 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness to Model Inversion Attacks via Sparse Coding Architectures
Mar 21, 2024Recent model inversion attack algorithms permit adversaries to reconstruct a neural network's private training data just by repeatedly querying the network and inspecting its outputs. In this work, we develop a novel network architecture that leverages sparse-coding layers to obtain superior robustness to this class of attacks. Three decades of computer science research has studied sparse coding in the context of image denoising, object recognition, and adversarial misclassification settings, but to the best of our knowledge, its connection to state-of-the-art privacy vulnerabilities remains unstudied. However, sparse coding architectures suggest an advantageous means to defend against model inversion attacks because they allow us to control the amount of irrelevant private information encoded in a network's intermediate representations in a manner that can be computed efficiently during training and that is known to have little effect on classification accuracy. Specifically, compared to networks trained with a variety of state-of-the-art defenses, our sparse-coding architectures maintain comparable or higher classification accuracy while degrading state-of-the-art training data reconstructions by factors of 1.1 to 18.3 across a variety of reconstruction quality metrics (PSNR, SSIM, FID). This performance advantage holds across 5 datasets ranging from CelebA faces to medical images and CIFAR-10, and across various state-of-the-art SGD-based and GAN-based inversion attacks, including Plug-&-Play attacks. We provide a cluster-ready PyTorch codebase to promote research and standardize defense evaluations.
LCANets++: Robust Audio Classification using Multi-layer Neural Networks with Lateral Competition
Aug 23, 2023Audio classification aims at recognizing audio signals, including speech commands or sound events. However, current audio classifiers are susceptible to perturbations and adversarial attacks. In addition, real-world audio classification tasks often suffer from limited labeled data. To help bridge these gaps, previous work developed neuro-inspired convolutional neural networks (CNNs) with sparse coding via the Locally Competitive Algorithm (LCA) in the first layer (i.e., LCANets) for computer vision. LCANets learn in a combination of supervised and unsupervised learning, reducing dependency on labeled samples. Motivated by the fact that auditory cortex is also sparse, we extend LCANets to audio recognition tasks and introduce LCANets++, which are CNNs that perform sparse coding in multiple layers via LCA. We demonstrate that LCANets++ are more robust than standard CNNs and LCANets against perturbations, e.g., background noise, as well as black-box and white-box attacks, e.g., evasion and fast gradient sign (FGSM) attacks.
Are Your Sensitive Attributes Private? Novel Model Inversion Attribute Inference Attacks on Classification Models
Jan 23, 2022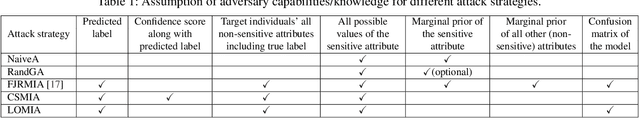


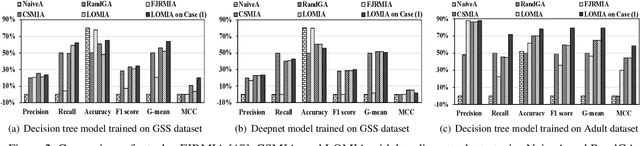
Increasing use of machine learning (ML) technologies in privacy-sensitive domains such as medical diagnoses, lifestyle predictions, and business decisions highlights the need to better understand if these ML technologies are introducing leakage of sensitive and proprietary training data. In this paper, we focus on model inversion attacks where the adversary knows non-sensitive attributes about records in the training data and aims to infer the value of a sensitive attribute unknown to the adversary, using only black-box access to the target classification model. We first devise a novel confidence score-based model inversion attribute inference attack that significantly outperforms the state-of-the-art. We then introduce a label-only model inversion attack that relies only on the model's predicted labels but still matches our confidence score-based attack in terms of attack effectiveness. We also extend our attacks to the scenario where some of the other (non-sensitive) attributes of a target record are unknown to the adversary. We evaluate our attacks on two types of machine learning models, decision tree and deep neural network, trained on three real datasets. Moreover, we empirically demonstrate the disparate vulnerability of model inversion attacks, i.e., specific groups in the training dataset (grouped by gender, race, etc.) could be more vulnerable to model inversion attacks.
Opportunistic Multi-Modal User Authentication for Health-Tracking IoT Wearables
Oct 09, 2021
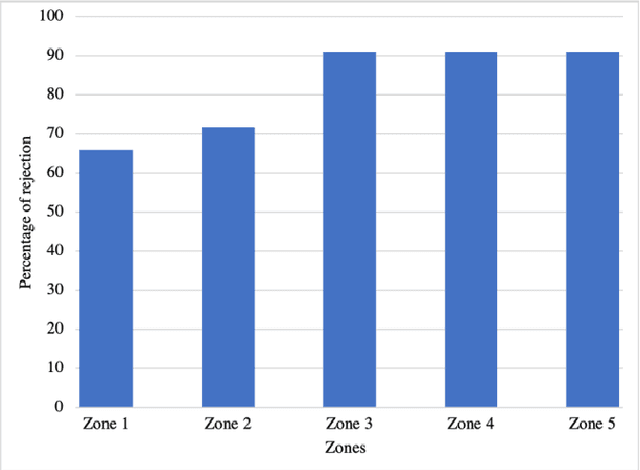
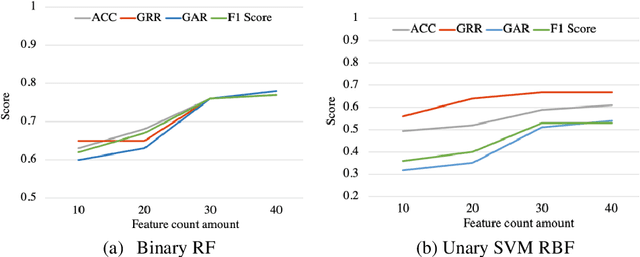
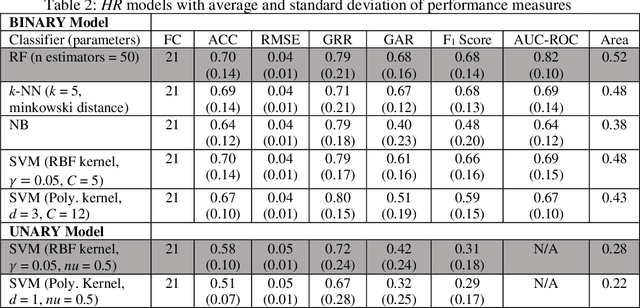
With the advancement of technologies, market wearables are becoming increasingly popular with a range of services, including providing access to bank accounts, accessing cars, monitoring patients remotely, among several others. However, often these wearables collect various sensitive personal information of a user with no to limited authentication, e.g., knowledge-based external authentication techniques, such as PINs. While most of these external authentication techniques suffer from multiple limitations, including recall burden, human errors, or biases, researchers have started using various physiological and behavioral data, such as gait and heart rate, collected by the wearables to authenticate a wearable user implicitly with a limited accuracy due to sensing and computing constraints of wearables. In this work, we explore the usefulness of blood oxygen saturation SpO2 values collected from the Oximeter device to distinguish a user from others. From a cohort of 25 subjects, we find that 92% of the cases SpO2 can distinguish pairs of users. From detailed modeling and performance analysis, we observe that while SpO2 alone can obtain an average accuracy of 0.69 and F1 score of 0.69, the addition of heart rate (HR) can improve the average identification accuracy by 15% and F1 score by 13%. These results show promise in using SpO2 along with other biometrics to develop implicit continuous authentications for wearables.