 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Execution Safety Gate & Task Safety Contracts for LLM-Controlled Robot Systems
Apr 07, 2026Large Language Models (LLMs) are increasingly used to convert task commands into robot-executable code, however this pipeline lacks validation gates to detect unsafe and defective commands before they are translated into robot code. Furthermore, even commands that appear safe at the outset can produce unsafe state transitions during execution in the absence of continuous constraint monitoring. In this research, we introduce SafeGate, a neurosymbolic safety architecture that prevents unsafe natural language task commands from reaching robot execution. Drawing from ISO 13482 safety standard, SafeGate extracts structured safety-relevant properties from natural language commands and applies a deterministic decision gate to authorize or reject execution. In addition, we introduce Task Safety Contracts, which decomposes commands that pass through the gate into invariants, guards, and abort conditions to prevent unsafe state transitions during execution. We further incorporate Z3 SMT solving to enforce constraint checking derived from the Task Safety Contracts. We evaluate SafeGate against existing LLM-based robot safety frameworks and baseline LLMs across 230 benchmark tasks, 30 AI2-THOR simulation scenarios, and real-world robot experiments. Results show that SafeGate significantly reduces the acceptance of defective commands while maintaining a high acceptance of benign tasks, demonstrating the importance of pre-execution safety gates for LLM-controlled robot systems
Game-Based and Gamified Robotics Education: A Comparative Systematic Review and Design Guidelines
Jan 29, 2026Robotics education fosters computational thinking, creativity, and problem-solving, but remains challenging due to technical complexity. Game-based learning (GBL) and gamification offer engagement benefits, yet their comparative impact remains unclear. We present the first PRISMA-aligned systematic review and comparative synthesis of GBL and gamification in robotics education, analyzing 95 studies from 12,485 records across four databases (2014-2025). We coded each study's approach, learning context, skill level, modality, pedagogy, and outcomes (k = .918). Three patterns emerged: (1) approach-context-pedagogy coupling (GBL more prevalent in informal settings, while gamification dominated formal classrooms [p < .001] and favored project-based learning [p = .009]); (2) emphasis on introductory programming and modular kits, with limited adoption of advanced software (~17%), advanced hardware (~5%), or immersive technologies (~22%); and (3) short study horizons, relying on self-report. We propose eight research directions and a design space outlining best practices and pitfalls, offering actionable guidance for robotics education.
PRIMT: Preference-based Reinforcement Learning with Multimodal Feedback and Trajectory Synthesis from Foundation Models
Sep 19, 2025Preference-based reinforcement learning (PbRL) has emerged as a promising paradigm for teaching robots complex behaviors without reward engineering. However, its effectiveness is often limited by two critical challenges: the reliance on extensive human input and the inherent difficulties in resolving query ambiguity and credit assignment during reward learning. In this paper, we introduce PRIMT, a PbRL framework designed to overcome these challenges by leveraging foundation models (FMs) for multimodal synthetic feedback and trajectory synthesis. Unlike prior approaches that rely on single-modality FM evaluations, PRIMT employs a hierarchical neuro-symbolic fusion strategy, integrating the complementary strengths of large language models and vision-language models in evaluating robot behaviors for more reliable and comprehensive feedback. PRIMT also incorporates foresight trajectory generation, which reduces early-stage query ambiguity by warm-starting the trajectory buffer with bootstrapped samples, and hindsight trajectory augmentation, which enables counterfactual reasoning with a causal auxiliary loss to improve credit assignment. We evaluate PRIMT on 2 locomotion and 6 manipulation tasks on various benchmarks, demonstrating superior performance over FM-based and scripted baselines.
Multi-Agent LLM Actor-Critic Framework for Social Robot Navigation
Mar 12, 2025Recent advances in robotics and large language models (LLMs) have sparked growing interest in human-robot collaboration and embodied intelligence. To enable the broader deployment of robots in human-populated environments, socially-aware robot navigation (SAN) has become a key research area. While deep reinforcement learning approaches that integrate human-robot interaction (HRI) with path planning have demonstrated strong benchmark performance, they often struggle to adapt to new scenarios and environments. LLMs offer a promising avenue for zero-shot navigation through commonsense inference. However, most existing LLM-based frameworks rely on centralized decision-making, lack robust verification mechanisms, and face inconsistencies in translating macro-actions into precise low-level control signals. To address these challenges, we propose SAMALM, a decentralized multi-agent LLM actor-critic framework for multi-robot social navigation. In this framework, a set of parallel LLM actors, each reflecting distinct robot personalities or configurations, directly generate control signals. These actions undergo a two-tier verification process via a global critic that evaluates group-level behaviors and individual critics that assess each robot's context. An entropy-based score fusion mechanism further enhances self-verification and re-query, improving both robustness and coordination. Experimental results confirm that SAMALM effectively balances local autonomy with global oversight, yielding socially compliant behaviors and strong adaptability across diverse multi-robot scenarios. More details and videos about this work are available at: https://sites.google.com/view/SAMALM.
