 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMove-Then-Operate: Behavioral Phasing for Human-Like Robotic Manipulation
Apr 26, 2026We present Move-Then-Operate, a Vision language action framework that explicitly decouples robotic manipulation into two distinct behavioral phases: coarse relocation (move) and contact-critical interaction (operate). Unlike monolithic policies that conflate these heterogeneous regimes, our architecture employs a dual-expert policy routed by a learnable phase selector, introducing a structural inductive bias that isolates phase-specific dynamics. Phase labels are automatically generated via an MLLM-based pipeline conditioned on lightweight contextual cues such as end-effector velocity and subtask decomposition to ensure alignment with human motor patterns. Evaluated on the RoboTwin2 benchmark, our method achieves an average success rate of $68.9\%$, outperforming the monolithic $π_0$ baseline by $24\%$. It matches or exceeds models trained on $10\times$ more data and reaches peak performance in $40\%$ fewer training steps, demonstrating that architectural disentanglement of move and operate phases is a highly effective and efficient strategy for mastering high-precision manipulation.
MapSR: Prompt-Driven Land Cover Map Super-Resolution via Vision Foundation Models
Apr 16, 2026High-resolution (HR) land-cover mapping is often constrained by the high cost of dense HR annotations. We revisit this problem from the perspective of map super-resolution, which enhances coarse low-resolution (LR) land-cover products into HR maps at the resolution of the input imagery. Existing weakly supervised methods can leverage LR labels, but they typically use them to retrain dense predictors with substantial computational cost. We propose MapSR, a prompt-driven framework that decouples supervision from model training. MapSR uses LR labels once to extract class prompts from frozen vision foundation model features through a lightweight linear probe, after which HR mapping proceeds via training-free metric inference and graph-based prediction refinement. Specifically, class prompts are estimated by aggregating high-confidence HR features identified by the linear probe, and HR predictions are obtained by cosine-similarity matching followed by graph-based propagation for spatial refinement. Experiments on the Chesapeake Bay dataset show that MapSR achieves 59.64% mIoU without any HR labels, remaining competitive with the strongest weakly supervised baseline and surpassing a fully supervised baseline. Notably, MapSR reduces trainable parameters by four orders of magnitude and shortens training time from hours to minutes, enabling scalable HR mapping under limited annotation and compute budgets. The code is available at https://github.com/rikirikirikiriki/MapSR.
Pre-Execution Safety Gate & Task Safety Contracts for LLM-Controlled Robot Systems
Apr 07, 2026Large Language Models (LLMs) are increasingly used to convert task commands into robot-executable code, however this pipeline lacks validation gates to detect unsafe and defective commands before they are translated into robot code. Furthermore, even commands that appear safe at the outset can produce unsafe state transitions during execution in the absence of continuous constraint monitoring. In this research, we introduce SafeGate, a neurosymbolic safety architecture that prevents unsafe natural language task commands from reaching robot execution. Drawing from ISO 13482 safety standard, SafeGate extracts structured safety-relevant properties from natural language commands and applies a deterministic decision gate to authorize or reject execution. In addition, we introduce Task Safety Contracts, which decomposes commands that pass through the gate into invariants, guards, and abort conditions to prevent unsafe state transitions during execution. We further incorporate Z3 SMT solving to enforce constraint checking derived from the Task Safety Contracts. We evaluate SafeGate against existing LLM-based robot safety frameworks and baseline LLMs across 230 benchmark tasks, 30 AI2-THOR simulation scenarios, and real-world robot experiments. Results show that SafeGate significantly reduces the acceptance of defective commands while maintaining a high acceptance of benign tasks, demonstrating the importance of pre-execution safety gates for LLM-controlled robot systems
CausalTAD: Injecting Causal Knowledge into Large Language Models for Tabular Anomaly Detection
Feb 08, 2026Detecting anomalies in tabular data is critical for many real-world applications, such as credit card fraud detection. With the rapid advancements in large language models (LLMs), state-of-the-art performance in tabular anomaly detection has been achieved by converting tabular data into text and fine-tuning LLMs. However, these methods randomly order columns during conversion, without considering the causal relationships between them, which is crucial for accurately detecting anomalies. In this paper, we present CausalTaD, a method that injects causal knowledge into LLMs for tabular anomaly detection. We first identify the causal relationships between columns and reorder them to align with these causal relationships. This reordering can be modeled as a linear ordering problem. Since each column contributes differently to the causal relationships, we further propose a reweighting strategy to assign different weights to different columns to enhance this effect. Experiments across more than 30 datasets demonstrate that our method consistently outperforms the current state-of-the-art methods. The code for CausalTAD is available at https://github.com/350234/CausalTAD.
