 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLingNav: Embodied Navigation with Adaptive Reasoning and Visual-Assisted Linguistic Memory
Jan 13, 2026VLA models have shown promising potential in embodied navigation by unifying perception and planning while inheriting the strong generalization abilities of large VLMs. However, most existing VLA models rely on reactive mappings directly from observations to actions, lacking the explicit reasoning capabilities and persistent memory required for complex, long-horizon navigation tasks. To address these challenges, we propose VLingNav, a VLA model for embodied navigation grounded in linguistic-driven cognition. First, inspired by the dual-process theory of human cognition, we introduce an adaptive chain-of-thought mechanism, which dynamically triggers explicit reasoning only when necessary, enabling the agent to fluidly switch between fast, intuitive execution and slow, deliberate planning. Second, to handle long-horizon spatial dependencies, we develop a visual-assisted linguistic memory module that constructs a persistent, cross-modal semantic memory, enabling the agent to recall past observations to prevent repetitive exploration and infer movement trends for dynamic environments. For the training recipe, we construct Nav-AdaCoT-2.9M, the largest embodied navigation dataset with reasoning annotations to date, enriched with adaptive CoT annotations that induce a reasoning paradigm capable of adjusting both when to think and what to think about. Moreover, we incorporate an online expert-guided reinforcement learning stage, enabling the model to surpass pure imitation learning and to acquire more robust, self-explored navigation behaviors. Extensive experiments demonstrate that VLingNav achieves state-of-the-art performance across a wide range of embodied navigation benchmarks. Notably, VLingNav transfers to real-world robotic platforms in a zero-shot manner, executing various navigation tasks and demonstrating strong cross-domain and cross-task generalization.
ReSPIRe: Informative and Reusable Belief Tree Search for Robot Probabilistic Search and Tracking in Unknown Environments
Dec 31, 2025Target search and tracking (SAT) is a fundamental problem for various robotic applications such as search and rescue and environmental exploration. This paper proposes an informative trajectory planning approach, namely ReSPIRe, for SAT in unknown cluttered environments under considerably inaccurate prior target information and limited sensing field of view. We first develop a novel sigma point-based approximation approach to fast and accurately estimate mutual information reward under non-Gaussian belief distributions, utilizing informative sampling in state and observation spaces to mitigate the computational intractability of integral calculation. To tackle significant uncertainty associated with inadequate prior target information, we propose the hierarchical particle structure in ReSPIRe, which not only extracts critical particles for global route guidance, but also adjusts the particle number adaptively for planning efficiency. Building upon the hierarchical structure, we develop the reusable belief tree search approach to build a policy tree for online trajectory planning under uncertainty, which reuses rollout evaluation to improve planning efficiency. Extensive simulations and real-world experiments demonstrate that ReSPIRe outperforms representative benchmark methods with smaller MI approximation error, higher search efficiency, and more stable tracking performance, while maintaining outstanding computational efficiency.
Detect Anything via Next Point Prediction
Oct 14, 2025Object detection has long been dominated by traditional coordinate regression-based models, such as YOLO, DETR, and Grounding DINO. Although recent efforts have attempted to leverage MLLMs to tackle this task, they face challenges like low recall rate, duplicate predictions, coordinate misalignment, etc. In this work, we bridge this gap and propose Rex-Omni, a 3B-scale MLLM that achieves state-of-the-art object perception performance. On benchmarks like COCO and LVIS, Rex-Omni attains performance comparable to or exceeding regression-based models (e.g., DINO, Grounding DINO) in a zero-shot setting. This is enabled by three key designs: 1) Task Formulation: we use special tokens to represent quantized coordinates from 0 to 999, reducing the model's learning difficulty and improving token efficiency for coordinate prediction; 2) Data Engines: we construct multiple data engines to generate high-quality grounding, referring, and pointing data, providing semantically rich supervision for training; \3) Training Pipelines: we employ a two-stage training process, combining supervised fine-tuning on 22 million data with GRPO-based reinforcement post-training. This RL post-training leverages geometry-aware rewards to effectively bridge the discrete-to-continuous coordinate prediction gap, improve box accuracy, and mitigate undesirable behaviors like duplicate predictions that stem from the teacher-guided nature of the initial SFT stage. Beyond conventional detection, Rex-Omni's inherent language understanding enables versatile capabilities such as object referring, pointing, visual prompting, GUI grounding, spatial referring, OCR and key-pointing, all systematically evaluated on dedicated benchmarks. We believe that Rex-Omni paves the way for more versatile and language-aware visual perception systems.
