 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Robotic Policy Learning via Latent Space Backward Planning
May 11, 2025Current robotic planning methods often rely on predicting multi-frame images with full pixel details. While this fine-grained approach can serve as a generic world model, it introduces two significant challenges for downstream policy learning: substantial computational costs that hinder real-time deployment, and accumulated inaccuracies that can mislead action extraction. Planning with coarse-grained subgoals partially alleviates efficiency issues. However, their forward planning schemes can still result in off-task predictions due to accumulation errors, leading to misalignment with long-term goals. This raises a critical question: Can robotic planning be both efficient and accurate enough for real-time control in long-horizon, multi-stage tasks? To address this, we propose a Latent Space Backward Planning scheme (LBP), which begins by grounding the task into final latent goals, followed by recursively predicting intermediate subgoals closer to the current state. The grounded final goal enables backward subgoal planning to always remain aware of task completion, facilitating on-task prediction along the entire planning horizon. The subgoal-conditioned policy incorporates a learnable token to summarize the subgoal sequences and determines how each subgoal guides action extraction. Through extensive simulation and real-robot long-horizon experiments, we show that LBP outperforms existing fine-grained and forward planning methods, achieving SOTA performance. Project Page: https://lbp-authors.github.io
Diffusion-Based Planning for Autonomous Driving with Flexible Guidance
Jan 26, 2025



Achieving human-like driving behaviors in complex open-world environments is a critical challenge in autonomous driving. Contemporary learning-based planning approaches such as imitation learning methods often struggle to balance competing objectives and lack of safety assurance,due to limited adaptability and inadequacy in learning complex multi-modal behaviors commonly exhibited in human planning, not to mention their strong reliance on the fallback strategy with predefined rules. We propose a novel transformer-based Diffusion Planner for closed-loop planning, which can effectively model multi-modal driving behavior and ensure trajectory quality without any rule-based refinement. Our model supports joint modeling of both prediction and planning tasks under the same architecture, enabling cooperative behaviors between vehicles. Moreover, by learning the gradient of the trajectory score function and employing a flexible classifier guidance mechanism, Diffusion Planner effectively achieves safe and adaptable planning behaviors. Evaluations on the large-scale real-world autonomous planning benchmark nuPlan and our newly collected 200-hour delivery-vehicle driving dataset demonstrate that Diffusion Planner achieves state-of-the-art closed-loop performance with robust transferability in diverse driving styles.
Universal Actions for Enhanced Embodied Foundation Models
Jan 17, 2025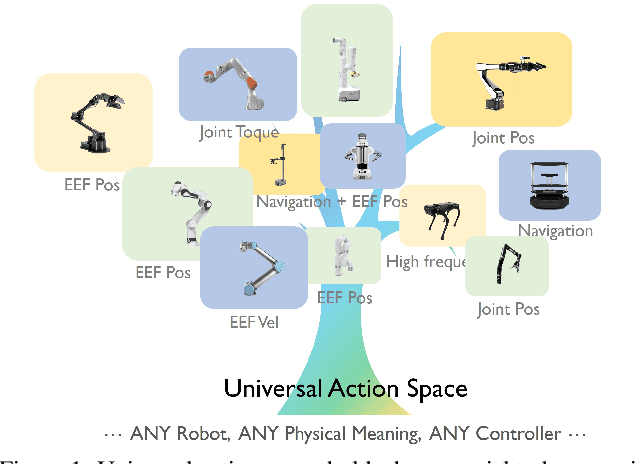