Transformer-based Hybrid Beamforming with Dynamic Subarray for Near-Space Airship-Borne Communications
Feb 07, 2026This paper proposes a hybrid beamforming framework for massive multiple-input multiple-output (MIMO) in near-space airship-borne communications. To achieve high energy efficiency (EE) in energy-constraint airships, a dynamic subarray structure is introduced, where each radio frequency chain (RFC) is connected to a disjoint subset of the antennas according to channel state information (CSI). The proposed joint dynamic hybrid beamforming network (DyHBFNet) comprises three key components: 1) An analog beamforming network (ABFNet) that optimizes the analog beamforming matrices and provides auxiliary information for the antenna selection network (ASNet) design, 2) an ASNet that dynamically optimizes the connections between antennas and RFCs, and 3) a digital beamforming network (DBFNet) that optimizes digital beamforming matrices by employing a model-driven weighted minimum mean square error algorithm for improving beamforming performance and convergence speed. The proposed ABFNet, ASNet, and DBFNet are all designed based on advanced Transformer encoders. Simulation results demonstrate that the proposed framework significantly enhances spectral efficiency and EE compared to baseline schemes. Additionally, its robust performance under imperfect CSI makes it a scalable solution for practical implementations.
Two-Layer Reinforcement Learning-Assisted Joint Beamforming and Trajectory Optimization for Multi-UAV Downlink Communications
Jan 19, 2026Unmanned aerial vehicles (UAVs) are pivotal for future 6G non-terrestrial networks, yet their high mobility creates a complex coupled optimization problem for beamforming and trajectory design. Existing numerical methods suffer from prohibitive latency, while standard deep learning often ignores dynamic interference topology, limiting scalability. To address these issues, this paper proposes a hierarchically decoupled framework synergizing graph neural networks (GNNs) with multi-agent reinforcement learning. Specifically, on the short timescale, we develop a topology-aware GNN beamformer by incorporating GraphNorm. By modeling the dynamic UAV-user association as a time-varying heterogeneous graph, this method explicitly extracts interference patterns to achieve sub-millisecond inference. On the long timescale, trajectory planning is modeled as a decentralized partially observable Markov decision process and solved via the multi-agent proximal policy optimization algorithm under the centralized training with decentralized execution paradigm, facilitating cooperative behaviors. Extensive simulation results demonstrate that the proposed framework significantly outperforms state-of-the-art optimization heuristics and deep learning baselines in terms of system sum rate, convergence speed, and generalization capability.
AXIOM: Benchmarking LLM-as-a-Judge for Code via Rule-Based Perturbation and Multisource Quality Calibration
Dec 23, 2025Large language models (LLMs) have been increasingly deployed in real-world software engineering, fostering the development of code evaluation metrics to study the quality of LLM-generated code. Conventional rule-based metrics merely score programs based on their surface-level similarities with reference programs instead of analyzing functionality and code quality in depth. To address this limitation, researchers have developed LLM-as-a-judge metrics, prompting LLMs to evaluate and score code, and curated various code evaluation benchmarks to validate their effectiveness. However, these benchmarks suffer from critical limitations, hindering reliable assessments of evaluation capability: Some feature coarse-grained binary labels, which reduce rich code behavior to a single bit of information, obscuring subtle errors. Others propose fine-grained but subjective, vaguely-defined evaluation criteria, introducing unreliability in manually-annotated scores, which is the ground-truth they rely on. Furthermore, they often use uncontrolled data synthesis methods, leading to unbalanced score distributions that poorly represent real-world code generation scenarios. To curate a diverse benchmark with programs of well-balanced distributions across various quality levels and streamline the manual annotation procedure, we propose AXIOM, a novel perturbation-based framework for synthesizing code evaluation benchmarks at scale. It reframes program scores as the refinement effort needed for deployment, consisting of two stages: (1) Rule-guided perturbation, which prompts LLMs to apply sequences of predefined perturbation rules to existing high-quality programs to modify their functionality and code quality, enabling us to precisely control each program's target score to achieve balanced score distributions. (2) Multisource quality calibration, which first selects a subset of...