SafePlan: Leveraging Formal Logic and Chain-of-Thought Reasoning for Enhanced Safety in LLM-based Robotic Task Planning
Mar 10, 2025



Robotics researchers increasingly leverage large language models (LLM) in robotics systems, using them as interfaces to receive task commands, generate task plans, form team coalitions, and allocate tasks among multi-robot and human agents. However, despite their benefits, the growing adoption of LLM in robotics has raised several safety concerns, particularly regarding executing malicious or unsafe natural language prompts. In addition, ensuring that task plans, team formation, and task allocation outputs from LLMs are adequately examined, refined, or rejected is crucial for maintaining system integrity. In this paper, we introduce SafePlan, a multi-component framework that combines formal logic and chain-of-thought reasoners for enhancing the safety of LLM-based robotics systems. Using the components of SafePlan, including Prompt Sanity COT Reasoner and Invariant, Precondition, and Postcondition COT reasoners, we examined the safety of natural language task prompts, task plans, and task allocation outputs generated by LLM-based robotic systems as means of investigating and enhancing system safety profile. Our results show that SafePlan outperforms baseline models by leading to 90.5% reduction in harmful task prompt acceptance while still maintaining reasonable acceptance of safe tasks.
EfficientEQA: An Efficient Approach for Open Vocabulary Embodied Question Answering
Oct 26, 2024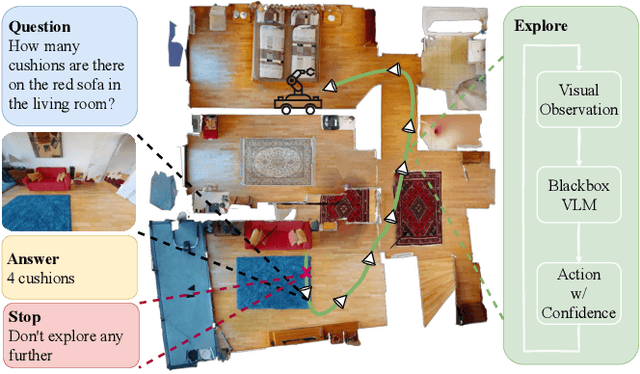
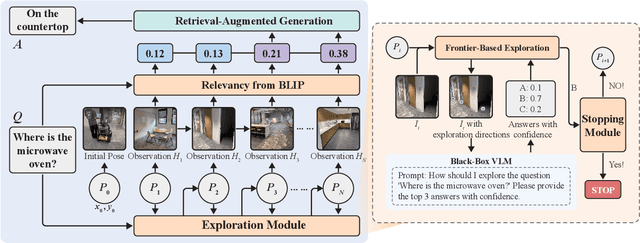
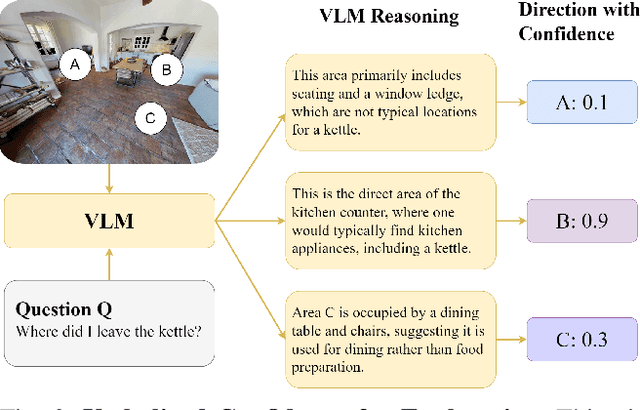
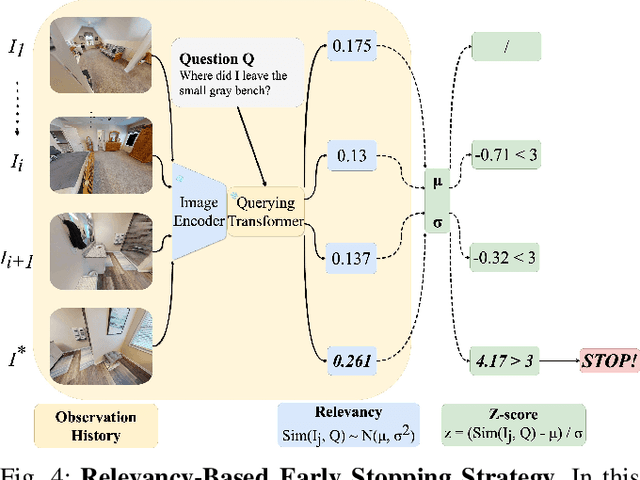
Embodied Question Answering (EQA) is an essential yet challenging task for robotic home assistants. Recent studies have shown that large vision-language models (VLMs) can be effectively utilized for EQA, but existing works either focus on video-based question answering without embodied exploration or rely on closed-form choice sets. In real-world scenarios, a robotic agent must efficiently explore and accurately answer questions in open-vocabulary settings. To address these challenges, we propose a novel framework called EfficientEQA for open-vocabulary EQA, which enables efficient exploration and accurate answering. In EfficientEQA, the robot actively explores unknown environments using Semantic-Value-Weighted Frontier Exploration, a strategy that prioritizes exploration based on semantic importance provided by calibrated confidence from black-box VLMs to quickly gather relevant information. To generate accurate answers, we employ Retrieval-Augmented Generation (RAG), which