 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Baseline for Streaming Video Understanding
Apr 02, 2026Recent streaming video understanding methods increasingly rely on complex memory mechanisms to handle long video streams. We challenge this trend with a simple finding: a sliding-window baseline that feeds only the most recent N frames to an off-the-shelf VLM already matches or surpasses published streaming models. We formalize this baseline as SimpleStream and evaluate it against 13 major offline and online video LLM baselines on OVO-Bench and StreamingBench. Despite its simplicity, SimpleStream delivers consistently strong performance. With only 4 recent frames, it reaches 67.7% average accuracy on OVO-Bench and 80.59% on StreamingBench. Controlled ablations further show that the value of longer context is backbone-dependent rather than uniformly increasing with model scale, and reveal a consistent perception-memory trade-off: adding more historical context can improve recall, but often weakens real-time perception. This suggests that stronger memory, retrieval, or compression modules should not be taken as evidence of progress unless they clearly outperform SimpleStream under the same protocol. We therefore argue that future streaming benchmarks should separate recent-scene perception from long-range memory, so that performance improvements from added complexity can be evaluated more clearly.
HippoCamp: Benchmarking Contextual Agents on Personal Computers
Apr 01, 2026We present HippoCamp, a new benchmark designed to evaluate agents' capabilities on multimodal file management. Unlike existing agent benchmarks that focus on tasks like web interaction, tool use, or software automation in generic settings, HippoCamp evaluates agents in user-centric environments to model individual user profiles and search massive personal files for context-aware reasoning. Our benchmark instantiates device-scale file systems over real-world profiles spanning diverse modalities, comprising 42.4 GB of data across over 2K real-world files. Building upon the raw files, we construct 581 QA pairs to assess agents' capabilities in search, evidence perception, and multi-step reasoning. To facilitate fine-grained analysis, we provide 46.1K densely annotated structured trajectories for step-wise failure diagnosis. We evaluate a wide range of state-of-the-art multimodal large language models (MLLMs) and agentic methods on HippoCamp. Our comprehensive experiments reveal a significant performance gap: even the most advanced commercial models achieve only 48.3% accuracy in user profiling, struggling particularly with long-horizon retrieval and cross-modal reasoning within dense personal file systems. Furthermore, our step-wise failure diagnosis identifies multimodal perception and evidence grounding as the primary bottlenecks. Ultimately, HippoCamp exposes the critical limitations of current agents in realistic, user-centric environments and provides a robust foundation for developing next-generation personal AI assistants.
PerceptionComp: A Video Benchmark for Complex Perception-Centric Reasoning
Mar 27, 2026We introduce PerceptionComp, a manually annotated benchmark for complex, long-horizon, perception-centric video reasoning. PerceptionComp is designed so that no single moment is sufficient: answering each question requires multiple temporally separated pieces of visual evidence and compositional constraints under conjunctive and sequential logic, spanning perceptual subtasks such as objects, attributes, relations, locations, actions, and events, and requiring skills including semantic recognition, visual correspondence, temporal reasoning, and spatial reasoning. The benchmark contains 1,114 highly complex questions on 279 videos from diverse domains including city walk tours, indoor villa tours, video games, and extreme outdoor sports, with 100% manual annotation. Human studies show that PerceptionComp requires substantial test-time thinking and repeated perception steps: participants take much longer than on prior benchmarks, and accuracy drops to near chance (18.97%) when rewatching is disallowed. State-of-the-art MLLMs also perform substantially worse on PerceptionComp than on existing benchmarks: the best model in our evaluation, Gemini-3-Flash, reaches only 45.96% accuracy in the five-choice setting, while open-source models remain below 40%. These results suggest that perception-centric long-horizon video reasoning remains a major bottleneck, and we hope PerceptionComp will help drive progress in perceptual reasoning.
