 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Really Need Quantum Machine Learning?: A Multidimensional Empirical Study
May 27, 2026The rapid growth of computer vision and increasingly complex image recognition tasks has exposed fundamental computational limitations of classical machine learning models, motivating the exploration of quantum computing as an emerging new paradigm. This paper presents a comprehensive benchmarking study of classical and quantum machine learning models for image recognition on the MNIST handwritten digit dataset, evaluating both traditional models, a Classical Support Vector Machine (CSVM) and a Quantum Support Vector Machine (QSVM), and deep neural network models, a Classical Convolutional Neural Network (CCNN) and a Quantum Convolutional Neural Network (QCNN), across four performance dimensions: classification accuracy, computational runtime, parameter count, and memory requirements. Experiments are conducted as functions of both feature dimensionality and sample size, and across CPU and GPU execution environments, providing a controlled, multidimensional comparison to address gaps in prior work. For the SVM-based models, QSVM consistently outperforms CSVM in accuracy, reaching $\sim$ 0.90 versus $\sim$ 0.85 at 1,000 samples, with a higher computational cost. A feature count of 10 qubits and a sample size in the range of 200 -- 500 emerge as practical operating points that balance accuracy and runtime. For the neural network models, CCNN and QCNN achieve comparable classification accuracy, both exceeding 0.96 at 64 features and 60,000 samples, yet QCNN offers substantially superior parameter and memory efficiency, requiring $\sim$ 94\% fewer parameters and $\sim$ 75\% less memory than CCNN at higher feature counts, while incurring higher runtime. Across both model families, quantum models consistently outperform classical models by greater margins in accuracy as feature dimensionality or sample size increases.
Cough Classification using Few-Shot Learning
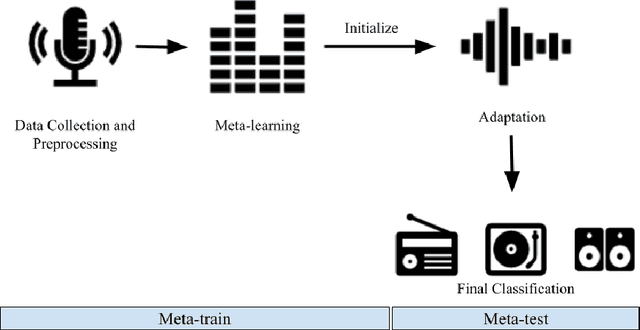
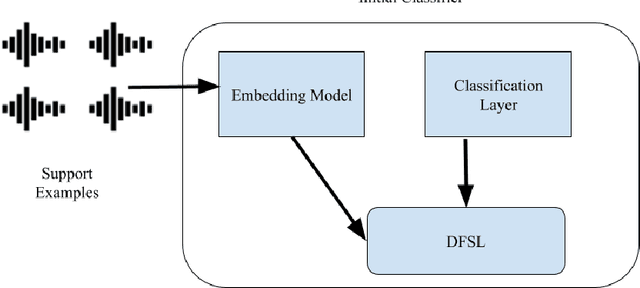
Sep 11, 2025This paper investigates the effectiveness of few-shot learning for respiratory sound classification, focusing on coughbased detection of COVID-19, Flu, and healthy conditions. We leverage Prototypical Networks with spectrogram representations of cough sounds to address the challenge of limited labeled data. Our study evaluates whether few-shot learning can enable models to achieve performance comparable to traditional deep learning approaches while using significantly fewer training samples. Additionally, we compare multi-class and binary classification models to assess whether multi-class models can perform comparably to their binary counterparts. Experimental findings show that few-shot learning models can achieve competitive accuracy. Our model attains 74.87% accuracy in multi-class classification with only 15 support examples per class, while binary classification achieves over 70% accuracy across all class pairs. Class-wise analysis reveals Flu as the most distinguishable class, and Healthy as the most challenging. Statistical tests (paired t-test p = 0.149, Wilcoxon p = 0.125) indicate no significant performance difference between binary and multiclass models, supporting the viability of multi-class classification in this setting. These results highlight the feasibility of applying few-shot learning in medical diagnostics, particularly when large labeled datasets are unavailable.
A Comprehensive Survey of Challenges and Opportunities of Few-Shot Learning Across Multiple Domains
Apr 05, 2025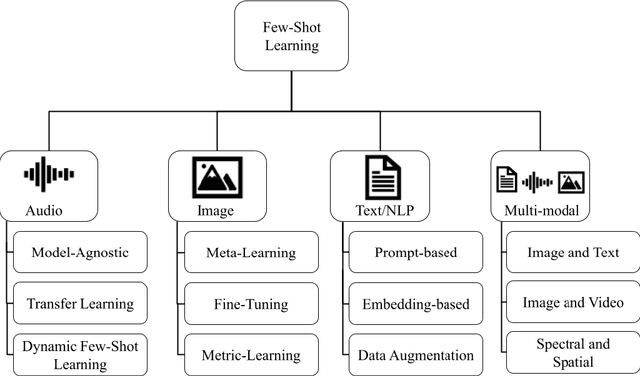

