 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLingNav: Embodied Navigation with Adaptive Reasoning and Visual-Assisted Linguistic Memory
Jan 13, 2026VLA models have shown promising potential in embodied navigation by unifying perception and planning while inheriting the strong generalization abilities of large VLMs. However, most existing VLA models rely on reactive mappings directly from observations to actions, lacking the explicit reasoning capabilities and persistent memory required for complex, long-horizon navigation tasks. To address these challenges, we propose VLingNav, a VLA model for embodied navigation grounded in linguistic-driven cognition. First, inspired by the dual-process theory of human cognition, we introduce an adaptive chain-of-thought mechanism, which dynamically triggers explicit reasoning only when necessary, enabling the agent to fluidly switch between fast, intuitive execution and slow, deliberate planning. Second, to handle long-horizon spatial dependencies, we develop a visual-assisted linguistic memory module that constructs a persistent, cross-modal semantic memory, enabling the agent to recall past observations to prevent repetitive exploration and infer movement trends for dynamic environments. For the training recipe, we construct Nav-AdaCoT-2.9M, the largest embodied navigation dataset with reasoning annotations to date, enriched with adaptive CoT annotations that induce a reasoning paradigm capable of adjusting both when to think and what to think about. Moreover, we incorporate an online expert-guided reinforcement learning stage, enabling the model to surpass pure imitation learning and to acquire more robust, self-explored navigation behaviors. Extensive experiments demonstrate that VLingNav achieves state-of-the-art performance across a wide range of embodied navigation benchmarks. Notably, VLingNav transfers to real-world robotic platforms in a zero-shot manner, executing various navigation tasks and demonstrating strong cross-domain and cross-task generalization.
Linear-Time Demonstration Selection for In-Context Learning via Gradient Estimation
Aug 27, 2025

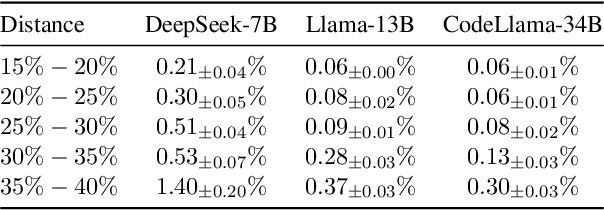

This paper introduces an algorithm to select demonstration examples for in-context learning of a query set. Given a set of $n$ examples, how can we quickly select $k$ out of $n$ to best serve as the conditioning for downstream inference? This problem has broad applications in prompt tuning and chain-of-thought reasoning. Since model weights remain fixed during in-context learning, previous work has sought to design methods based on the similarity of token embeddings. This work proposes a new approach based on gradients of the output taken in the input embedding space. Our approach estimates model outputs through a first-order approximation using the gradients. Then, we apply this estimation to multiple randomly sampled subsets. Finally, we aggregate the sampled subset outcomes to form an influence score for each demonstration, and select $k$ most relevant examples. This procedure only requires pre-computing model outputs and gradients once, resulting in a linear-time algorithm relative to model and training set sizes. Extensive experiments across various models and datasets validate the efficiency of our approach. We show that the gradient estimation procedure yields approximations of full inference with less than $\mathbf{1}\%$ error across six datasets. This allows us to scale up subset selection that would otherwise run full inference by up to $\mathbf{37.7}\times$ on models with up to $34$ billion parameters, and outperform existing selection methods based on input embeddings by $\mathbf{11}\%$ on average.
Efficient Ensemble for Fine-tuning Language Models on Multiple Datasets
May 28, 2025This paper develops an ensemble method for fine-tuning a language model to multiple datasets. Existing methods, such as quantized LoRA (QLoRA), are efficient when adapting to a single dataset. When training on multiple datasets of different tasks, a common setup in practice, it remains unclear how to design an efficient adaptation for fine-tuning language models. We propose to use an ensemble of multiple smaller adapters instead of a single adapter per task. We design an efficient algorithm that partitions $n$ datasets into $m$ groups, where $m$ is typically much smaller than $n$ in practice, and train one adapter for each group before taking a weighted combination to form the ensemble. The algorithm leverages a first-order approximation property of low-rank adaptation to quickly obtain the fine-tuning performances of dataset combinations since methods like LoRA stay close to the base model. Hence, we use the gradients of the base model to estimate its behavior during fine-tuning. Empirically, this approximation holds with less than $1\%$ error on models with up to $34$ billion parameters, leading to an estimation of true fine-tuning performances under $5\%$ error while speeding up computation compared to base fine-tuning by $105$ times. When applied to fine-tune Llama and GPT models on ten text classification tasks, our approach provides up to $10\%$ higher average test accuracy over QLoRA, with only $9\%$ more FLOPs. On a Llama model with $34$ billion parameters, an ensemble of QLoRA increases test accuracy by $3\%$ compared to QLoRA, with only $8\%$ more FLOPs.