Insight-V++: Towards Advanced Long-Chain Visual Reasoning with Multimodal Large Language Models
Mar 18, 2026Large Language Models (LLMs) have achieved remarkable reliability and advanced capabilities through extended test-time reasoning. However, extending these capabilities to Multi-modal Large Language Models (MLLMs) remains a significant challenge due to a critical scarcity of high-quality, long-chain reasoning data and optimized training pipelines. To bridge this gap, we present a unified multi-agent visual reasoning framework that systematically evolves from our foundational image-centric model, Insight-V, into a generalized spatial-temporal architecture, Insight-V++. We first propose a scalable data generation pipeline equipped with multi-granularity assessment that autonomously synthesizes structured, complex reasoning trajectories across image and video domains without human intervention. Recognizing that directly supervising MLLMs with such intricate data yields sub-optimal results, we design a dual-agent architecture comprising a reasoning agent to execute extensive analytical chains, and a summary agent to critically evaluate and distill final outcomes. While our initial framework utilized Direct Preference Optimization (DPO), its off-policy nature fundamentally constrained reinforcement learning potential. To overcome these limitations, particularly for long-horizon video understanding, Insight-V++ introduces two novel algorithms, ST-GRPO and J-GRPO, which enhance spatial-temporal reasoning and improve evaluative robustness. Crucially, by leveraging reliable feedback from the summary agent, we guide an iterative reasoning path generation process, retraining the entire multi-agent system in a continuous, self-improving loop. Extensive experiments on base models like LLaVA-NeXT and Qwen2.5-VL demonstrate significant performance gains across challenging image and video reasoning benchmarks while preserving strong capabilities on traditional perception-focused tasks.
Demo-ICL: In-Context Learning for Procedural Video Knowledge Acquisition
Feb 09, 2026Despite the growing video understanding capabilities of recent Multimodal Large Language Models (MLLMs), existing video benchmarks primarily assess understanding based on models' static, internal knowledge, rather than their ability to learn and adapt from dynamic, novel contexts from few examples. To bridge this gap, we present Demo-driven Video In-Context Learning, a novel task focused on learning from in-context demonstrations to answer questions about the target videos. Alongside this, we propose Demo-ICL-Bench, a challenging benchmark designed to evaluate demo-driven video in-context learning capabilities. Demo-ICL-Bench is constructed from 1200 instructional YouTube videos with associated questions, from which two types of demonstrations are derived: (i) summarizing video subtitles for text demonstration; and (ii) corresponding instructional videos as video demonstrations. To effectively tackle this new challenge, we develop Demo-ICL, an MLLM with a two-stage training strategy: video-supervised fine-tuning and information-assisted direct preference optimization, jointly enhancing the model's ability to learn from in-context examples. Extensive experiments with state-of-the-art MLLMs confirm the difficulty of Demo-ICL-Bench, demonstrate the effectiveness of Demo-ICL, and thereby unveil future research directions.
Ego-R1: Chain-of-Tool-Thought for Ultra-Long Egocentric Video Reasoning
Jun 16, 2025We introduce Ego-R1, a novel framework for reasoning over ultra-long (i.e., in days and weeks) egocentric videos, which leverages a structured Chain-of-Tool-Thought (CoTT) process, orchestrated by an Ego-R1 Agent trained via reinforcement learning (RL). Inspired by human problem-solving strategies, CoTT decomposes complex reasoning into modular steps, with the RL agent invoking specific tools, one per step, to iteratively and collaboratively answer sub-questions tackling such tasks as temporal retrieval and multi-modal understanding. We design a two-stage training paradigm involving supervised finetuning (SFT) of a pretrained language model using CoTT data and RL to enable our agent to dynamically propose step-by-step tools for long-range reasoning. To facilitate training, we construct a dataset called Ego-R1 Data, which consists of Ego-CoTT-25K for SFT and Ego-QA-4.4K for RL. Furthermore, our Ego-R1 agent is evaluated on a newly curated week-long video QA benchmark, Ego-R1 Bench, which contains human-verified QA pairs from hybrid sources. Extensive results demonstrate that the dynamic, tool-augmented chain-of-thought reasoning by our Ego-R1 Agent can effectively tackle the unique challenges of understanding ultra-long egocentric videos, significantly extending the time coverage from few hours to a week.
