 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks for Road Safety Modeling: Datasets and Evaluations for Accident Analysis
Oct 31, 2023We consider the problem of traffic accident analysis on a road network based on road network connections and traffic volume. Previous works have designed various deep-learning methods using historical records to predict traffic accident occurrences. However, there is a lack of consensus on how accurate existing methods are, and a fundamental issue is the lack of public accident datasets for comprehensive evaluations. This paper constructs a large-scale, unified dataset of traffic accident records from official reports of various states in the US, totaling 9 million records, accompanied by road networks and traffic volume reports. Using this new dataset, we evaluate existing deep-learning methods for predicting the occurrence of accidents on road networks. Our main finding is that graph neural networks such as GraphSAGE can accurately predict the number of accidents on roads with less than 22% mean absolute error (relative to the actual count) and whether an accident will occur or not with over 87% AUROC, averaged over states. We achieve these results by using multitask learning to account for cross-state variabilities (e.g., availability of accident labels) and transfer learning to combine traffic volume with accident prediction. Ablation studies highlight the importance of road graph-structural features, amongst other features. Lastly, we discuss the implications of the analysis and develop a package for easily using our new dataset.
Boosting Multitask Learning on Graphs through Higher-Order Task Affinities
Jun 24, 2023


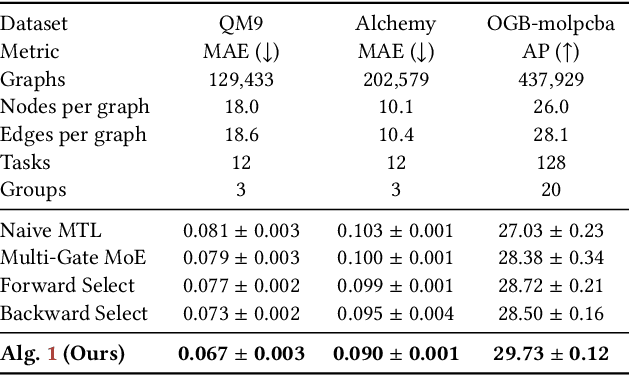
Predicting node labels on a given graph is a widely studied problem with many applications, including community detection and molecular graph prediction. This paper considers predicting multiple node labeling functions on graphs simultaneously and revisits this problem from a multitask learning perspective. For a concrete example, consider overlapping community detection: each community membership is a binary node classification task. Due to complex overlapping patterns, we find that negative transfer is prevalent when we apply naive multitask learning to multiple community detection, as task relationships are highly nonlinear across different node labeling. To address the challenge, we develop an algorithm to cluster tasks into groups based on a higher-order task affinity measure. We then fit a multitask model on each task group, resulting in a boosting procedure on top of the baseline model. We estimate the higher-order task affinity measure between two tasks as the prediction loss of one task in the presence of another task and a random subset of other tasks. Then, we use spectral clustering on the affinity score matrix to identify task grouping. We design several speedup techniques to compute the higher-order affinity scores efficiently and show that they can predict negative transfers more accurately than pairwise task affinities. We validate our procedure using various community detection and molecular graph prediction data sets, showing favorable results compared with existing methods. Lastly, we provide a theoretical analysis to show that under a planted block model of tasks on graphs, our affinity scores can provably separate tasks into groups.
Noise Stability Optimization for Flat Minima with Optimal Convergence Rates
Jun 14, 2023We consider finding flat, local minimizers by adding average weight perturbations. Given a nonconvex function $f: \mathbb{R}^d \rightarrow \mathbb{R}$ and a $d$-dimensional distribution $\mathcal{P}$ which is symmetric at zero, we perturb the weight of $f$ and define $F(W) = \mathbb{E}[f({W + U})]$, where $U$ is a random sample from $\mathcal{P}$. This injection induces regularization through the Hessian trace of $f$ for small, isotropic Gaussian perturbations. Thus, the weight-perturbed function biases to minimizers with low Hessian trace. Several prior works have studied settings related to this weight-perturbed function by designing algorithms to improve generalization. Still, convergence rates are not known for finding minima under the average perturbations of the function $F$. This paper considers an SGD-like algorithm that injects random noise before computing gradients while leveraging the symmetry of $\mathcal{P}$ to reduce variance. We then provide a rigorous analysis, showing matching upper and lower bounds of our algorithm for finding an approximate first-order stationary point of $F$ when the gradient of $f$ is Lipschitz-continuous. We empirically validate our algorithm for several image classification tasks with various architectures. Compared to sharpness-aware minimization, we note a 12.6% and 7.8% drop in the Hessian trace and top eigenvalue of the found minima, respectively, averaged over eight datasets. Ablation studies validate the benefit of the design of our algorithm.
