 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Black-Box-Optimization through Offline Q-function Learning
May 04, 2025Recent progress in Meta-Black-Box-Optimization (MetaBBO) has demonstrated that using RL to learn a meta-level policy for dynamic algorithm configuration (DAC) over an optimization task distribution could significantly enhance the performance of the low-level BBO algorithm. However, the online learning paradigms in existing works makes the efficiency of MetaBBO problematic. To address this, we propose an offline learning-based MetaBBO framework in this paper, termed Q-Mamba, to attain both effectiveness and efficiency in MetaBBO. Specifically, we first transform DAC task into long-sequence decision process. This allows us further introduce an effective Q-function decomposition mechanism to reduce the learning difficulty within the intricate algorithm configuration space. Under this setting, we propose three novel designs to meta-learn DAC policy from offline data: we first propose a novel collection strategy for constructing offline DAC experiences dataset with balanced exploration and exploitation. We then establish a decomposition-based Q-loss that incorporates conservative Q-learning to promote stable offline learning from the offline dataset. To further improve the offline learning efficiency, we equip our work with a Mamba architecture which helps long-sequence learning effectiveness and efficiency by selective state model and hardware-aware parallel scan respectively. Through extensive benchmarking, we observe that Q-Mamba achieves competitive or even superior performance to prior online/offline baselines, while significantly improving the training efficiency of existing online baselines. We provide sourcecodes of Q-Mamba at https://github.com/MetaEvo/Q-Mamba.
RoboMatrix: A Skill-centric Hierarchical Framework for Scalable Robot Task Planning and Execution in Open-World
Nov 29, 2024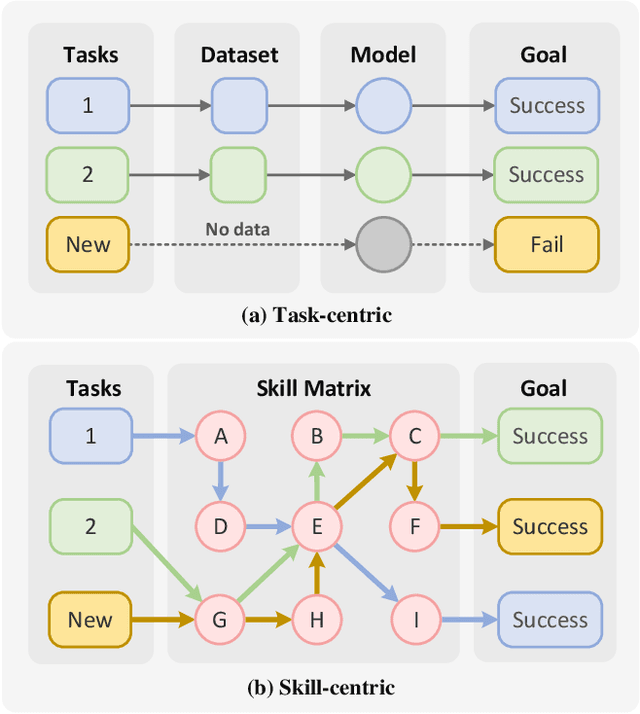

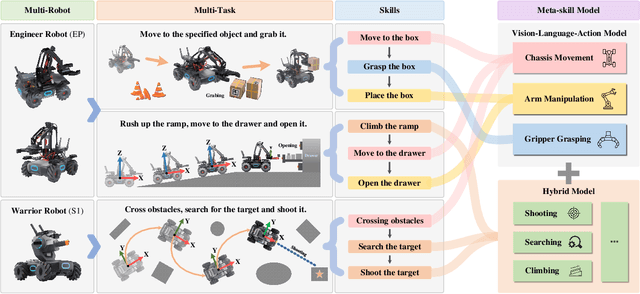

Existing policy learning methods predominantly adopt the task-centric paradigm, necessitating the collection of task data in an end-to-end manner. Consequently, the learned policy tends to fail to tackle novel tasks. Moreover, it is hard to localize the errors for a complex task with multiple stages due to end-to-end learning. To address these challenges, we propose RoboMatrix, a skill-centric and hierarchical framework for scalable task planning and execution. We first introduce a novel skill-centric paradigm that extracts the common meta-skills from different complex tasks. This allows for the capture of embodied demonstrations through a kill-centric approach, enabling the completion of open-world tasks by combining learned meta-skills. To fully leverage meta-skills, we further develop a hierarchical framework that decouples complex robot tasks into three interconnected layers: (1) a high-level modular scheduling layer; (2) a middle-level skill layer; and (3) a low-level hardware layer. Experimental results illustrate that our skill-centric and hierarchical framework achieves remarkable generalization performance across novel objects, scenes, tasks, and embodiments. This framework offers a novel solution for robot task planning and execution in open-world scenarios. Our software and hardware are available at https://github.com/WayneMao/RoboMatrix.