LET-US: Long Event-Text Understanding of Scenes
Aug 10, 2025Event cameras output event streams as sparse, asynchronous data with microsecond-level temporal resolution, enabling visual perception with low latency and a high dynamic range. While existing Multimodal Large Language Models (MLLMs) have achieved significant success in understanding and analyzing RGB video content, they either fail to interpret event streams effectively or remain constrained to very short sequences. In this paper, we introduce LET-US, a framework for long event-stream--text comprehension that employs an adaptive compression mechanism to reduce the volume of input events while preserving critical visual details. LET-US thus establishes a new frontier in cross-modal inferential understanding over extended event sequences. To bridge the substantial modality gap between event streams and textual representations, we adopt a two-stage optimization paradigm that progressively equips our model with the capacity to interpret event-based scenes. To handle the voluminous temporal information inherent in long event streams, we leverage text-guided cross-modal queries for feature reduction, augmented by hierarchical clustering and similarity computation to distill the most representative event features. Moreover, we curate and construct a large-scale event-text aligned dataset to train our model, achieving tighter alignment of event features within the LLM embedding space. We also develop a comprehensive benchmark covering a diverse set of tasks -- reasoning, captioning, classification, temporal localization and moment retrieval. Experimental results demonstrate that LET-US outperforms prior state-of-the-art MLLMs in both descriptive accuracy and semantic comprehension on long-duration event streams. All datasets, codes, and models will be publicly available.
A Novel ViDAR Device With Visual Inertial Encoder Odometry and Reinforcement Learning-Based Active SLAM Method
Jun 16, 2025In the field of multi-sensor fusion for simultaneous localization and mapping (SLAM), monocular cameras and IMUs are widely used to build simple and effective visual-inertial systems. However, limited research has explored the integration of motor-encoder devices to enhance SLAM performance. By incorporating such devices, it is possible to significantly improve active capability and field of view (FOV) with minimal additional cost and structural complexity. This paper proposes a novel visual-inertial-encoder tightly coupled odometry (VIEO) based on a ViDAR (Video Detection and Ranging) device. A ViDAR calibration method is introduced to ensure accurate initialization for VIEO. In addition, a platform motion decoupled active SLAM method based on deep reinforcement learning (DRL) is proposed. Experimental data demonstrate that the proposed ViDAR and the VIEO algorithm significantly increase cross-frame co-visibility relationships compared to its corresponding visual-inertial odometry (VIO) algorithm, improving state estimation accuracy. Additionally, the DRL-based active SLAM algorithm, with the ability to decouple from platform motion, can increase the diversity weight of the feature points and further enhance the VIEO algorithm's performance. The proposed methodology sheds fresh insights into both the updated platform design and decoupled approach of active SLAM systems in complex environments.
* 12 pages, 13 figures
Rex-Thinker: Grounded Object Referring via Chain-of-Thought Reasoning
Jun 04, 2025Object referring aims to detect all objects in an image that match a given natural language description. We argue that a robust object referring model should be grounded, meaning its predictions should be both explainable and faithful to the visual content. Specifically, it should satisfy two key properties: 1) Verifiable, by producing interpretable reasoning that justifies its predictions and clearly links them to visual evidence; and 2) Trustworthy, by learning to abstain when no object in the image satisfies the given expression. However, most methods treat referring as a direct bounding box prediction task, offering limited interpretability and struggling to reject expressions with no matching object. In this work, we propose Rex-Thinker, a model that formulates object referring as an explicit CoT reasoning task. Given a referring expression, we first identify all candidate object instances corresponding to the referred object category. Rex-Thinker then performs step-by-step reasoning over each candidate to assess whether it matches the given expression, before making a final prediction. To support this paradigm, we construct a large-scale CoT-style referring dataset named HumanRef-CoT by prompting GPT-4o on the HumanRef dataset. Each reasoning trace follows a structured planning, action, and summarization format, enabling the model to learn decomposed, interpretable reasoning over object candidates. We then train Rex-Thinker in two stages: a cold-start supervised fine-tuning phase to teach the model how to perform structured reasoning, followed by GRPO-based RL learning to improve accuracy and generalization. Experiments show that our approach outperforms standard baselines in both precision and interpretability on in-domain evaluation, while also demonstrating improved ability to reject hallucinated outputs and strong generalization in out-of-domain settings.