Evaluation Agent: Efficient and Promptable Evaluation Framework for Visual Generative Models
Dec 10, 2024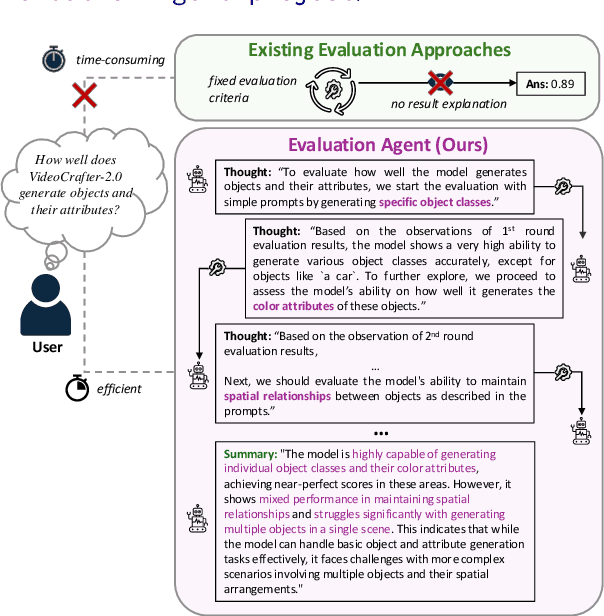

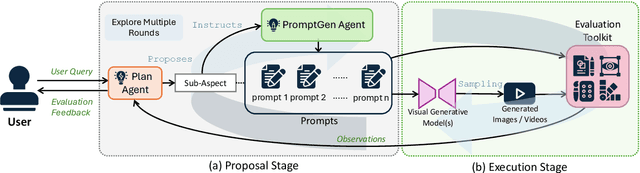
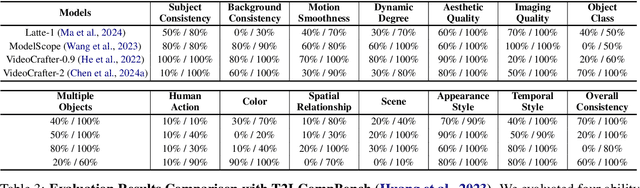
Recent advancements in visual generative models have enabled high-quality image and video generation, opening diverse applications. However, evaluating these models often demands sampling hundreds or thousands of images or videos, making the process computationally expensive, especially for diffusion-based models with inherently slow sampling. Moreover, existing evaluation methods rely on rigid pipelines that overlook specific user needs and provide numerical results without clear explanations. In contrast, humans can quickly form impressions of a model's capabilities by observing only a few samples. To mimic this, we propose the Evaluation Agent framework, which employs human-like strategies for efficient, dynamic, multi-round evaluations using only a few samples per round, while offering detailed, user-tailored analyses. It offers four key advantages: 1) efficiency, 2) promptable evaluation tailored to diverse user needs, 3) explainability beyond single numerical scores, and 4) scalability across various models and tools. Experiments show that Evaluation Agent reduces evaluation time to 10% of traditional methods while delivering comparable results. The Evaluation Agent framework is fully open-sourced to advance research in visual generative models and their efficient evaluation.