Dual-frame Fluid Motion Estimation with Test-time Optimization and Zero-divergence Loss
Oct 15, 2024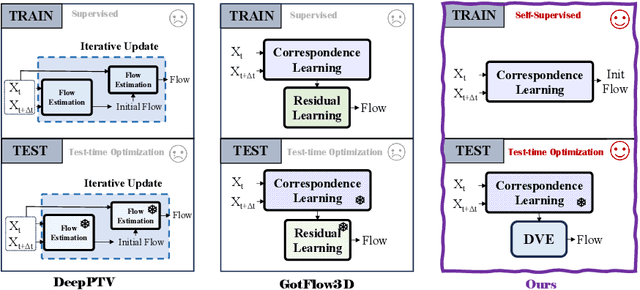
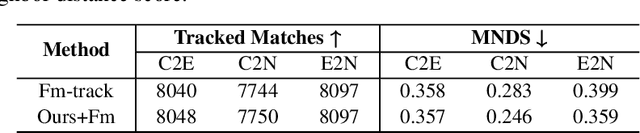
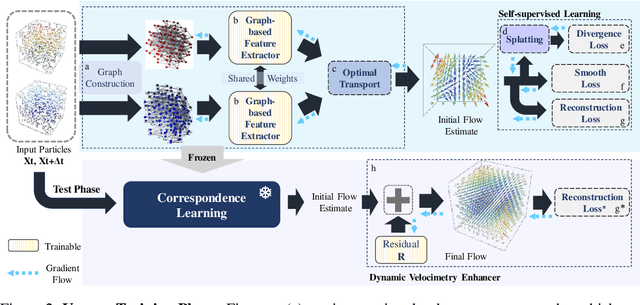
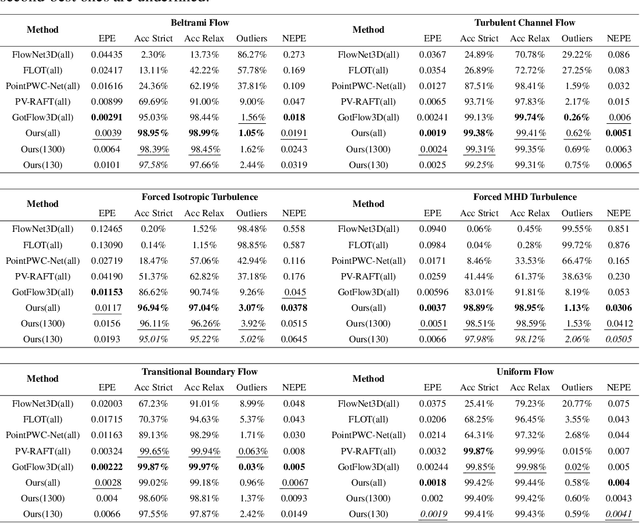
3D particle tracking velocimetry (PTV) is a key technique for analyzing turbulent flow, one of the most challenging computational problems of our century. At the core of 3D PTV is the dual-frame fluid motion estimation algorithm, which tracks particles across two consecutive frames. Recently, deep learning-based methods have achieved impressive accuracy in dual-frame fluid motion estimation; however, they heavily depend on large volumes of labeled data. In this paper, we introduce a new method that is completely self-supervised and notably outperforms its fully-supervised counterparts while requiring only 1% of the training samples (without labels) used by previous methods. Our method features a novel zero-divergence loss that is specific to the domain of turbulent flow. Inspired by the success of splat operation in high-dimensional filtering and random fields, we propose a splat-based implementation for this loss which is both efficient and effective. The self-supervised nature of our method naturally supports test-time optimization, leading to the development of a tailored Dynamic Velocimetry Enhancer (DVE) module. We demonstrate that strong cross-domain robustness is achieved through test-time optimization on unseen leave-one-out synthetic domains and real physical/biological domains. Code, data and models are available at https://github.com/Forrest-110/FluidMotionNet.