Generalization in Graph Neural Networks: Improved PAC-Bayesian Bounds on Graph Diffusion
Feb 09, 2023Graph neural networks are widely used tools for graph prediction tasks. Motivated by their empirical performance, prior works have developed generalization bounds for graph neural networks, which scale with graph structures in terms of the maximum degree. In this paper, we present generalization bounds that instead scale with the largest singular value of the graph neural network's feature diffusion matrix. These bounds are numerically much smaller than prior bounds for real-world graphs. We also construct a lower bound of the generalization gap that matches our upper bound asymptotically. To achieve these results, we analyze a unified model that includes prior works' settings (i.e., convolutional and message-passing networks) and new settings (i.e., graph isomorphism networks). Our key idea is to measure the stability of graph neural networks against noise perturbations using Hessians. Empirically, we find that Hessian-based measurements correlate with the observed generalization gaps of graph neural networks accurately; Optimizing noise stability properties for fine-tuning pretrained graph neural networks also improves test performance on several graph-level classification tasks.
Robust Fine-Tuning of Deep Neural Networks with Hessian-based Generalization Guarantees
Jun 06, 2022
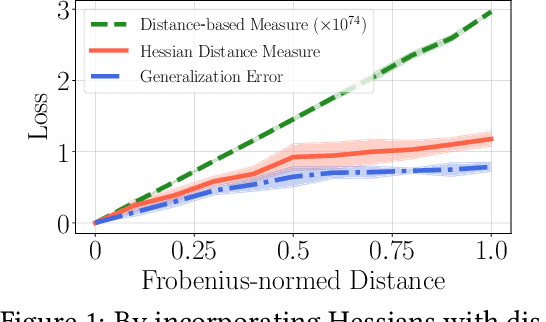

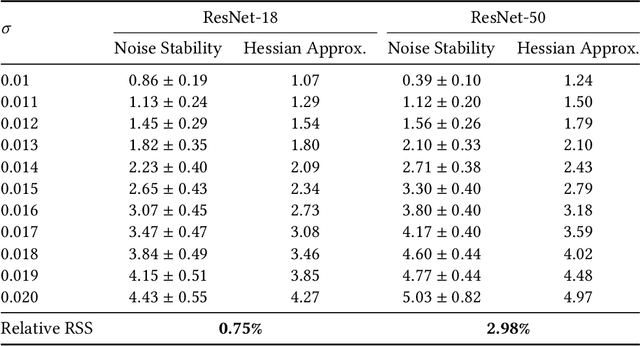
We consider transfer learning approaches that fine-tune a pretrained deep neural network on a target task. We investigate generalization properties of fine-tuning to understand the problem of overfitting, which often happens in practice. Previous works have shown that constraining the distance from the initialization of fine-tuning improves generalization. Using a PAC-Bayesian analysis, we observe that besides distance from initialization, Hessians affect generalization through the noise stability of deep neural networks against noise injections. Motivated by the observation, we develop Hessian distance-based generalization bounds for a wide range of fine-tuning methods. Next, we investigate the robustness of fine-tuning with noisy labels. We design an algorithm that incorporates consistent losses and distance-based regularization for fine-tuning. Additionally, we prove a generalization error bound of our algorithm under class conditional independent noise in the training dataset labels. We perform a detailed empirical study of our algorithm on various noisy environments and architectures. For example, on six image classification tasks whose training labels are generated with programmatic labeling, we show a 3.26% accuracy improvement over prior methods. Meanwhile, the Hessian distance measure of the fine-tuned network using our algorithm decreases by six times more than existing approaches.