Split Matching for Inductive Zero-shot Semantic Segmentation
May 08, 2025Zero-shot Semantic Segmentation (ZSS) aims to segment categories that are not annotated during training. While fine-tuning vision-language models has achieved promising results, these models often overfit to seen categories due to the lack of supervision for unseen classes. As an alternative to fully supervised approaches, query-based segmentation has shown great latent in ZSS, as it enables object localization without relying on explicit labels. However, conventional Hungarian matching, a core component in query-based frameworks, needs full supervision and often misclassifies unseen categories as background in the setting of ZSS. To address this issue, we propose Split Matching (SM), a novel assignment strategy that decouples Hungarian matching into two components: one for seen classes in annotated regions and another for latent classes in unannotated regions (referred to as unseen candidates). Specifically, we partition the queries into seen and candidate groups, enabling each to be optimized independently according to its available supervision. To discover unseen candidates, we cluster CLIP dense features to generate pseudo masks and extract region-level embeddings using CLS tokens. Matching is then conducted separately for the two groups based on both class-level similarity and mask-level consistency. Additionally, we introduce a Multi-scale Feature Enhancement (MFE) module that refines decoder features through residual multi-scale aggregation, improving the model's ability to capture spatial details across resolutions. SM is the first to introduce decoupled Hungarian matching under the inductive ZSS setting, and achieves state-of-the-art performance on two standard benchmarks.
Focus What Matters: Matchability-Based Reweighting for Local Feature Matching
May 04, 2025Since the rise of Transformers, many semi-dense matching methods have adopted attention mechanisms to extract feature descriptors. However, the attention weights, which capture dependencies between pixels or keypoints, are often learned from scratch. This approach can introduce redundancy and noisy interactions from irrelevant regions, as it treats all pixels or keypoints equally. Drawing inspiration from keypoint selection processes, we propose to first classify all pixels into two categories: matchable and non-matchable. Matchable pixels are expected to receive higher attention weights, while non-matchable ones are down-weighted. In this work, we propose a novel attention reweighting mechanism that simultaneously incorporates a learnable bias term into the attention logits and applies a matchability-informed rescaling to the input value features. The bias term, injected prior to the softmax operation, selectively adjusts attention scores based on the confidence of query-key interactions. Concurrently, the feature rescaling acts post-attention by modulating the influence of each value vector in the final output. This dual design allows the attention mechanism to dynamically adjust both its internal weighting scheme and the magnitude of its output representations. Extensive experiments conducted on three benchmark datasets validate the effectiveness of our method, consistently outperforming existing state-of-the-art approaches.
A Novel Underwater Vehicle With Orientation Adjustable Thrusters: Design and Adaptive Tracking Control
Mar 25, 2025Autonomous underwater vehicles (AUVs) are essential for marine exploration and research. However, conventional designs often struggle with limited maneuverability in complex, dynamic underwater environments. This paper introduces an innovative orientation-adjustable thruster AUV (OATAUV), equipped with a redundant vector thruster configuration that enables full six-degree-of-freedom (6-DOF) motion and composite maneuvers. To overcome challenges associated with uncertain model parameters and environmental disturbances, a novel feedforward adaptive model predictive controller (FFAMPC) is proposed to ensure robust trajectory tracking, which integrates real-time state feedback with adaptive parameter updates. Extensive experiments, including closed-loop tracking and composite motion tests in a laboratory pool, validate the enhanced performance of the OAT-AUV. The results demonstrate that the OAT-AUV's redundant vector thruster configuration enables 23.8% cost reduction relative to common vehicles, while the FF-AMPC controller achieves 68.6% trajectory tracking improvement compared to PID controllers. Uniquely, the system executes composite helical/spiral trajectories unattainable by similar vehicles.