Distinguishing Visually Similar Actions: Prompt-Guided Semantic Prototype Modulation for Few-Shot Action Recognition
Dec 22, 2025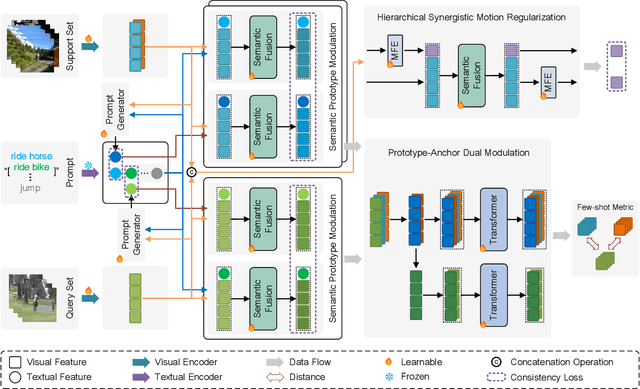
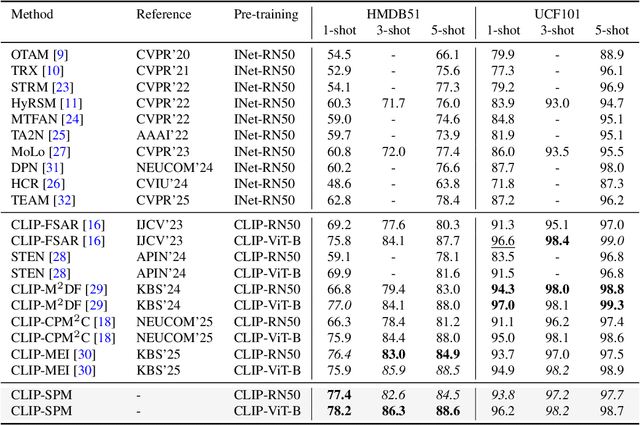
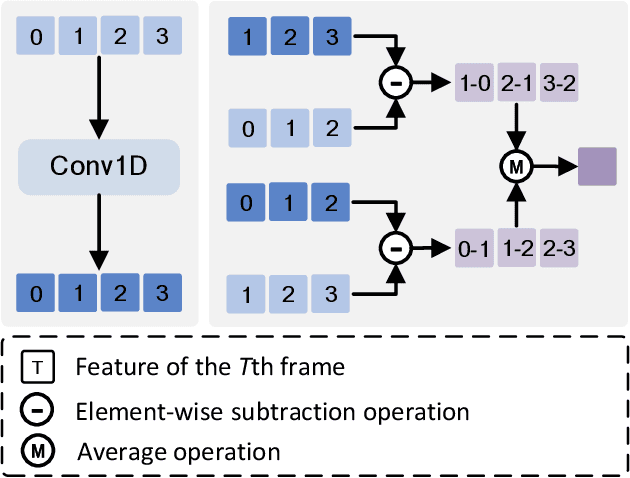
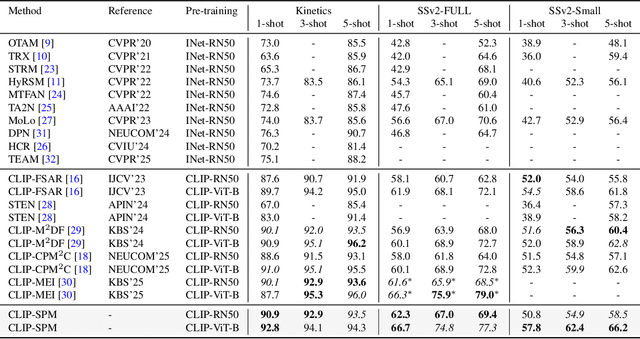
Few-shot action recognition aims to enable models to quickly learn new action categories from limited labeled samples, addressing the challenge of data scarcity in real-world applications. Current research primarily addresses three core challenges: (1) temporal modeling, where models are prone to interference from irrelevant static background information and struggle to capture the essence of dynamic action features; (2) visual similarity, where categories with subtle visual differences are difficult to distinguish; and (3) the modality gap between visual-textual support prototypes and visual-only queries, which complicates alignment within a shared embedding space. To address these challenges, this paper proposes a CLIP-SPM framework, which includes three components: (1) the Hierarchical Synergistic Motion Refinement (HSMR) module, which aligns deep and shallow motion features to improve temporal modeling by reducing static background interference; (2) the Semantic Prototype Modulation (SPM) strategy, which generates query-relevant text prompts to bridge the modality gap and integrates them with visual features, enhancing the discriminability between similar actions; and (3) the Prototype-Anchor Dual Modulation (PADM) method, which refines support prototypes and aligns query features with a global semantic anchor, improving consistency across support and query samples. Comprehensive experiments across standard benchmarks, including Kinetics, SSv2-Full, SSv2-Small, UCF101, and HMDB51, demonstrate that our CLIP-SPM achieves competitive performance under 1-shot, 3-shot, and 5-shot settings. Extensive ablation studies and visual analyses further validate the effectiveness of each component and its contributions to addressing the core challenges. The source code and models are publicly available at GitHub.