TrackVLA: Embodied Visual Tracking in the Wild
May 29, 2025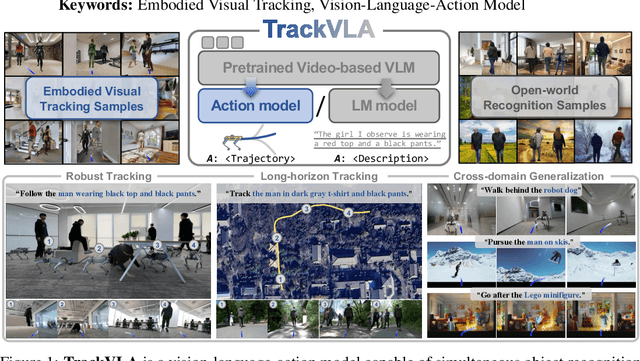

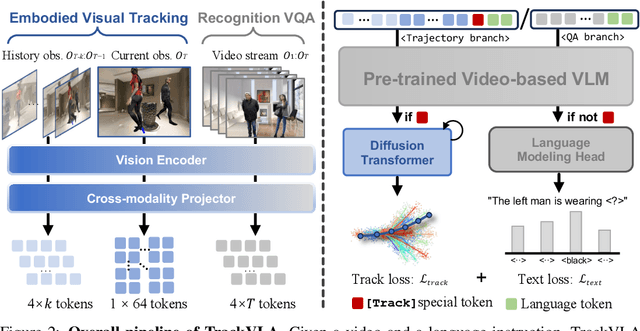
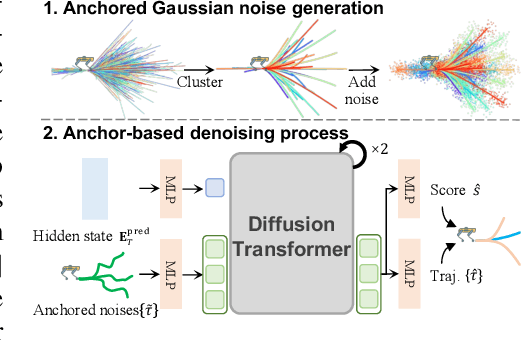
Embodied visual tracking is a fundamental skill in Embodied AI, enabling an agent to follow a specific target in dynamic environments using only egocentric vision. This task is inherently challenging as it requires both accurate target recognition and effective trajectory planning under conditions of severe occlusion and high scene dynamics. Existing approaches typically address this challenge through a modular separation of recognition and planning. In this work, we propose TrackVLA, a Vision-Language-Action (VLA) model that learns the synergy between object recognition and trajectory planning. Leveraging a shared LLM backbone, we employ a language modeling head for recognition and an anchor-based diffusion model for trajectory planning. To train TrackVLA, we construct an Embodied Visual Tracking Benchmark (EVT-Bench) and collect diverse difficulty levels of recognition samples, resulting in a dataset of 1.7 million samples. Through extensive experiments in both synthetic and real-world environments, TrackVLA demonstrates SOTA performance and strong generalizability. It significantly outperforms existing methods on public benchmarks in a zero-shot manner while remaining robust to high dynamics and occlusion in real-world scenarios at 10 FPS inference speed. Our project page is: https://pku-epic.github.io/TrackVLA-web.
