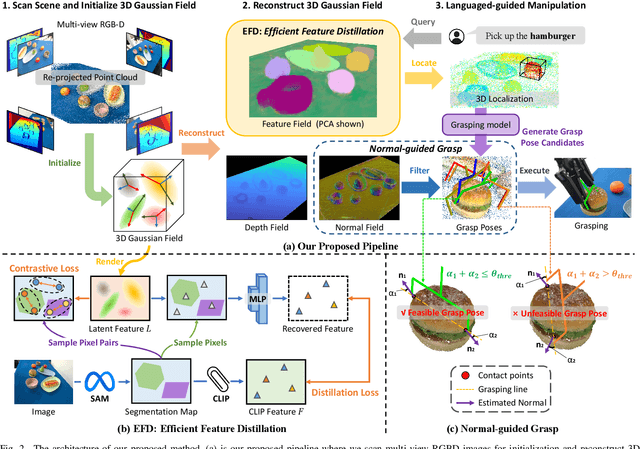
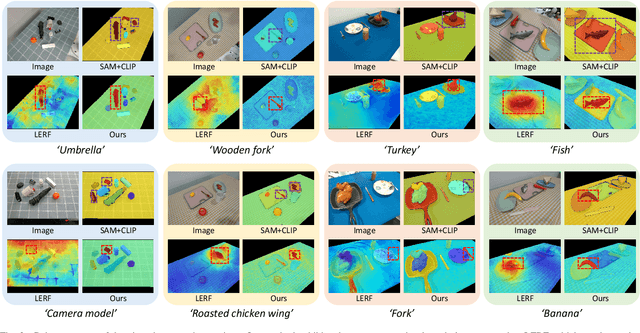

Constructing a 3D scene capable of accommodating open-ended language queries, is a pivotal pursuit, particularly within the domain of robotics. Such technology facilitates robots in executing object manipulations based on human language directives. To tackle this challenge, some research efforts have been dedicated to the development of language-embedded implicit fields. However, implicit fields (e.g. NeRF) encounter limitations due to the necessity of processing a large number of input views for reconstruction, coupled with their inherent inefficiencies in inference. Thus, we present the GaussianGrasper, which utilizes 3D Gaussian Splatting to explicitly represent the scene as a collection of Gaussian primitives. Our approach takes a limited set of RGB-D views and employs a tile-based splatting technique to create a feature field. In particular, we propose an Efficient Feature Distillation (EFD) module that employs contrastive learning to efficiently and accurately distill language embeddings derived from foundational models. With the reconstructed geometry of the Gaussian field, our method enables the pre-trained grasping model to generate collision-free grasp pose candidates. Furthermore, we propose a normal-guided grasp module to select the best grasp pose. Through comprehensive real-world experiments, we demonstrate that GaussianGrasper enables robots to accurately query and grasp objects with language instructions, providing a new solution for language-guided manipulation tasks. Data and codes can be available at https://github.com/MrSecant/GaussianGrasper.
MARS: An Instance-aware, Modular and Realistic Simulator for Autonomous Driving
Jul 27, 2023Nowadays, autonomous cars can drive smoothly in ordinary cases, and it is widely recognized that realistic sensor simulation will play a critical role in solving remaining corner cases by simulating them. To this end, we propose an autonomous driving simulator based upon neural radiance fields (NeRFs). Compared with existing works, ours has three notable features: (1) Instance-aware. Our simulator models the foreground instances and background environments separately with independent networks so that the static (e.g., size and appearance) and dynamic (e.g., trajectory) properties of instances can be controlled separately. (2) Modular. Our simulator allows flexible switching between different modern NeRF-related backbones, sampling strategies, input modalities, etc. We expect this modular design to boost academic progress and industrial deployment of NeRF-based autonomous driving simulation. (3) Realistic. Our simulator set new state-of-the-art photo-realism results given the best module selection. Our simulator will be open-sourced while most of our counterparts are not. Project page: https://open-air-sun.github.io/mars/.
AsyncNeRF: Learning Large-scale Radiance Fields from Asynchronous RGB-D Sequences with Time-Pose Function
Nov 14, 2022Large-scale radiance fields are promising mapping tools for smart transportation applications like autonomous driving or drone delivery. But for large-scale scenes, compact synchronized RGB-D cameras are not applicable due to limited sensing range, and using separate RGB and depth sensors inevitably leads to unsynchronized sequences. Inspired by the recent success of self-calibrating radiance field training methods that do not require known intrinsic or extrinsic parameters, we propose the first solution that self-calibrates the mismatch between RGB and depth frames. We leverage the important domain-specific fact that RGB and depth frames are actually sampled from the same trajectory and develop a novel implicit network called the time-pose function. Combining it with a large-scale radiance field leads to an architecture that cascades two implicit representation networks. To validate its effectiveness, we construct a diverse and photorealistic dataset that covers various RGB-D mismatch scenarios. Through a comprehensive benchmarking on this dataset, we demonstrate the flexibility of our method in different scenarios and superior performance over applicable prior counterparts. Codes, data, and models will be made publicly available.
City-scale Incremental Neural Mapping with Three-layer Sampling and Panoptic Representation
Sep 28, 2022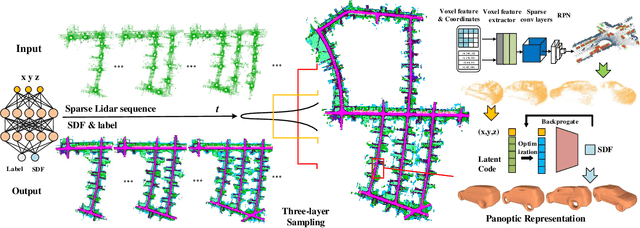

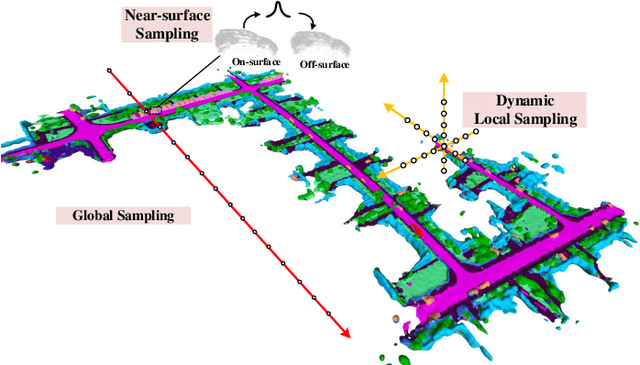

Neural implicit representations are drawing a lot of attention from the robotics community recently, as they are expressive, continuous and compact. However, city-scale incremental implicit dense mapping based on sparse LiDAR input is still an under-explored challenge. To this end,we successfully build the first city-scale incremental neural mapping system with a panoptic representation that consists of both environment-level and instance-level modelling. Given a stream of sparse LiDAR point cloud, it maintains a dynamic generative model that maps 3D coordinates to signed distance field (SDF) values. To address the difficulty of representing geometric information at different levels in city-scale space, we propose a tailored three-layer sampling strategy to dynamically sample the global, local and near-surface domains. Meanwhile, to realize high fidelity mapping, category-specific prior is introduced to better model the geometric details, leading to a panoptic representation. We evaluate on the public SemanticKITTI dataset and demonstrate the significance of the newly proposed three-layer sampling strategy and panoptic representation, using both quantitative and qualitative results. Codes and data will be publicly available.