AHA: A Vision-Language-Model for Detecting and Reasoning Over Failures in Robotic Manipulation
Oct 01, 2024



Robotic manipulation in open-world settings requires not only task execution but also the ability to detect and learn from failures. While recent advances in vision-language models (VLMs) and large language models (LLMs) have improved robots' spatial reasoning and problem-solving abilities, they still struggle with failure recognition, limiting their real-world applicability. We introduce AHA, an open-source VLM designed to detect and reason about failures in robotic manipulation using natural language. By framing failure detection as a free-form reasoning task, AHA identifies failures and provides detailed, adaptable explanations across different robots, tasks, and environments. We fine-tuned AHA using FailGen, a scalable framework that generates the first large-scale dataset of robotic failure trajectories, the AHA dataset. FailGen achieves this by procedurally perturbing successful demonstrations from simulation. Despite being trained solely on the AHA dataset, AHA generalizes effectively to real-world failure datasets, robotic systems, and unseen tasks. It surpasses the second-best model (GPT-4o in-context learning) by 10.3% and exceeds the average performance of six compared models including five state-of-the-art VLMs by 35.3% across multiple metrics and datasets. We integrate AHA into three manipulation frameworks that utilize LLMs/VLMs for reinforcement learning, task and motion planning, and zero-shot trajectory generation. AHA's failure feedback enhances these policies' performances by refining dense reward functions, optimizing task planning, and improving sub-task verification, boosting task success rates by an average of 21.4% across all three tasks compared to GPT-4 models.
MMInA: Benchmarking Multihop Multimodal Internet Agents
Apr 15, 2024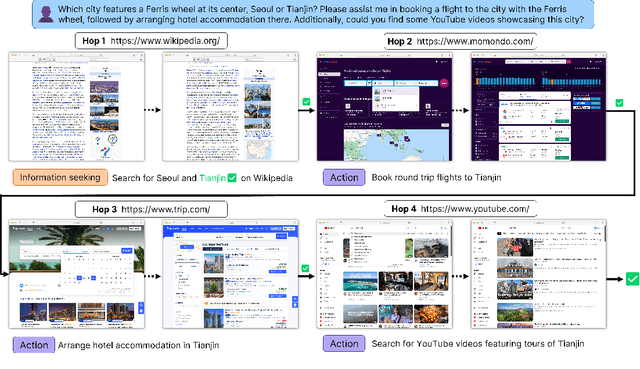
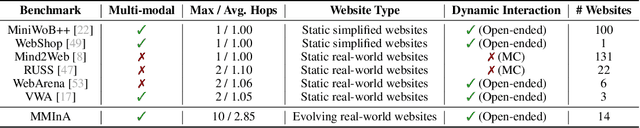
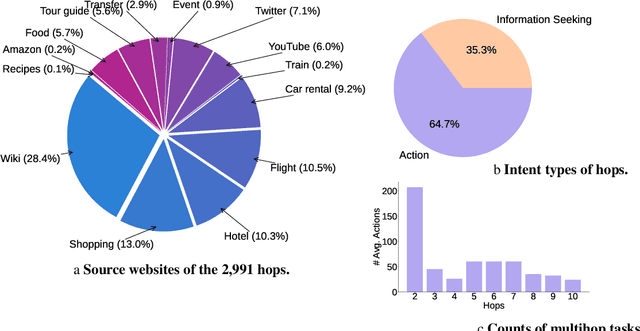

Autonomous embodied agents live on an Internet of multimedia websites. Can they hop around multimodal websites to complete complex user tasks? Existing benchmarks fail to assess them in a realistic, evolving environment for their embodiment across websites. To answer this question, we present MMInA, a multihop and multimodal benchmark to evaluate the embodied agents for compositional Internet tasks, with several appealing properties: 1) Evolving real-world multimodal websites. Our benchmark uniquely operates on evolving real-world