Spectrally Pruned Gaussian Fields with Neural Compensation
May 01, 2024Recently, 3D Gaussian Splatting, as a novel 3D representation, has garnered attention for its fast rendering speed and high rendering quality. However, this comes with high memory consumption, e.g., a well-trained Gaussian field may utilize three million Gaussian primitives and over 700 MB of memory. We credit this high memory footprint to the lack of consideration for the relationship between primitives. In this paper, we propose a memory-efficient Gaussian field named SUNDAE with spectral pruning and neural compensation. On one hand, we construct a graph on the set of Gaussian primitives to model their relationship and design a spectral down-sampling module to prune out primitives while preserving desired signals. On the other hand, to compensate for the quality loss of pruning Gaussians, we exploit a lightweight neural network head to mix splatted features, which effectively compensates for quality losses while capturing the relationship between primitives in its weights. We demonstrate the performance of SUNDAE with extensive results. For example, SUNDAE can achieve 26.80 PSNR at 145 FPS using 104 MB memory while the vanilla Gaussian splatting algorithm achieves 25.60 PSNR at 160 FPS using 523 MB memory, on the Mip-NeRF360 dataset. Codes are publicly available at https://runyiyang.github.io/projects/SUNDAE/.
Block-Map-Based Localization in Large-Scale Environment
Apr 28, 2024Accurate localization is an essential technology for the flexible navigation of robots in large-scale environments. Both SLAM-based and map-based localization will increase the computing load due to the increase in map size, which will affect downstream tasks such as robot navigation and services. To this end, we propose a localization system based on Block Maps (BMs) to reduce the computational load caused by maintaining large-scale maps. Firstly, we introduce a method for generating block maps and the corresponding switching strategies, ensuring that the robot can estimate the state in large-scale environments by loading local map information. Secondly, global localization according to Branch-and-Bound Search (BBS) in the 3D map is introduced to provide the initial pose. Finally, a graph-based optimization method is adopted with a dynamic sliding window that determines what factors are being marginalized whether a robot is exposed to a BM or switching to another one, which maintains the accuracy and efficiency of pose tracking. Comparison experiments are performed on publicly available large-scale datasets. Results show that the proposed method can track the robot pose even though the map scale reaches more than 6 kilometers, while efficient and accurate localization is still guaranteed on NCLT and M2DGR.