In a world where new domains are constantly discovered and machine learning (ML) is applied to automate new tasks every day, challenges arise with the number of samples available to train ML models. While the traditional ML training relies heavily on data volume, finding a large dataset with a lot of usable samples is not always easy, and often the process takes time. For instance, when a new human transmissible disease such as COVID-19 breaks out and there is an immediate surge for rapid diagnosis, followed by rapid isolation of infected individuals from healthy ones to contain the spread, there is an immediate need to create tools/automation using machine learning models. At the early stage of an outbreak, it is not only difficult to obtain a lot of samples, but also difficult to understand the details about the disease, to process the data needed to train a traditional ML model. A solution for this can be a few-shot learning approach. This paper presents challenges and opportunities of few-shot approaches that vary across major domains, i.e., audio, image, text, and their combinations, with their strengths and weaknesses. This detailed understanding can help to adopt appropriate approaches applicable to different domains and applications.
Sound Classification of Four Insect Classes
Dec 16, 2024



The goal of this project is to classify four different insect sounds: cicada, beetle, termite, and cricket. One application of this project is for pest control to monitor and protect our ecosystem. Our project leverages data augmentation, including pitch shifting and speed changing, to improve model generalization. This project will test the performance of Decision Tree, Random Forest, SVM RBF, XGBoost, and k-NN models, combined with MFCC feature. A potential novelty of this project is that various data augmentation techniques are used and created 6 data along with the original sound. The dataset consists of the sound recordings of these four insects. This project aims to achieve a high classification accuracy and to reduce the over-fitting problem.
AuD-Former: A Hierarchical Transformer Network for Multimodal Audio-Based Disease Prediction
Oct 11, 2024



Audio-based disease prediction is emerging as a promising supplement to traditional medical diagnosis methods, facilitating early, convenient, and non-invasive disease detection and prevention. Multimodal fusion, which integrates features from various domains within or across bio-acoustic modalities, has proven effective in enhancing diagnostic performance. However, most existing methods in the field employ unilateral fusion strategies that focus solely on either intra-modal or inter-modal fusion. This approach limits the full exploitation of the complementary nature of diverse acoustic feature domains and bio-acoustic modalities. Additionally, the inadequate and isolated exploration of latent dependencies within modality-specific and modality-shared spaces curtails their capacity to manage the inherent heterogeneity in multimodal data. To fill these gaps, we propose AuD-Former, a hierarchical transformer network designed for general multimodal audio-based disease prediction. Specifically, we seamlessly integrate intra-modal and inter-modal fusion in a hierarchical manner and proficiently encode the necessary intra-modal and inter-modal complementary correlations, respectively. Comprehensive experiments demonstrate that AuD-Former achieves state-of-the-art performance in predicting three diseases: COVID-19, Parkinson's disease, and pathological dysarthria, showcasing its promising potential in a broad context of audio-based disease prediction tasks. Additionally, extensive ablation studies and qualitative analyses highlight the significant benefits of each main component within our model.
Mitigating Sex Bias in Audio Data-driven COPD and COVID-19 Breathing Pattern Detection Models
Sep 16, 2024

