 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear-Time Demonstration Selection for In-Context Learning via Gradient Estimation
Aug 27, 2025

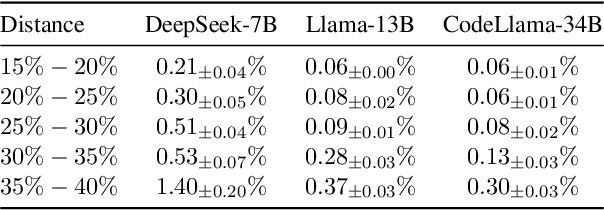

This paper introduces an algorithm to select demonstration examples for in-context learning of a query set. Given a set of $n$ examples, how can we quickly select $k$ out of $n$ to best serve as the conditioning for downstream inference? This problem has broad applications in prompt tuning and chain-of-thought reasoning. Since model weights remain fixed during in-context learning, previous work has sought to design methods based on the similarity of token embeddings. This work proposes a new approach based on gradients of the output taken in the input embedding space. Our approach estimates model outputs through a first-order approximation using the gradients. Then, we apply this estimation to multiple randomly sampled subsets. Finally, we aggregate the sampled subset outcomes to form an influence score for each demonstration, and select $k$ most relevant examples. This procedure only requires pre-computing model outputs and gradients once, resulting in a linear-time algorithm relative to model and training set sizes. Extensive experiments across various models and datasets validate the efficiency of our approach. We show that the gradient estimation procedure yields approximations of full inference with less than $\mathbf{1}\%$ error across six datasets. This allows us to scale up subset selection that would otherwise run full inference by up to $\mathbf{37.7}\times$ on models with up to $34$ billion parameters, and outperform existing selection methods based on input embeddings by $\mathbf{11}\%$ on average.
Efficient Ensemble for Fine-tuning Language Models on Multiple Datasets
May 28, 2025This paper develops an ensemble method for fine-tuning a language model to multiple datasets. Existing methods, such as quantized LoRA (QLoRA), are efficient when adapting to a single dataset. When training on multiple datasets of different tasks, a common setup in practice, it remains unclear how to design an efficient adaptation for fine-tuning language models. We propose to use an ensemble of multiple smaller adapters instead of a single adapter per task. We design an efficient algorithm that partitions $n$ datasets into $m$ groups, where $m$ is typically much smaller than $n$ in practice, and train one adapter for each group before taking a weighted combination to form the ensemble. The algorithm leverages a first-order approximation property of low-rank adaptation to quickly obtain the fine-tuning performances of dataset combinations since methods like LoRA stay close to the base model. Hence, we use the gradients of the base model to estimate its behavior during fine-tuning. Empirically, this approximation holds with less than $1\%$ error on models with up to $34$ billion parameters, leading to an estimation of true fine-tuning performances under $5\%$ error while speeding up computation compared to base fine-tuning by $105$ times. When applied to fine-tune Llama and GPT models on ten text classification tasks, our approach provides up to $10\%$ higher average test accuracy over QLoRA, with only $9\%$ more FLOPs. On a Llama model with $34$ billion parameters, an ensemble of QLoRA increases test accuracy by $3\%$ compared to QLoRA, with only $8\%$ more FLOPs.
Scalable Fine-tuning from Multiple Data Sources:A First-Order Approximation Approach
Sep 28, 2024We study the problem of fine-tuning a language model (LM) for a target task by optimally using the information from $n$ auxiliary tasks. This problem has broad applications in NLP, such as targeted instruction tuning and data selection in chain-of-thought fine-tuning. The key challenge of this problem is that not all auxiliary tasks are useful to improve the performance of the target task. Thus, choosing the right subset of auxiliary tasks is crucial. Conventional subset selection methods, such as forward & backward selection, are unsuitable for LM fine-tuning because they require repeated training on subsets of auxiliary tasks. This paper introduces a new algorithm to estimate model fine-tuning performances without repeated training. Our algorithm first performs multitask training using the data of all the tasks to obtain a meta initialization. Then, we approximate the model fine-tuning loss of a subset using functional values and gradients from the meta initialization. Empirically, we find that this gradient-based approximation holds with remarkable accuracy for twelve transformer-based LMs. Thus, we can now estimate fine-tuning performances on CPUs within a few seconds. We conduct extensive experiments to validate our approach, delivering a speedup of $30\times$ over conventional subset selection while incurring only $1\%$ error of the true fine-tuning performances. In downstream evaluations of instruction tuning and chain-of-thought fine-tuning, our approach improves over prior methods that utilize gradient or representation similarity for subset selection by up to $3.8\%$.
MMInA: Benchmarking Multihop Multimodal Internet Agents
Apr 15, 2024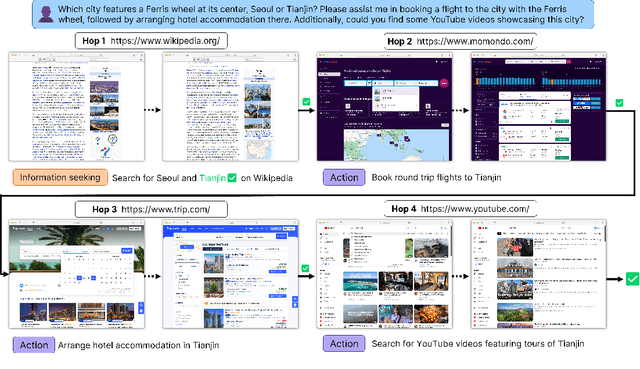
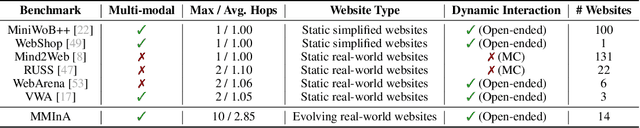
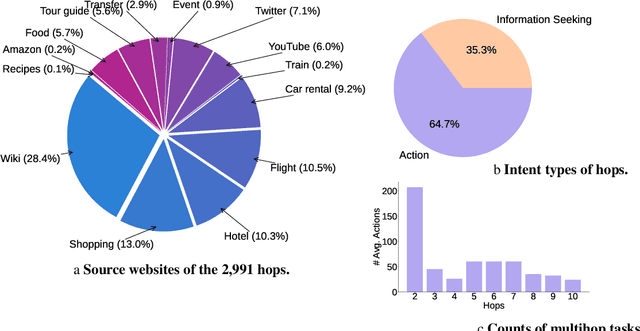