websites, ensuring a high degree of realism and applicability to natural user tasks. Our data includes 1,050 human-written tasks covering various domains such as shopping and travel, with each task requiring the agent to autonomously extract multimodal information from web pages as observations; 2) Multihop web browsing. Our dataset features naturally compositional tasks that require information from or actions on multiple websites to solve, to assess long-range reasoning capabilities on web tasks; 3) Holistic evaluation. We propose a novel protocol for evaluating an agent's progress in completing multihop tasks. We experiment with both standalone (multimodal) language models and heuristic-based web agents. Extensive experiments demonstrate that while long-chain multihop web tasks are easy for humans, they remain challenging for state-of-the-art web agents. We identify that agents are more likely to fail on the early hops when solving tasks of more hops, which results in lower task success rates. To address this issue, we propose a simple memory augmentation approach replaying past action trajectories to reflect. Our method significantly improved both the single-hop and multihop web browsing abilities of agents. See our code and data at https://mmina.cliangyu.com
Enhancing Low-Light Images Using Infrared-Encoded Images
Jul 09, 2023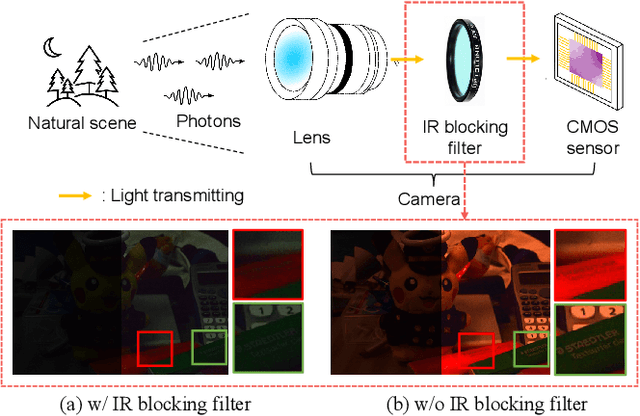
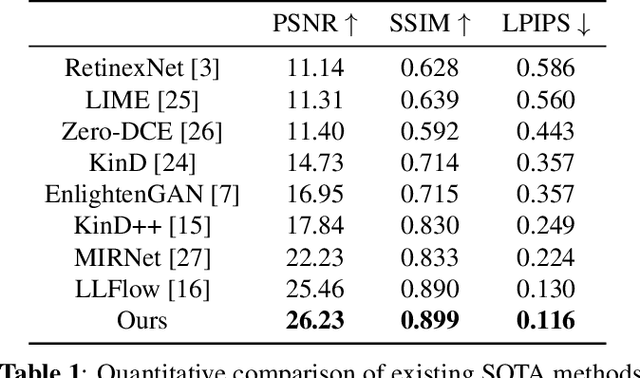

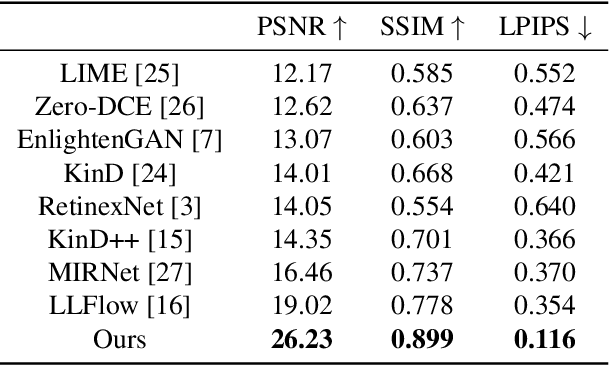
Low-light image enhancement task is essential yet challenging as it is ill-posed intrinsically. Previous arts mainly focus on the low-light images captured in the visible spectrum using pixel-wise loss, which limits the capacity of recovering the brightness, contrast, and texture details due to the small number of income photons. In this work, we propose a novel approach to increase the visibility of images captured under low-light environments by removing the in-camera infrared (IR) cut-off filter, which allows for the capture of more photons and results in improved signal-to-noise ratio due to the inclusion of information from the IR spectrum. To verify the proposed strategy, we collect a paired dataset of low-light images captured without the IR cut-off filter, with corresponding long-exposure reference images with an external filter. The experimental results on the proposed dataset demonstrate the effectiveness of the proposed method, showing better performance quantitatively and qualitatively. The dataset and code are publicly available at https://wyf0912.github.io/ELIEI/