utilizes BLIP to retrieve useful images from accumulated observations and VLM reasoning to produce responses without relying on predefined answer choices. Additionally, we detect observations that are highly relevant to the question as outliers, allowing the robot to determine when it has sufficient information to stop exploring and provide an answer. Experimental results demonstrate the effectiveness of our approach, showing an improvement in answering accuracy by over 15% and efficiency, measured in running steps, by over 20% compared to state-of-the-art methods.
AuD-Former: A Hierarchical Transformer Network for Multimodal Audio-Based Disease Prediction
Oct 11, 2024



Audio-based disease prediction is emerging as a promising supplement to traditional medical diagnosis methods, facilitating early, convenient, and non-invasive disease detection and prevention. Multimodal fusion, which integrates features from various domains within or across bio-acoustic modalities, has proven effective in enhancing diagnostic performance. However, most existing methods in the field employ unilateral fusion strategies that focus solely on either intra-modal or inter-modal fusion. This approach limits the full exploitation of the complementary nature of diverse acoustic feature domains and bio-acoustic modalities. Additionally, the inadequate and isolated exploration of latent dependencies within modality-specific and modality-shared spaces curtails their capacity to manage the inherent heterogeneity in multimodal data. To fill these gaps, we propose AuD-Former, a hierarchical transformer network designed for general multimodal audio-based disease prediction. Specifically, we seamlessly integrate intra-modal and inter-modal fusion in a hierarchical manner and proficiently encode the necessary intra-modal and inter-modal complementary correlations, respectively. Comprehensive experiments demonstrate that AuD-Former achieves state-of-the-art performance in predicting three diseases: COVID-19, Parkinson's disease, and pathological dysarthria, showcasing its promising potential in a broad context of audio-based disease prediction tasks. Additionally, extensive ablation studies and qualitative analyses highlight the significant benefits of each main component within our model.
REBEL: Rule-based and Experience-enhanced Learning with LLMs for Initial Task Allocation in Multi-Human Multi-Robot Teams
Sep 24, 2024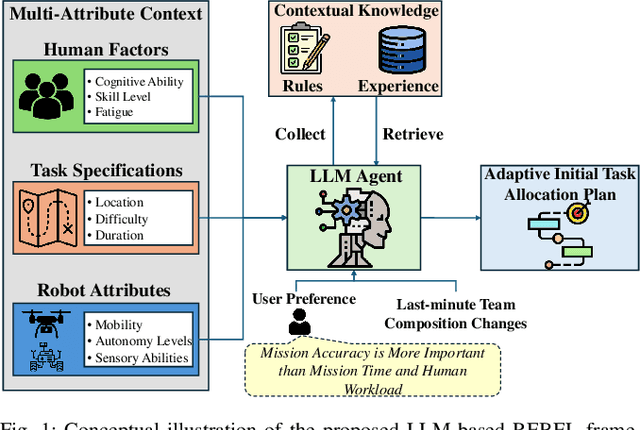
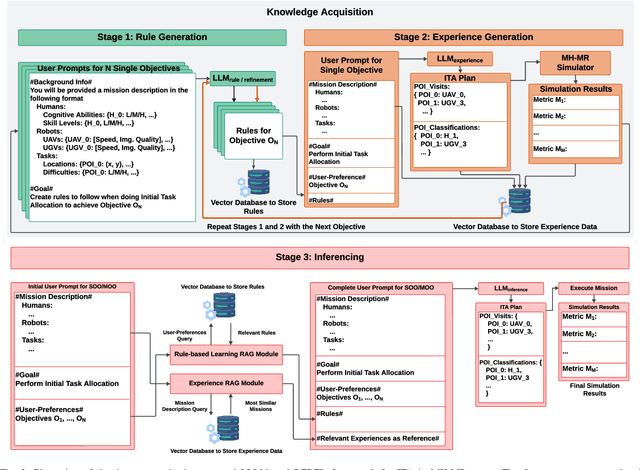
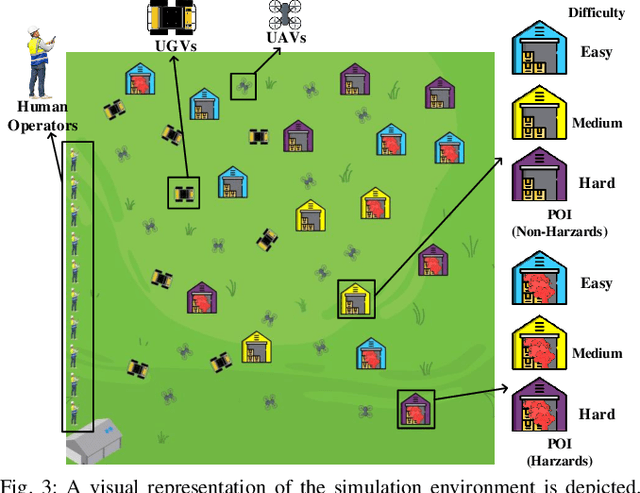
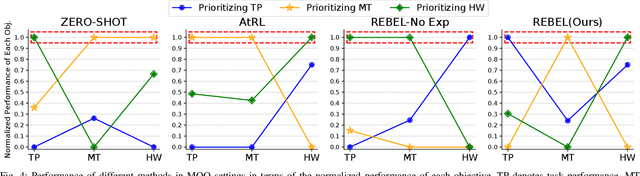