In the healthcare industry, researchers have been developing machine learning models to automate diagnosing patients with respiratory illnesses based on their breathing patterns. However, these models do not consider the demographic biases, particularly sex bias, that often occur when models are trained with a skewed patient dataset. Hence, it is essential in such an important industry to reduce this bias so that models can make fair diagnoses. In this work, we examine the bias in models used to detect breathing patterns of two major respiratory diseases, i.e., chronic obstructive pulmonary disease (COPD) and COVID-19. Using decision tree models trained with audio recordings of breathing patterns obtained from two open-source datasets consisting of 29 COPD and 680 COVID-19-positive patients, we analyze the effect of sex bias on the models. With a threshold optimizer and two constraints (demographic parity and equalized odds) to mitigate the bias, we witness 81.43% (demographic parity difference) and 71.81% (equalized odds difference) improvements. These findings are statistically significant.
Toward Mitigating Sex Bias in Pilot Trainees' Stress and Fatigue Modeling
Sep 16, 2024

While researchers have been trying to understand the stress and fatigue among pilots, especially pilot trainees, and to develop stress/fatigue models to automate the process of detecting stress/fatigue, they often do not consider biases such as sex in those models. However, in a critical profession like aviation, where the demographic distribution is disproportionately skewed to one sex, it is urgent to mitigate biases for fair and safe model predictions. In this work, we investigate the perceived stress/fatigue of 69 college students, including 40 pilot trainees with around 63% male. We construct models with decision trees first without bias mitigation and then with bias mitigation using a threshold optimizer with demographic parity and equalized odds constraints 30 times with random instances. Using bias mitigation, we achieve improvements of 88.31% (demographic parity difference) and 54.26% (equalized odds difference), which are also found to be statistically significant.
Transfer Learning to Detect COVID-19 Coughs with Incremental Addition of Patient Coughs to Healthy People's Cough Detection Models
Nov 12, 2023Millions of people have died worldwide from COVID-19. In addition to its high death toll, COVID-19 has led to unbearable suffering for individuals and a huge global burden to the healthcare sector. Therefore, researchers have been trying to develop tools to detect symptoms of this human-transmissible disease remotely to control its rapid spread. Coughing is one of the common symptoms that researchers have been trying to detect objectively from smartphone microphone-sensing. While most of the approaches to detect and track cough symptoms rely on machine learning models developed from a large amount of patient data, this is not possible at the early stage of an outbreak. In this work, we present an incremental transfer learning approach that leverages the relationship between healthy peoples' coughs and COVID-19 patients' coughs to detect COVID-19 coughs with reasonable accuracy using a pre-trained healthy cough detection model and a relatively small set of patient coughs, reducing the need for large patient dataset to train the model. This type of model can be a game changer in detecting the onset of a novel respiratory virus.
Discovering COVID-19 Coughing and Breathing Patterns from Unlabeled Data Using Contrastive Learning with Varying Pre-Training Domains
Jun 02, 2023


Rapid discovery of new diseases, such as COVID-19 can enable a timely epidemic response, preventing the large-scale spread and protecting public health. However, limited research efforts have been taken on this problem. In this paper, we propose a contrastive learning-based modeling approach for COVID-19 coughing and breathing pattern discovery from non-COVID coughs. To validate our models, extensive experiments have been conducted using four large audio datasets and one image dataset. We further explore the effects of different factors, such as domain relevance and augmentation order on the pre-trained models. Our results show that the proposed model can effectively distinguish COVID-19 coughing and breathing from unlabeled data and labeled non-COVID coughs with an accuracy of up to 0.81 and 0.86, respectively. Findings from this work will guide future research to detect an outbreak of a new disease early.
* Accepted by Proceedings of INTERSPEECH 2023
Predicting dominant hand from spatiotemporal context varying physiological data
Dec 08, 2022



Health metrics from wrist-worn devices demand an automatic dominant hand prediction to keep an accurate operation. The prediction would improve reliability, enhance the consumer experience, and encourage further development of healthcare applications. This paper aims to evaluate the use of physiological and spatiotemporal context information from a two-hand experiment to predict the wrist placement of a commercial smartwatch. The main contribution is a methodology to obtain an effective model and features from low sample rate physiological sensors and a self-reported context survey. Results show an effective dominant hand prediction using data from a single subject under real-life conditions.