 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisparate Privacy Vulnerability: Targeted Attribute Inference Attacks and Defenses
Apr 05, 2025



As machine learning (ML) technologies become more prevalent in privacy-sensitive areas like healthcare and finance, eventually incorporating sensitive information in building data-driven algorithms, it is vital to scrutinize whether these data face any privacy leakage risks. One potential threat arises from an adversary querying trained models using the public, non-sensitive attributes of entities in the training data to infer their private, sensitive attributes, a technique known as the attribute inference attack. This attack is particularly deceptive because, while it may perform poorly in predicting sensitive attributes across the entire dataset, it excels at predicting the sensitive attributes of records from a few vulnerable groups, a phenomenon known as disparate vulnerability. This paper illustrates that an adversary can take advantage of this disparity to carry out a series of new attacks, showcasing a threat level beyond previous imagination. We first develop a novel inference attack called the disparity inference attack, which targets the identification of high-risk groups within the dataset. We then introduce two targeted variations of the attribute inference attack that can identify and exploit a vulnerable subset of the training data, marking the first instances of targeted attacks in this category, achieving significantly higher accuracy than untargeted versions. We are also the first to introduce a novel and effective disparity mitigation technique that simultaneously preserves model performance and prevents any risk of targeted attacks.
FLShield: A Validation Based Federated Learning Framework to Defend Against Poisoning Attacks
Aug 10, 2023Federated learning (FL) is revolutionizing how we learn from data. With its growing popularity, it is now being used in many safety-critical domains such as autonomous vehicles and healthcare. Since thousands of participants can contribute in this collaborative setting, it is, however, challenging to ensure security and reliability of such systems. This highlights the need to design FL systems that are secure and robust against malicious participants' actions while also ensuring high utility, privacy of local data, and efficiency. In this paper, we propose a novel FL framework dubbed as FLShield that utilizes benign data from FL participants to validate the local models before taking them into account for generating the global model. This is in stark contrast with existing defenses relying on server's access to clean datasets -- an assumption often impractical in real-life scenarios and conflicting with the fundamentals of FL. We conduct extensive experiments to evaluate our FLShield framework in different settings and demonstrate its effectiveness in thwarting various types of poisoning and backdoor attacks including a defense-aware one. FLShield also preserves privacy of local data against gradient inversion attacks.
Are Your Sensitive Attributes Private? Novel Model Inversion Attribute Inference Attacks on Classification Models
Jan 23, 2022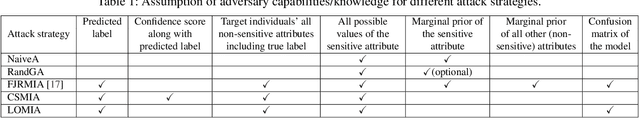


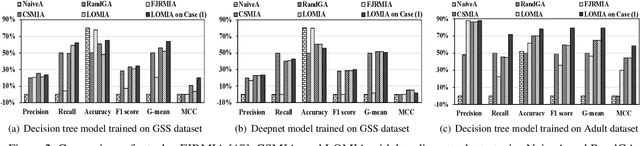
Increasing use of machine learning (ML) technologies in privacy-sensitive domains such as medical diagnoses, lifestyle predictions, and business decisions highlights the need to better understand if these ML technologies are introducing leakage of sensitive and proprietary training data. In this paper, we focus on model inversion attacks where the adversary knows non-sensitive attributes about records in the training data and aims to infer the value of a sensitive attribute unknown to the adversary, using only black-box access to the target classification model. We first devise a novel confidence score-based model inversion attribute inference attack that significantly outperforms the state-of-the-art. We then introduce a label-only model inversion attack that relies only on the model's predicted labels but still matches our confidence score-based attack in terms of attack effectiveness. We also extend our attacks to the scenario where some of the other (non-sensitive) attributes of a target record are unknown to the adversary. We evaluate our attacks on two types of machine learning models, decision tree and deep neural network, trained on three real datasets. Moreover, we empirically demonstrate the disparate vulnerability of model inversion attacks, i.e., specific groups in the training dataset (grouped by gender, race, etc.) could be more vulnerable to model inversion attacks.