 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-LDA: Toward Interpretable LDA Topic Models with Strong Guarantees in Logarithmic Parallel Time
Jun 06, 2025In this paper, we provide the first practical algorithms with provable guarantees for the problem of inferring the topics assigned to each document in an LDA topic model. This is the primary inference problem for many applications of topic models in social science, data exploration, and causal inference settings. We obtain this result by showing a novel non-gradient-based, combinatorial approach to estimating topic models. This yields algorithms that converge to near-optimal posterior probability in logarithmic parallel computation time (adaptivity) -- exponentially faster than any known LDA algorithm. We also show that our approach can provide interpretability guarantees such that each learned topic is formally associated with a known keyword. Finally, we show that unlike alternatives, our approach can maintain the independence assumptions necessary to use the learned topic model for downstream causal inference methods that allow researchers to study topics as treatments. In terms of practical performance, our approach consistently returns solutions of higher semantic quality than solutions from state-of-the-art LDA algorithms, neural topic models, and LLM-based topic models across a diverse range of text datasets and evaluation parameters.
* ICML 2025; Code available at: https://github.com/BreuerLabs/E- LDA
Using AI to Summarize US Presidential Campaign TV Advertisement Videos, 1952-2012
Mar 28, 2025This paper introduces the largest and most comprehensive dataset of US presidential campaign television advertisements, available in digital format. The dataset also includes machine-searchable transcripts and high-quality summaries designed to facilitate a variety of academic research. To date, there has been great interest in collecting and analyzing US presidential campaign advertisements, but the need for manual procurement and annotation led many to rely on smaller subsets. We design a large-scale parallelized, AI-based analysis pipeline that automates the laborious process of preparing, transcribing, and summarizing videos. We then apply this methodology to the 9,707 presidential ads from the Julian P. Kanter Political Commercial Archive. We conduct extensive human evaluations to show that these transcripts and summaries match the quality of manually generated alternatives. We illustrate the value of this data by including an application that tracks the genesis and evolution of current focal issue areas over seven decades of presidential elections. Our analysis pipeline and codebase also show how to use LLM-based tools to obtain high-quality summaries for other video datasets.
Improving Robustness to Model Inversion Attacks via Sparse Coding Architectures
Mar 21, 2024Recent model inversion attack algorithms permit adversaries to reconstruct a neural network's private training data just by repeatedly querying the network and inspecting its outputs. In this work, we develop a novel network architecture that leverages sparse-coding layers to obtain superior robustness to this class of attacks. Three decades of computer science research has studied sparse coding in the context of image denoising, object recognition, and adversarial misclassification settings, but to the best of our knowledge, its connection to state-of-the-art privacy vulnerabilities remains unstudied. However, sparse coding architectures suggest an advantageous means to defend against model inversion attacks because they allow us to control the amount of irrelevant private information encoded in a network's intermediate representations in a manner that can be computed efficiently during training and that is known to have little effect on classification accuracy. Specifically, compared to networks trained with a variety of state-of-the-art defenses, our sparse-coding architectures maintain comparable or higher classification accuracy while degrading state-of-the-art training data reconstructions by factors of 1.1 to 18.3 across a variety of reconstruction quality metrics (PSNR, SSIM, FID). This performance advantage holds across 5 datasets ranging from CelebA faces to medical images and CIFAR-10, and across various state-of-the-art SGD-based and GAN-based inversion attacks, including Plug-&-Play attacks. We provide a cluster-ready PyTorch codebase to promote research and standardize defense evaluations.
Preemptive Detection of Fake Accounts on Social Networks via Multi-Class Preferential Attachment Classifiers
Aug 10, 2023In this paper, we describe a new algorithm called Preferential Attachment k-class Classifier (PreAttacK) for detecting fake accounts in a social network. Recently, several algorithms have obtained high accuracy on this problem. However, they have done so by relying on information about fake accounts' friendships or the content they share with others--the very things we seek to prevent. PreAttacK represents a significant departure from these approaches. We provide some of the first detailed distributional analyses of how new fake (and real) accounts first attempt to request friends after joining a major network (Facebook). We show that even before a new account has made friends or shared content, these initial friend request behaviors evoke a natural multi-class extension of the canonical Preferential Attachment model of social network growth. We use this model to derive a new algorithm, PreAttacK. We prove that in relevant problem instances, PreAttacK near-optimally approximates the posterior probability that a new account is fake under this multi-class Preferential Attachment model of new accounts' (not-yet-answered) friend requests. These are the first provable guarantees for fake account detection that apply to new users, and that do not require strong homophily assumptions. This principled approach also makes PreAttacK the only algorithm with provable guarantees that obtains state-of-the-art performance on new users on the global Facebook network, where it converges to AUC=0.9 after new users send + receive a total of just 20 not-yet-answered friend requests. For comparison, state-of-the-art benchmarks do not obtain this AUC even after observing additional data on new users' first 100 friend requests. Thus, unlike mainstream algorithms, PreAttacK converges before the median new fake account has made a single friendship (accepted friend request) with a human.