Multi-human multi-robot teams combine the complementary strengths of humans and robots to tackle complex tasks across diverse applications. However, the inherent heterogeneity of these teams presents significant challenges in initial task allocation (ITA), which involves assigning the most suitable tasks to each team member based on their individual capabilities before task execution. While current learning-based methods have shown promising results, they are often computationally expensive to train, and lack the flexibility to incorporate user preferences in multi-objective optimization and adapt to last-minute changes in real-world dynamic environments. To address these issues, we propose REBEL, an LLM-based ITA framework that integrates rule-based and experience-enhanced learning. By leveraging Retrieval-Augmented Generation, REBEL dynamically retrieves relevant rules and past experiences, enhancing reasoning efficiency. Additionally, REBEL can complement pre-trained RL-based ITA policies, improving situational awareness and overall team performance. Extensive experiments validate the effectiveness of our approach across various settings. More details are available at https://sites.google.com/view/ita-rebel .
Investigating the Impact of Trust in Multi-Human Multi-Robot Task Allocation
Sep 24, 2024



Trust is essential in human-robot collaboration. Even more so in multi-human multi-robot teams where trust is vital to ensure teaming cohesion in complex operational environments. Yet, at the moment, trust is rarely considered a factor during task allocation and reallocation in algorithms used in multi-human, multi-robot collaboration contexts. Prior work on trust in single-human-robot interaction has identified that including trust as a parameter in human-robot interaction significantly improves both performance outcomes and human experience with robotic systems. However, very little research has explored the impact of trust in multi-human multi-robot collaboration, specifically in the context of task allocation. In this paper, we introduce a new trust model, the Expectation Comparison Trust (ECT) model, and employ it with three trust models from prior work and a baseline no-trust model to investigate the impact of trust on task allocation outcomes in multi-human multi-robot collaboration. Our experiment involved different team configurations, including 2 humans, 2 robots, 5 humans, 5 robots, and 10 humans, 10 robots. Results showed that using trust-based models generally led to better task allocation outcomes in larger teams (10 humans and 10 robots) than in smaller teams. We discuss the implications of our findings and provide recommendations for future work on integrating trust as a variable for task allocation in multi-human, multi-robot collaboration.