A Novel Underwater Vehicle With Orientation Adjustable Thrusters: Design and Adaptive Tracking Control
Mar 25, 2025


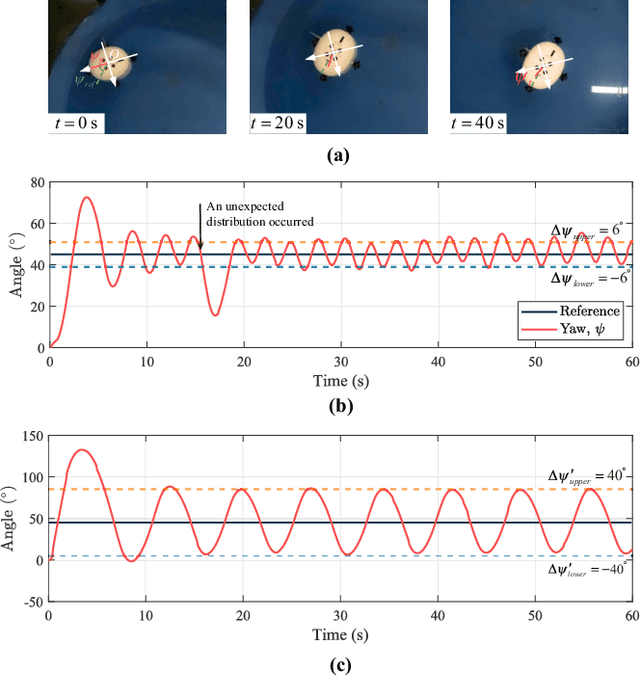
Autonomous underwater vehicles (AUVs) are essential for marine exploration and research. However, conventional designs often struggle with limited maneuverability in complex, dynamic underwater environments. This paper introduces an innovative orientation-adjustable thruster AUV (OATAUV), equipped with a redundant vector thruster configuration that enables full six-degree-of-freedom (6-DOF) motion and composite maneuvers. To overcome challenges associated with uncertain model parameters and environmental disturbances, a novel feedforward adaptive model predictive controller (FFAMPC) is proposed to ensure robust trajectory tracking, which integrates real-time state feedback with adaptive parameter updates. Extensive experiments, including closed-loop tracking and composite motion tests in a laboratory pool, validate the enhanced performance of the OAT-AUV. The results demonstrate that the OAT-AUV's redundant vector thruster configuration enables 23.8% cost reduction relative to common vehicles, while the FF-AMPC controller achieves 68.6% trajectory tracking improvement compared to PID controllers. Uniquely, the system executes composite helical/spiral trajectories unattainable by similar vehicles.
HandOS: 3D Hand Reconstruction in One Stage
Dec 02, 2024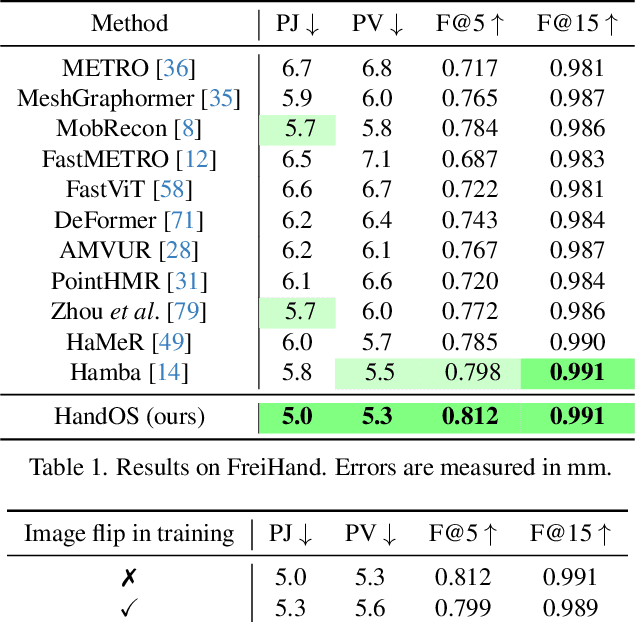
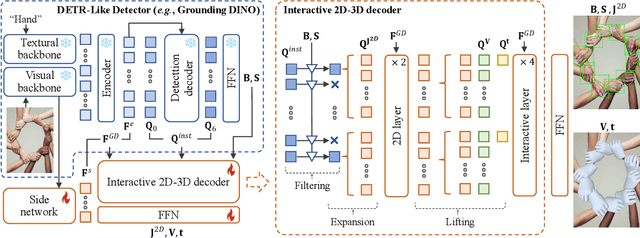
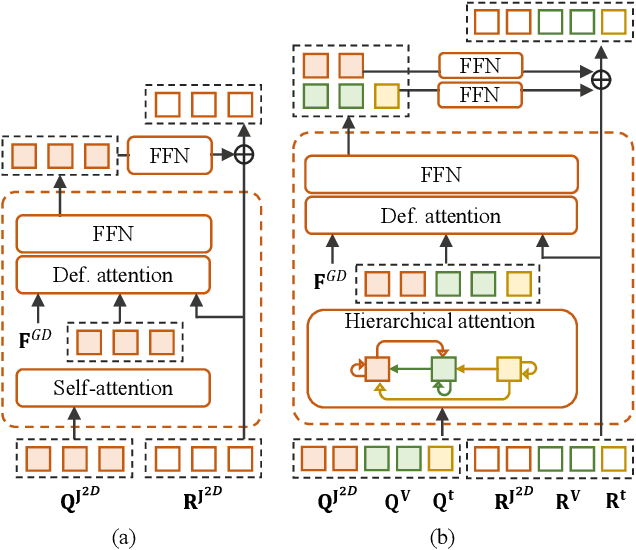
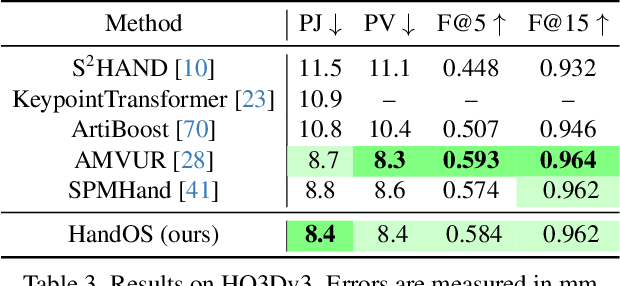
Existing approaches of hand reconstruction predominantly adhere to a multi-stage framework, encompassing detection, left-right classification, and pose estimation. This paradigm induces redundant computation and cumulative errors. In this work, we propose HandOS, an end-to-end framework for 3D hand reconstruction. Our central motivation lies in leveraging a frozen detector as the foundation while incorporating auxiliary modules for 2D and 3D keypoint estimation. In this manner, we integrate the pose estimation capacity into the detection framework, while at the