 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKGEdit: Ambiguity-Aware Knowledge Graphs for Training-Free Precise Video Generation and Editing
May 28, 2026In recent years, training-free video generation has progressed remarkably. However, when handling complex textual instructions, existing methods still suffer from semantic ambiguity, incorrect concept binding, and cross-frame inconsistency. To address these issues, we propose KGEdit, a structured semantic control framework for text-to-video (T2V) diffusion models. Specifically, we first construct an ambiguity-aware knowledge graph (AAKG) to disentangle and disambiguate the input prompt, converting it into four types of structured semantics: identity, relation, attribute, and negative constraints. We then design a structured semantic injection module (SSIM) to inject these semantic signals into key layers of the diffusion Transformer, enabling fine-grained semantic control. In addition, we introduce a temporal-aware semantic control (TASC) module that dynamically schedules semantic objectives according to the stage-wise characteristics of the denoising process, further improving semantic alignment and temporal consistency. Experiments show that KGEdit outperforms existing methods in editing precision and temporal stability, while offering higher efficiency and controllability in text-driven interaction scenarios.
AndroidDaily: A Verifiable Benchmark for Mobile GUI Agents on Real-World Closed-Source Applications
May 26, 2026The rapid development of GUI foundation models and mobile GUI agents has spurred numerous evaluation benchmarks, yet most rely on simulated environments or open-source applications, leaving real-world closed-source applications largely unevaluated. The core difficulty is that closed-source applications do not expose internal states, making traditional automatic verification inapplicable. To bridge this gap, we introduce AndroidDaily, a large-scale benchmark comprising 350 realistic daily-use tasks across 94 high-frequency Android applications spanning transportation, shopping, local services, entertainment, content creation, social media, and everyday utilities. To enable automatic and verifiable assessment in these opaque environments, we propose Guideline-grounded Reviewer for Automatic Diagnostic Evaluation (GRADE), a process-aware evaluator built on a three-tiered system of observable external guidelines: operational obligations, output quality, and negative constraints. GRADE tracks the agent's visual trajectory against these criteria and produces step-level diagnostic judgments, turning long-horizon, open-ended mobile interactions into verifiable evaluation without relying on hidden internal states. Experiments show that GRADE achieves 87.37\% agreement with human evaluators. The strongest model reaches a 62.0\% success rate on AndroidDaily, highlighting a substantial gap between current reasoning capabilities and practical execution in realistic mobile workflows.
Where, What, Why: Toward Explainable 3D-GS Watermarking
Mar 09, 2026As 3D Gaussian Splatting becomes the de facto representation for interactive 3D assets, robust yet imperceptible watermarking is critical. We present a representation-native framework that separates where to write from how to preserve quality. A Trio-Experts module operates directly on Gaussian primitives to derive priors for carrier selection, while a Safety and Budget Aware Gate (SBAG) allocates Gaussians to watermark carriers, optimized for bit resilience under perturbation and bitrate budgets, and to visual compensators that are insulated from watermark loss. To maintain fidelity, we introduce a channel-wise group mask that controls gradient propagation for carriers and compensators, thereby limiting Gaussian parameter updates, repairing local artifacts, and preserving high-frequency details without increasing runtime. Our design yields view-consistent watermark persistence and strong robustness against common image distortions such as compression and noise, while achieving a favorable robustness-quality trade-off compared with prior methods. In addition, decoupled finetuning provides per-Gaussian attributions that reveal where the message is carried and why those carriers are selected, enabling auditable explainability. Compared with state-of-the-art methods, our approach achieves a PSNR improvement of +0.83 dB and a bit-accuracy gain of +1.24%.
Chart Specification: Structural Representations for Incentivizing VLM Reasoning in Chart-to-Code Generation
Feb 11, 2026Vision-Language Models (VLMs) have shown promise in generating plotting code from chart images, yet achieving structural fidelity remains challenging. Existing approaches largely rely on supervised fine-tuning, encouraging surface-level token imitation rather than faithful modeling of underlying chart structure, which often leads to hallucinated or semantically inconsistent outputs. We propose Chart Specification, a structured intermediate representation that shifts training from text imitation to semantically grounded supervision. Chart Specification filters syntactic noise to construct a structurally balanced training set and supports a Spec-Align Reward that provides fine-grained, verifiable feedback on structural correctness, enabling reinforcement learning to enforce consistent plotting logic. Experiments on three public benchmarks show that our method consistently outperforms prior approaches. With only 3K training samples, we achieve strong data efficiency, surpassing leading baselines by up to 61.7% on complex benchmarks, and scaling to 4K samples establishes new state-of-the-art results across all evaluated metrics. Overall, our results demonstrate that precise structural supervision offers an efficient pathway to high-fidelity chart-to-code generation. Code and dataset are available at: https://github.com/Mighten/chart-specification-paper
Multi-Attribute guided Thermal Face Image Translation based on Latent Diffusion Model
Dec 24, 2025Modern surveillance systems increasingly rely on multi-wavelength sensors and deep neural networks to recognize faces in infrared images captured at night. However, most facial recognition models are trained on visible light datasets, leading to substantial performance degradation on infrared inputs due to significant domain shifts. Early feature-based methods for infrared face recognition proved ineffective, prompting researchers to adopt generative approaches that convert infrared images into visible light images for improved recognition. This paradigm, known as Heterogeneous Face Recognition (HFR), faces challenges such as model and modality discrepancies, leading to distortion and feature loss in generated images. To address these limitations, this paper introduces a novel latent diffusion-based model designed to generate high-quality visible face images from thermal inputs while preserving critical identity features. A multi-attribute classifier is incorporated to extract key facial attributes from visible images, mitigating feature loss during infrared-to-visible image restoration. Additionally, we propose the Self-attn Mamba module, which enhances global modeling of cross-modal features and significantly improves inference speed. Experimental results on two benchmark datasets demonstrate the superiority of our approach, achieving state-of-the-art performance in both image quality and identity preservation.