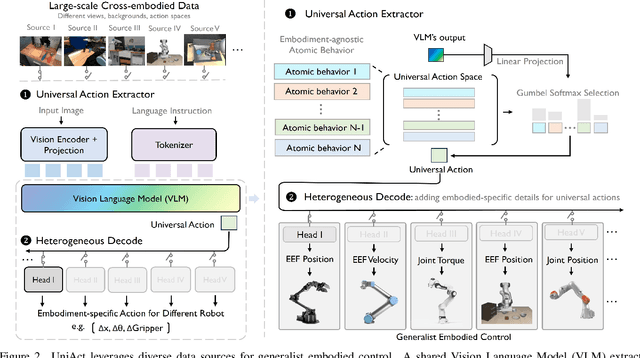
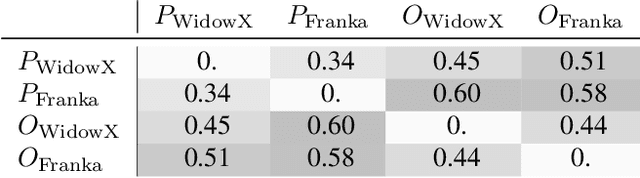
Training on diverse, internet-scale data is a key factor in the success of recent large foundation models. Yet, using the same recipe for building embodied agents has faced noticeable difficulties. Despite the availability of many crowd-sourced embodied datasets, their action spaces often exhibit significant heterogeneity due to distinct physical embodiment and control interfaces for different robots, causing substantial challenges in developing embodied foundation models using cross-domain data. In this paper, we introduce UniAct, a new embodied foundation modeling framework operating in a tokenized Universal Action Space. Our learned universal actions capture the generic atomic behaviors across diverse robots by exploiting their shared structural features, and enable enhanced cross-domain data utilization and cross-embodiment generalizations by eliminating the notorious heterogeneity. The universal actions can be efficiently translated back to heterogeneous actionable commands by simply adding embodiment-specific details, from which fast adaptation to new robots becomes simple and straightforward. Our 0.5B instantiation of UniAct outperforms 14X larger SOTA embodied foundation models in extensive evaluations on various real-world and simulation robots, showcasing exceptional cross-embodiment control and adaptation capability, highlighting the crucial benefit of adopting universal actions. Project page: https://github.com/2toinf/UniAct
Robo-MUTUAL: Robotic Multimodal Task Specification via Unimodal Learning
Oct 02, 2024



Multimodal task specification is essential for enhanced robotic performance, where \textit{Cross-modality Alignment} enables the robot to holistically understand complex task instructions. Directly annotating multimodal instructions for model training proves impractical, due to the sparsity of paired multimodal data. In this study, we demonstrate that by leveraging unimodal instructions abundant in real data, we can effectively teach robots to learn multimodal task specifications. First, we endow the robot with strong \textit{Cross-modality Alignment} capabilities, by pretraining a robotic multimodal encoder using extensive out-of-domain data. Then, we employ two Collapse and Corrupt operations to further bridge the remaining modality gap in the learned multimodal representation. This approach projects different modalities of identical task goal as interchangeable representations, thus enabling accurate robotic operations within a well-aligned multimodal latent space. Evaluation across more than 130 tasks and 4000 evaluations on both simulated LIBERO benchmark and real robot platforms showcases the superior capabilities of our proposed framework, demonstrating significant advantage in overcoming data constraints in robotic learning. Website: zh1hao.wang/Robo_MUTUAL
MM-Instruct: Generated Visual Instructions for Large Multimodal Model Alignment
Jun 28, 2024
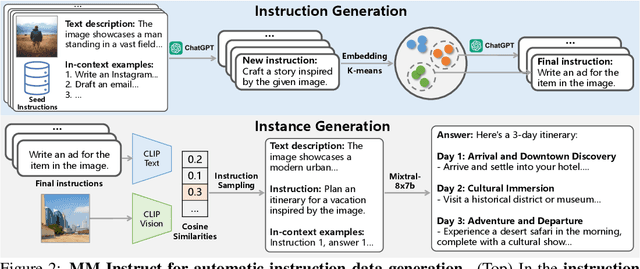


This paper introduces MM-Instruct, a large-scale dataset of diverse and high-quality visual instruction data designed to enhance the instruction-following capabilities of large multimodal models (LMMs). While existing visual instruction datasets often focus on question-answering, they struggle to generalize to broader application scenarios such as creative writing, summarization, or image analysis. To address these limitations, we propose a novel approach to constructing MM-Instruct that leverages the strong instruction-following capabilities of existing LLMs to generate novel visual instruction data from large-scale but conventional image captioning datasets. MM-Instruct first leverages ChatGPT to automatically generate diverse instructions from a small set of seed instructions through augmenting and summarization. It then matches these instructions with images and uses an open-sourced large language model (LLM) to generate coherent answers to the instruction-image pairs. The LLM is grounded by the detailed text descriptions of images in the whole answer generation process to guarantee the alignment of the instruction data. Moreover, we introduce a benchmark based on the generated instruction data to evaluate the instruction-following capabilities of existing LMMs. We demonstrate the effectiveness of MM-Instruct by training a LLaVA-1.5 model on the generated data, denoted as LLaVA-Instruct, which exhibits significant improvements in instruction-following capabilities compared to LLaVA-1.5 models. The MM-Instruct dataset, benchmark, and pre-trained models are available at https://github.com/jihaonew/MM-Instruct.
Instruction-Guided Visual Masking
May 30, 2024