same time obviating the necessity of using the left-right category as a prerequisite. Specifically, we propose an interactive 2D-3D decoder, where 2D joint semantics is derived from detection cues while 3D representation is lifted from those of 2D joints. Furthermore, hierarchical attention is designed to enable the concurrent modeling of 2D joints, 3D vertices, and camera translation. Consequently, we achieve an end-to-end integration of hand detection, 2D pose estimation, and 3D mesh reconstruction within a one-stage framework, so that the above multi-stage drawbacks are overcome. Meanwhile, the HandOS reaches state-of-the-art performances on public benchmarks, e.g., 5.0 PA-MPJPE on FreiHand and 64.6\% PCK@0.05 on HInt-Ego4D. Project page: idea-research.github.io/HandOSweb.
Robo-MUTUAL: Robotic Multimodal Task Specification via Unimodal Learning
Oct 02, 2024



Multimodal task specification is essential for enhanced robotic performance, where \textit{Cross-modality Alignment} enables the robot to holistically understand complex task instructions. Directly annotating multimodal instructions for model training proves impractical, due to the sparsity of paired multimodal data. In this study, we demonstrate that by leveraging unimodal instructions abundant in real data, we can effectively teach robots to learn multimodal task specifications. First, we endow the robot with strong \textit{Cross-modality Alignment} capabilities, by pretraining a robotic multimodal encoder using extensive out-of-domain data. Then, we employ two Collapse and Corrupt operations to further bridge the remaining modality gap in the learned multimodal representation. This approach projects different modalities of identical task goal as interchangeable representations, thus enabling accurate robotic operations within a well-aligned multimodal latent space. Evaluation across more than 130 tasks and 4000 evaluations on both simulated LIBERO benchmark and real robot platforms showcases the superior capabilities of our proposed framework, demonstrating significant advantage in overcoming data constraints in robotic learning. Website: zh1hao.wang/Robo_MUTUAL