FluencyVE: Marrying Temporal-Aware Mamba with Bypass Attention for Video Editing
Dec 24, 2025Large-scale text-to-image diffusion models have achieved unprecedented success in image generation and editing. However, extending this success to video editing remains challenging. Recent video editing efforts have adapted pretrained text-to-image models by adding temporal attention mechanisms to handle video tasks. Unfortunately, these methods continue to suffer from temporal inconsistency issues and high computational overheads. In this study, we propose FluencyVE, which is a simple yet effective one-shot video editing approach. FluencyVE integrates the linear time-series module, Mamba, into a video editing model based on pretrained Stable Diffusion models, replacing the temporal attention layer. This enables global frame-level attention while reducing the computational costs. In addition, we employ low-rank approximation matrices to replace the query and key weight matrices in the causal attention, and use a weighted averaging technique during training to update the attention scores. This approach significantly preserves the generative power of the text-to-image model while effectively reducing the computational burden. Experiments and analyses demonstrate promising results in editing various attributes, subjects, and locations in real-world videos.
DM$^3$Net: Dual-Camera Super-Resolution via Domain Modulation and Multi-scale Matching
Jun 08, 2025Dual-camera super-resolution is highly practical for smartphone photography that primarily super-resolve the wide-angle images using the telephoto image as a reference. In this paper, we propose DM$^3$Net, a novel dual-camera super-resolution network based on Domain Modulation and Multi-scale Matching. To bridge the domain gap between the high-resolution domain and the degraded domain, we learn two compressed global representations from image pairs corresponding to the two domains. To enable reliable transfer of high-frequency structural details from the reference image, we design a multi-scale matching module that conducts patch-level feature matching and retrieval across multiple receptive fields to improve matching accuracy and robustness. Moreover, we also introduce Key Pruning to achieve a significant reduction in memory usage and inference time with little model performance sacrificed. Experimental results on three real-world datasets demonstrate that our DM$^3$Net outperforms the state-of-the-art approaches.
PADriver: Towards Personalized Autonomous Driving
May 08, 2025In this paper, we propose PADriver, a novel closed-loop framework for personalized autonomous driving (PAD). Built upon Multi-modal Large Language Model (MLLM), PADriver takes streaming frames and personalized textual prompts as inputs. It autoaggressively performs scene understanding, danger level estimation and action decision. The predicted danger level reflects the risk of the potential action and provides an explicit reference for the final action, which corresponds to the preset personalized prompt. Moreover, we construct a closed-loop benchmark named PAD-Highway based on Highway-Env simulator to comprehensively evaluate the decision performance under traffic rules. The dataset contains 250 hours videos with high-quality annotation to facilitate the development of PAD behavior analysis. Experimental results on the constructed benchmark show that PADriver outperforms state-of-the-art approaches on different evaluation metrics, and enables various driving modes.