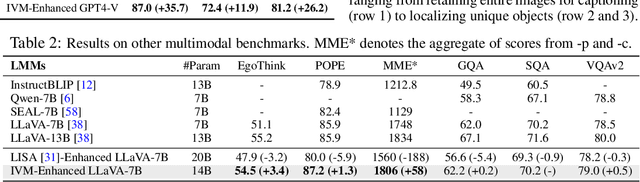

Instruction following is crucial in contemporary LLM. However, when extended to multimodal setting, it often suffers from misalignment between specific textual instruction and targeted local region of an image. To achieve more accurate and nuanced multimodal instruction following, we introduce Instruction-guided Visual Masking (IVM), a new versatile visual grounding model that is compatible with diverse multimodal models, such as LMM and robot model. By constructing visual masks for instruction-irrelevant regions, IVM-enhanced multimodal models can effectively focus on task-relevant image regions to better align with complex instructions. Specifically, we design a visual masking data generation pipeline and create an IVM-Mix-1M dataset with 1 million image-instruction pairs. We further introduce a new learning technique, Discriminator Weighted Supervised Learning (DWSL) for preferential IVM training that prioritizes high-quality data samples. Experimental results on generic multimodal tasks such as VQA and embodied robotic control demonstrate the versatility of IVM, which as a plug-and-play tool, significantly boosts the performance of diverse multimodal models, yielding new state-of-the-art results across challenging multimodal benchmarks. Code is available at https://github.com/2toinf/IVM.
Enhancing Vision-Language Model with Unmasked Token Alignment
May 29, 2024
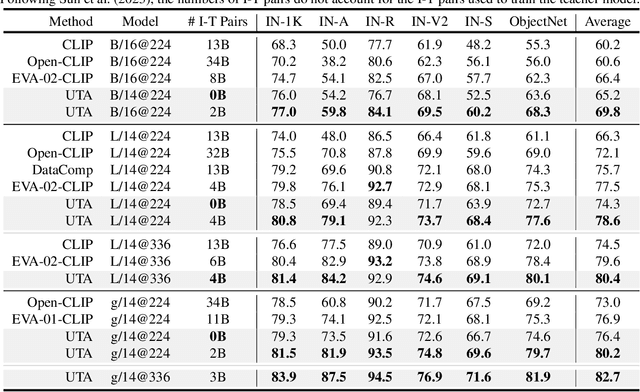
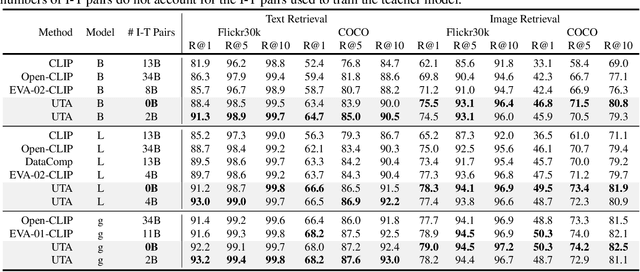