Autonomous embodied agents live on an Internet of multimedia websites. Can they hop around multimodal websites to complete complex user tasks? Existing benchmarks fail to assess them in a realistic, evolving environment for their embodiment across websites. To answer this question, we present MMInA, a multihop and multimodal benchmark to evaluate the embodied agents for compositional Internet tasks, with several appealing properties: 1) Evolving real-world multimodal websites. Our benchmark uniquely operates on evolving real-world websites, ensuring a high degree of realism and applicability to natural user tasks. Our data includes 1,050 human-written tasks covering various domains such as shopping and travel, with each task requiring the agent to autonomously extract multimodal information from web pages as observations; 2) Multihop web browsing. Our dataset features naturally compositional tasks that require information from or actions on multiple websites to solve, to assess long-range reasoning capabilities on web tasks; 3) Holistic evaluation. We propose a novel protocol for evaluating an agent's progress in completing multihop tasks. We experiment with both standalone (multimodal) language models and heuristic-based web agents. Extensive experiments demonstrate that while long-chain multihop web tasks are easy for humans, they remain challenging for state-of-the-art web agents. We identify that agents are more likely to fail on the early hops when solving tasks of more hops, which results in lower task success rates. To address this issue, we propose a simple memory augmentation approach replaying past action trajectories to reflect. Our method significantly improved both the single-hop and multihop web browsing abilities of agents. See our code and data at https://mmina.cliangyu.com