R1-T1: Fully Incentivizing Translation Capability in LLMs via Reasoning Learning
Feb 27, 2025

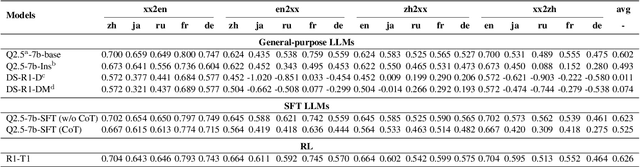
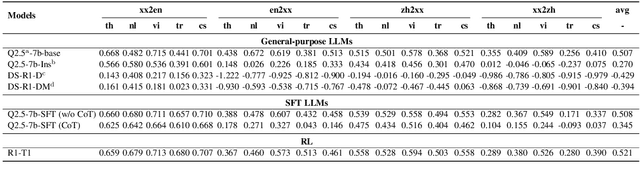
Despite recent breakthroughs in reasoning-enhanced large language models (LLMs) like DeepSeek-R1, incorporating inference-time reasoning into machine translation (MT), where human translators naturally employ structured, multi-layered reasoning chain-of-thoughts (CoTs), is yet underexplored. Existing methods either design a fixed CoT tailored for a specific MT sub-task (e.g., literature translation), or rely on synthesizing CoTs unaligned with humans and supervised fine-tuning (SFT) prone to catastrophic forgetting, limiting their adaptability to diverse translation scenarios. This paper introduces R1-Translator (R1-T1), a novel framework to achieve inference-time reasoning for general MT via reinforcement learning (RL) with human-aligned CoTs comprising six common patterns. Our approach pioneers three innovations: (1) extending reasoning-based translation beyond MT sub-tasks to six languages and diverse tasks (e.g., legal/medical domain adaptation, idiom resolution); (2) formalizing six expert-curated CoT templates that mirror hybrid human strategies like context-aware paraphrasing and back translation; and (3) enabling self-evolving CoT discovery and anti-forgetting adaptation through RL with KL-constrained rewards. Experimental results indicate a steady translation performance improvement in 21 languages and 80 translation directions on Flores-101 test set, especially on the 15 languages unseen from training, with its general multilingual abilities preserved compared with plain SFT.
RoboMatrix: A Skill-centric Hierarchical Framework for Scalable Robot Task Planning and Execution in Open-World
Nov 29, 2024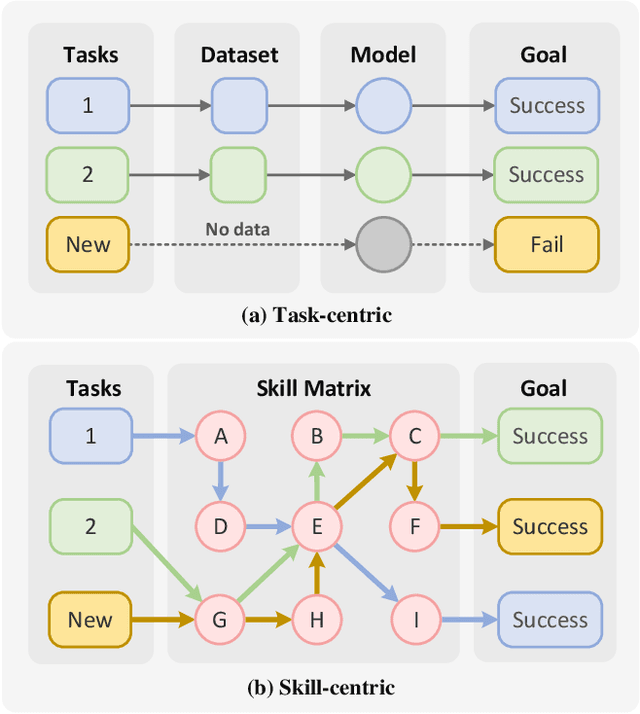

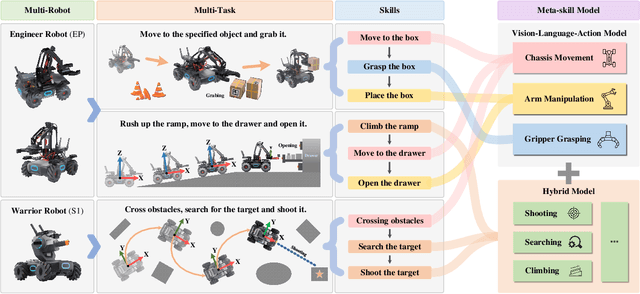

Existing policy learning methods predominantly adopt the task-centric paradigm, necessitating the collection of task data in an end-to-end manner. Consequently, the learned policy tends to fail to tackle novel tasks. Moreover, it is hard to localize the errors for a complex task with multiple stages due to end-to-end learning. To address these challenges, we propose RoboMatrix, a skill-centric and hierarchical framework for scalable task planning and execution. We first introduce a novel skill-centric paradigm that extracts the common meta-skills from different complex tasks. This allows for the capture of embodied demonstrations through a kill-centric approach, enabling the completion of open-world tasks by combining learned meta-skills. To fully leverage meta-skills, we further develop a hierarchical framework that decouples complex robot tasks into three interconnected layers: (1) a high-level modular scheduling layer; (2) a middle-level skill layer; and (3) a low-level hardware layer. Experimental results illustrate that our skill-centric and hierarchical framework achieves remarkable generalization performance across novel objects, scenes, tasks, and embodiments. This framework offers a novel solution for robot task planning and execution in open-world scenarios. Our software and hardware are available at https://github.com/WayneMao/RoboMatrix.