Contrastive pre-training on image-text pairs, exemplified by CLIP, becomes a standard technique for learning multi-modal visual-language representations. Although CLIP has demonstrated remarkable performance, training it from scratch on noisy web-scale datasets is computationally demanding. On the other hand, mask-then-predict pre-training approaches, like Masked Image Modeling (MIM), offer efficient self-supervised learning for single-modal representations. This paper introduces Unmasked Token Alignment (UTA), a method that leverages existing CLIP models to further enhance its vision-language representations. UTA trains a Vision Transformer (ViT) by aligning unmasked visual tokens to the corresponding image tokens from a frozen CLIP vision encoder, which automatically aligns the ViT model with the CLIP text encoder. The pre-trained ViT can be directly applied for zero-shot evaluation even without training on image-text pairs. Compared to MIM approaches, UTA does not suffer from training-finetuning inconsistency and is much more training-efficient by avoiding using the extra [MASK] tokens. Extensive experimental results demonstrate that UTA can enhance CLIP models and outperform existing MIM methods on various uni- and multi-modal benchmarks. Code and models are available at https://github.com/jihaonew/UTA.
GLID: Pre-training a Generalist Encoder-Decoder Vision Model
Apr 11, 2024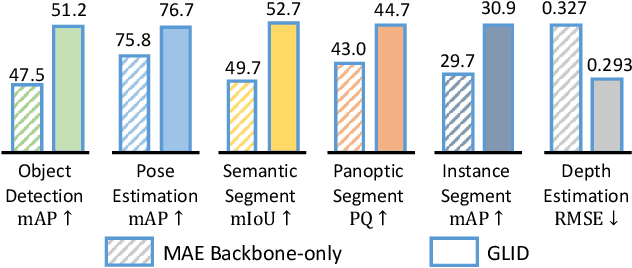
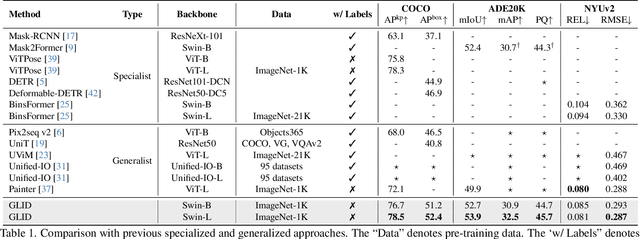
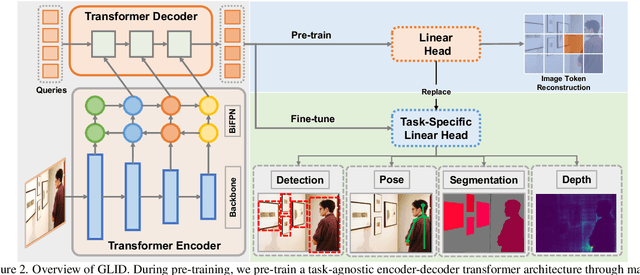
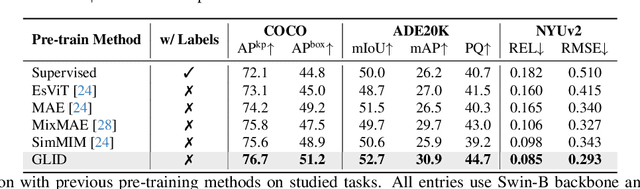
This paper proposes a GeneraLIst encoder-Decoder (GLID) pre-training method for better handling various downstream computer vision tasks. While self-supervised pre-training approaches, e.g., Masked Autoencoder, have shown success in transfer learning, task-specific sub-architectures are still required to be appended for different downstream tasks, which cannot enjoy the benefits of large-scale pre-training. GLID overcomes this challenge by allowing the pre-trained generalist encoder-decoder to be fine-tuned on various vision tasks with minimal task-specific architecture modifications. In the GLID training scheme, pre-training pretext task and other downstream tasks are modeled as "query-to-answer" problems, including the pre-training pretext task and other downstream tasks. We pre-train a task-agnostic encoder-decoder with query-mask pairs. During fine-tuning, GLID maintains the pre-trained encoder-decoder and queries, only replacing the topmost linear transformation layer with task-specific linear heads. This minimizes the pretrain-finetune architecture inconsistency and enables the pre-trained model to better adapt to downstream tasks. GLID achieves competitive performance on various vision tasks, including object detection, image segmentation, pose estimation, and depth estimation, outperforming or matching specialist models such as Mask2Former, DETR, ViTPose, and BinsFormer.
DecisionNCE: Embodied Multimodal Representations via Implicit Preference Learning
Feb 28, 2024Multimodal pretraining has emerged as an effective strategy for the trinity of goals of representation learning in autonomous robots: 1) extracting both local and global task progression information; 2) enforcing temporal consistency of visual representation; 3) capturing trajectory-level language grounding. Most existing methods approach these via separate objectives, which often reach sub-optimal solutions. In this paper, we propose a universal unified objective that can simultaneously extract meaningful task progression information from image sequences and seamlessly align them with language instructions. We discover that via implicit preferences, where a visual trajectory inherently aligns better with its corresponding language instruction than mismatched pairs, the popular Bradley-Terry model can transform into representation learning through proper reward reparameterizations. The resulted framework, DecisionNCE, mirrors an InfoNCE-style objective but is distinctively tailored for decision-making tasks, providing an embodied representation learning framework that elegantly extracts both local and global task progression features, with temporal consistency enforced through implicit time contrastive learning, while ensuring trajectory-level instruction grounding via multimodal joint encoding. Evaluation on both simulated and real robots demonstrates that DecisionNCE effectively facilitates diverse downstream policy learning tasks, offering a versatile solution for unified representation and reward learning. Project Page: https://2toinf.github.io/DecisionNCE/