CQVPR: Landmark-aware Contextual Queries for Visual Place Recognition
Mar 11, 2025
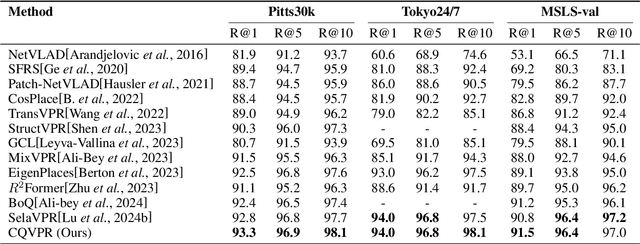


Visual Place Recognition (VPR) aims to estimate the location of the given query image within a database of geo-tagged images. To identify the exact location in an image, detecting landmarks is crucial. However, in some scenarios, such as urban environments, there are numerous landmarks, such as various modern buildings, and the landmarks in different cities often exhibit high visual similarity. Therefore, it is essential not only to leverage the landmarks but also to consider the contextual information surrounding them, such as whether there are trees, roads, or other features around the landmarks. We propose the Contextual Query VPR (CQVPR), which integrates contextual information with detailed pixel-level visual features. By leveraging a set of learnable contextual queries, our method automatically learns the high-level contexts with respect to landmarks and their surrounding areas. Heatmaps depicting regions that each query attends to serve as context-aware features, offering cues that could enhance the understanding of each scene. We further propose a query matching loss to supervise the extraction process of contextual queries. Extensive experiments on several datasets demonstrate that the proposed method outperforms other state-of-the-art methods, especially in challenging scenarios.
Scalable Fine-tuning from Multiple Data Sources:A First-Order Approximation Approach
Sep 28, 2024We study the problem of fine-tuning a language model (LM) for a target task by optimally using the information from $n$ auxiliary tasks. This problem has broad applications in NLP, such as targeted instruction tuning and data selection in chain-of-thought fine-tuning. The key challenge of this problem is that not all auxiliary tasks are useful to improve the performance of the target task. Thus, choosing the right subset of auxiliary tasks is crucial. Conventional subset selection methods, such as forward & backward selection, are unsuitable for LM fine-tuning because they require repeated training on subsets of auxiliary tasks. This paper introduces a new algorithm to estimate model fine-tuning performances without repeated training. Our algorithm first performs multitask training using the data of all the tasks to obtain a meta initialization. Then, we approximate the model fine-tuning loss of a subset using functional values and gradients from the meta initialization. Empirically, we find that this gradient-based approximation holds with remarkable accuracy for twelve transformer-based LMs. Thus, we can now estimate fine-tuning performances on CPUs within a few seconds. We conduct extensive experiments to validate our approach, delivering a speedup of $30\times$ over conventional subset selection while incurring only $1\%$ error of the true fine-tuning performances. In downstream evaluations of instruction tuning and chain-of-thought fine-tuning, our approach improves over prior methods that utilize gradient or representation similarity for subset selection by up to $3.8\%$.
Scalable Multitask Learning Using Gradient-based Estimation of Task Affinity
Sep 09, 2024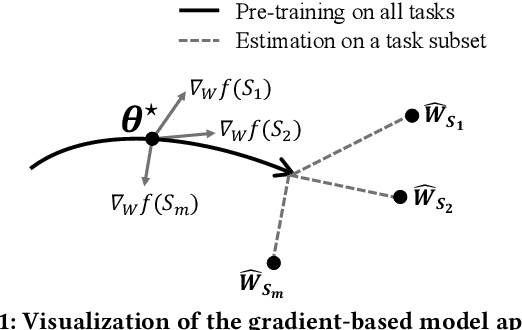
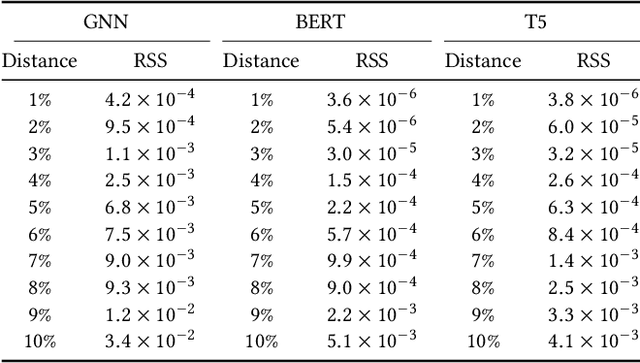

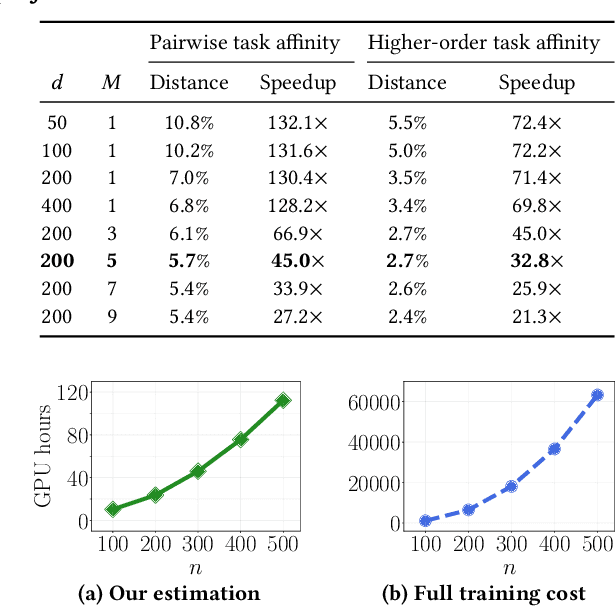