LiNeXt: Revisiting LiDAR Completion with Efficient Non-Diffusion Architectures
Nov 13, 20253D LiDAR scene completion from point clouds is a fundamental component of perception systems in autonomous vehicles. Previous methods have predominantly employed diffusion models for high-fidelity reconstruction. However, their multi-step iterative sampling incurs significant computational overhead, limiting its real-time applicability. To address this, we propose LiNeXt-a lightweight, non-diffusion network optimized for rapid and accurate point cloud completion. Specifically, LiNeXt first applies the Noise-to-Coarse (N2C) Module to denoise the input noisy point cloud in a single pass, thereby obviating the multi-step iterative sampling of diffusion-based methods. The Refine Module then takes the coarse point cloud and its intermediate features from the N2C Module to perform more precise refinement, further enhancing structural completeness. Furthermore, we observe that LiDAR point clouds exhibit a distance-dependent spatial distribution, being densely sampled at proximal ranges and sparsely sampled at distal ranges. Accordingly, we propose the Distance-aware Selected Repeat strategy to generate a more uniformly distributed noisy point cloud. On the SemanticKITTI dataset, LiNeXt achieves a 199.8x speedup in inference, reduces Chamfer Distance by 50.7%, and uses only 6.1% of the parameters compared with LiDiff. These results demonstrate the superior efficiency and effectiveness of LiNeXt for real-time scene completion.
QoSGMAA: A Robust Multi-Order Graph Attention and Adversarial Framework for Sparse QoS Prediction
Oct 27, 2025
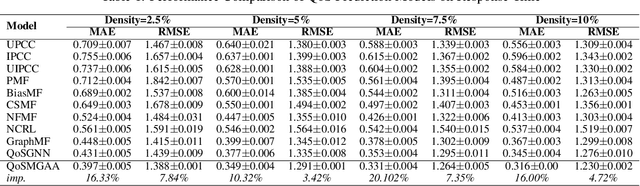


With the rapid advancement of internet technologies, network services have become critical for delivering diverse and reliable applications to users. However, the exponential growth in the number of available services has resulted in many similar offerings, posing significant challenges in selecting optimal services. Predicting Quality of Service (QoS) accurately thus becomes a fundamental prerequisite for ensuring reliability and user satisfaction. However, existing QoS prediction methods often fail to capture rich contextual information and exhibit poor performance under extreme data sparsity and structural noise. To bridge this gap, we propose a novel architecture, QoSMGAA, specifically designed to enhance prediction accuracy in complex and noisy network service environments. QoSMGAA integrates a multi-order attention mechanism to aggregate extensive contextual data and predict missing QoS values effectively. Additionally, our method incorporates adversarial neural networks to perform autoregressive supervised learning based on transformed interaction matrices. To capture complex, higher-order interactions among users and services, we employ a discrete sampling technique leveraging the Gumbel-Softmax method to generate informative negative samples. Comprehensive experimental validation conducted on large-scale real-world datasets demonstrates that our proposed model significantly outperforms existing baseline methods, highlighting its strong potential for practical deployment in service selection and recommendation scenarios.