P-MapNet: Far-seeing Map Generator Enhanced by both SDMap and HDMap Priors
Mar 29, 2024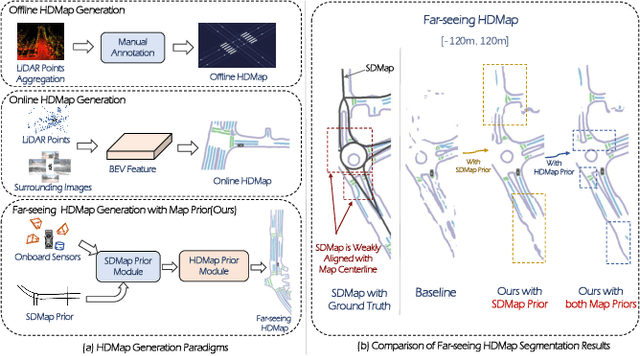
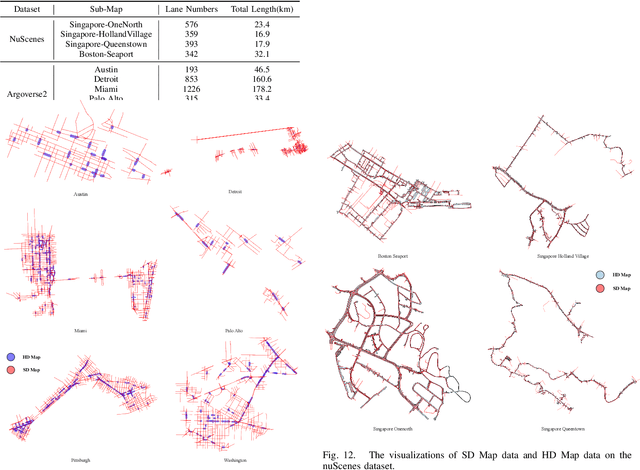
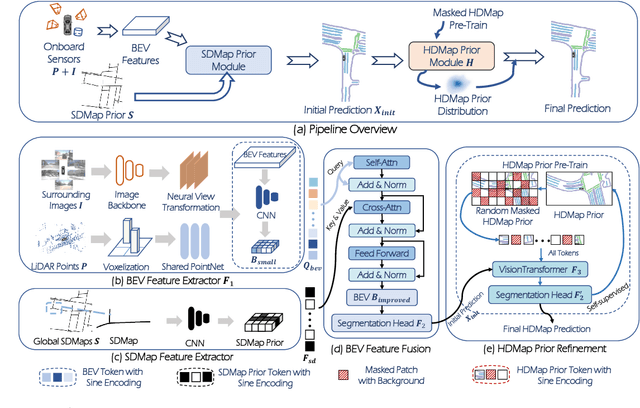
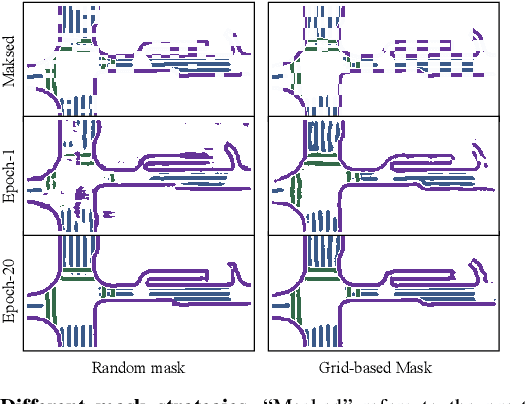
Autonomous vehicles are gradually entering city roads today, with the help of high-definition maps (HDMaps). However, the reliance on HDMaps prevents autonomous vehicles from stepping into regions without this expensive digital infrastructure. This fact drives many researchers to study online HDMap generation algorithms, but the performance of these algorithms at far regions is still unsatisfying. We present P-MapNet, in which the letter P highlights the fact that we focus on incorporating map priors to improve model performance. Specifically, we exploit priors in both SDMap and HDMap. On one hand, we extract weakly aligned SDMap from OpenStreetMap, and encode it as an additional conditioning branch. Despite the misalignment challenge, our attention-based architecture adaptively attends to relevant SDMap skeletons and significantly improves performance. On the other hand, we exploit a masked autoencoder to capture the prior distribution of HDMap, which can serve as a refinement module to mitigate occlusions and artifacts. We benchmark on the nuScenes and Argoverse2 datasets. Through comprehensive experiments, we show that: (1) our SDMap prior can improve online map generation performance, using both rasterized (by up to $+18.73$ $\rm mIoU$) and vectorized (by up to $+8.50$ $\rm mAP$) output representations. (2) our HDMap prior can improve map perceptual metrics by up to $6.34\%$. (3) P-MapNet can be switched into different inference modes that covers different regions of the accuracy-efficiency trade-off landscape. (4) P-MapNet is a far-seeing solution that brings larger improvements on longer ranges. Codes and models are publicly available at https://jike5.github.io/P-MapNet.