Multitask learning is a widely used paradigm for training models on diverse tasks, with applications ranging from graph neural networks to language model fine-tuning. Since tasks may interfere with each other, a key notion for modeling their relationships is task affinity. This includes pairwise task affinity, computed among pairs of tasks, and higher-order affinity, computed among subsets of tasks. Naively computing either of them requires repeatedly training on data from various task combinations, which is computationally intensive. We present a new algorithm Grad-TAG that can estimate task affinities without this repeated training. The key idea of Grad-TAG is to train a "base" model for all tasks and then use a linearization technique to estimate the loss of the model for a specific task combination. The linearization works by computing a gradient-based approximation of the loss, using low-dimensional projections of gradients as features in a logistic regression to predict labels for the task combination. We show that the linearized model can provably approximate the loss when the gradient-based approximation is accurate, and also empirically verify that on several large models. Then, given the estimated task affinity, we design a semi-definite program for clustering similar tasks by maximizing the average density of clusters. We evaluate Grad-TAG's performance across seven datasets, including multi-label classification on graphs, and instruction fine-tuning of language models. Our task affinity estimates are within 2.7% distance to the true affinities while needing only 3% of FLOPs in full training. On our largest graph with 21M edges and 500 labeling tasks, our algorithm delivers estimates within 5% distance to the true affinities, using only 112 GPU hours. Our results show that Grad-TAG achieves excellent performance and runtime tradeoffs compared to existing approaches.
Learning Tree-Structured Composition of Data Augmentation
Aug 26, 2024Data augmentation is widely used for training a neural network given little labeled data. A common practice of augmentation training is applying a composition of multiple transformations sequentially to the data. Existing augmentation methods such as RandAugment randomly sample from a list of pre-selected transformations, while methods such as AutoAugment apply advanced search to optimize over an augmentation set of size $k^d$, which is the number of transformation sequences of length $d$, given a list of $k$ transformations. In this paper, we design efficient algorithms whose running time complexity is much faster than the worst-case complexity of $O(k^d)$, provably. We propose a new algorithm to search for a binary tree-structured composition of $k$ transformations, where each tree node corresponds to one transformation. The binary tree generalizes sequential augmentations, such as the SimCLR augmentation scheme for contrastive learning. Using a top-down, recursive search procedure, our algorithm achieves a runtime complexity of $O(2^d k)$, which is much faster than $O(k^d)$ as $k$ increases above $2$. We apply our algorithm to tackle data distributions with heterogeneous subpopulations by searching for one tree in each subpopulation and then learning a weighted combination, resulting in a forest of trees. We validate our proposed algorithms on numerous graph and image datasets, including a multi-label graph classification dataset we collected. The dataset exhibits significant variations in the sizes of graphs and their average degrees, making it ideal for studying data augmentation. We show that our approach can reduce the computation cost by 43% over existing search methods while improving performance by 4.3%. The tree structures can be used to interpret the relative importance of each transformation, such as identifying the important transformations on small vs. large graphs.