 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCQVPR: Landmark-aware Contextual Queries for Visual Place Recognition
Paper and Code
Mar 11, 2025
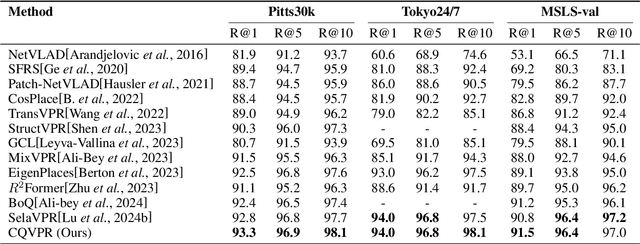


Visual Place Recognition (VPR) aims to estimate the location of the given query image within a database of geo-tagged images. To identify the exact location in an image, detecting landmarks is crucial. However, in some scenarios, such as urban environments, there are numerous landmarks, such as various modern buildings, and the landmarks in different cities often exhibit high visual similarity. Therefore, it is essential not only to leverage the landmarks but also to consider the contextual information surrounding them, such as whether there are trees, roads, or other features around the landmarks. We propose the Contextual Query VPR (CQVPR), which integrates contextual information with detailed pixel-level visual features. By leveraging a set of learnable contextual queries, our method automatically learns the high-level contexts with respect to landmarks and their surrounding areas. Heatmaps depicting regions that each query attends to serve as context-aware features, offering cues that could enhance the understanding of each scene. We further propose a query matching loss to supervise the extraction process of contextual queries. Extensive experiments on several datasets demonstrate that the proposed method outperforms other state-of-the-art methods, especially in challenging scenarios.