PrefMMT: Modeling Human Preferences in Preference-based Reinforcement Learning with Multimodal Transformers
Sep 20, 2024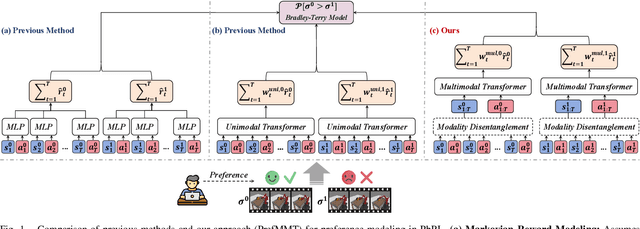
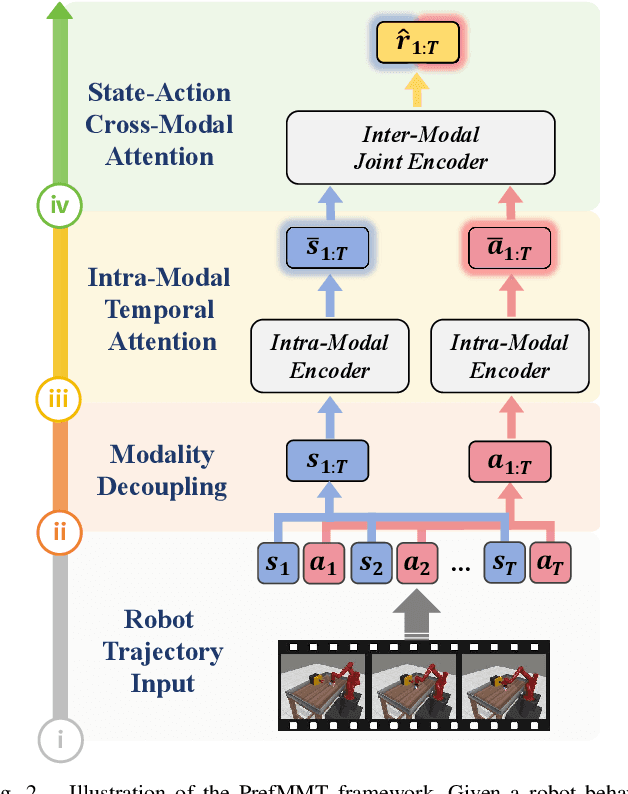
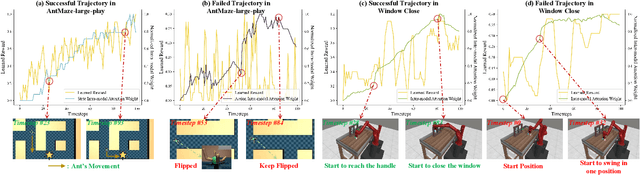
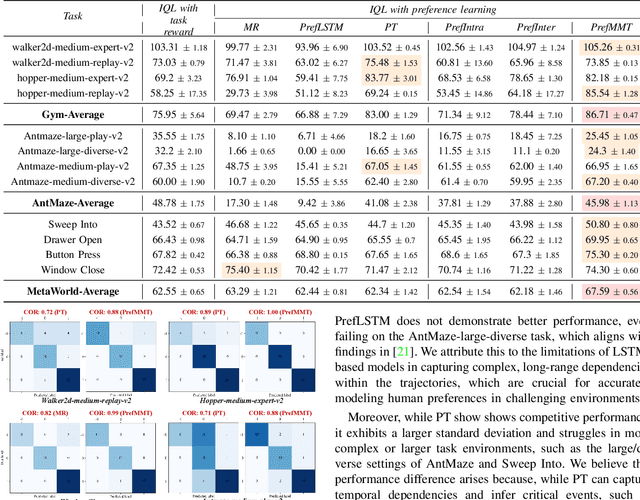
Preference-based reinforcement learning (PbRL) shows promise in aligning robot behaviors with human preferences, but its success depends heavily on the accurate modeling of human preferences through reward models. Most methods adopt Markovian assumptions for preference modeling (PM), which overlook the temporal dependencies within robot behavior trajectories that impact human evaluations. While recent works have utilized sequence modeling to mitigate this by learning sequential non-Markovian rewards, they ignore the multimodal nature of robot trajectories, which consist of elements from two distinctive modalities: state and action. As a result, they often struggle to capture the complex interplay between these modalities that significantly shapes human preferences. In this paper, we propose a multimodal sequence modeling approach for PM by disentangling state and action modalities. We introduce a multimodal transformer network, named PrefMMT, which hierarchically leverages intra-modal temporal dependencies and inter-modal state-action interactions to capture complex preference patterns. We demonstrate that PrefMMT consistently outperforms state-of-the-art PM baselines on locomotion tasks from the D4RL benchmark and manipulation tasks from the Meta-World benchmark.