Friend or Faux: Graph-Based Early Detection of Fake Accounts on Social Networks
Apr 09, 2020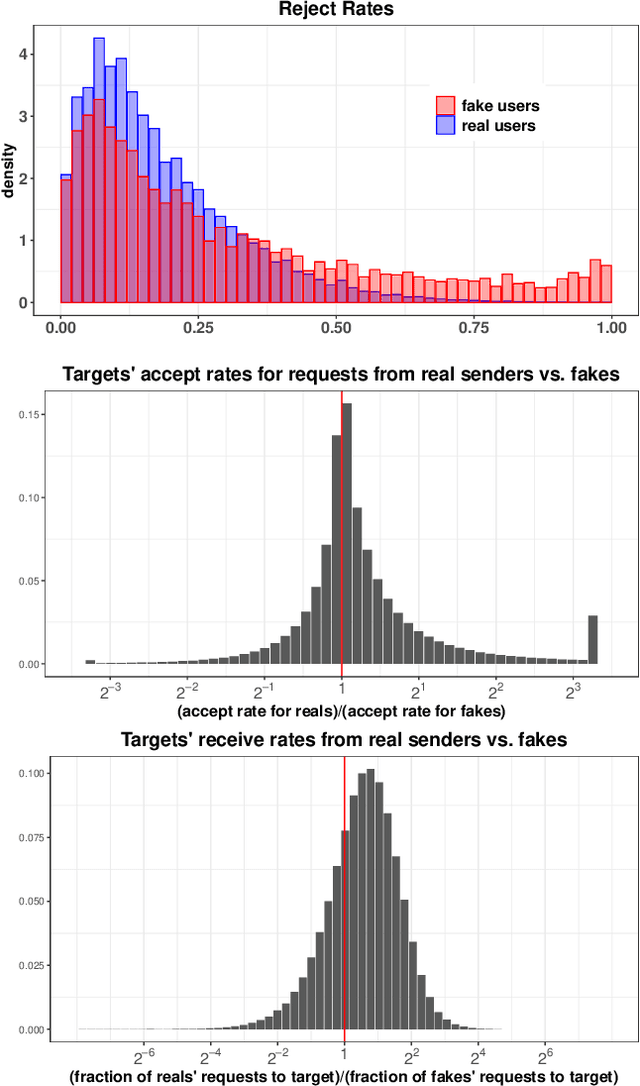

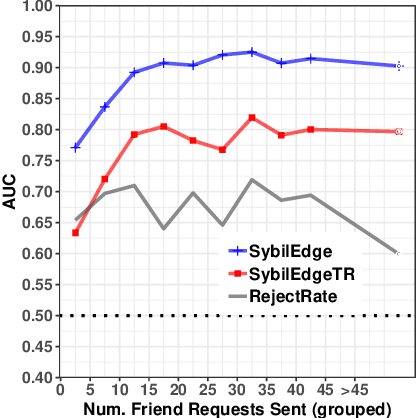
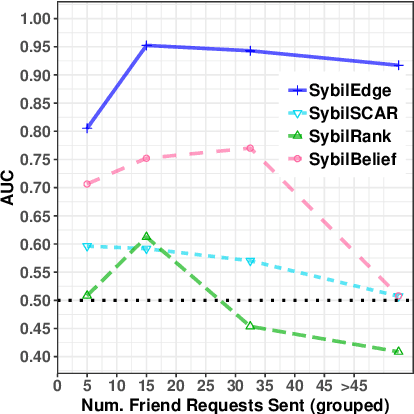
In this paper, we study the problem of early detection of fake user accounts on social networks based solely on their network connectivity with other users. Removing such accounts is a core task for maintaining the integrity of social networks, and early detection helps to reduce the harm that such accounts inflict. However, new fake accounts are notoriously difficult to detect via graph-based algorithms, as their small number of connections are unlikely to reflect a significant structural difference from those of new real accounts. We present the SybilEdge algorithm, which determines whether a new user is a fake account (`sybil') by aggregating over (I) her choices of friend request targets and (II) these targets' respective responses. SybilEdge performs this aggregation giving more weight to a user's choices of targets to the extent that these targets are preferred by other fakes versus real users, and also to the extent that these targets respond differently to fakes versus real users. We show that SybilEdge rapidly detects new fake users at scale on the Facebook network and outperforms state-of-the-art algorithms. We also show that SybilEdge is robust to label noise in the training data, to different prevalences of fake accounts in the network, and to several different ways fakes can select targets for their friend requests. To our knowledge, this is the first time a graph-based algorithm has been shown to achieve high performance (AUC>0.9) on new users who have only sent a small number of friend requests.
The FAST Algorithm for Submodular Maximization
Jul 14, 2019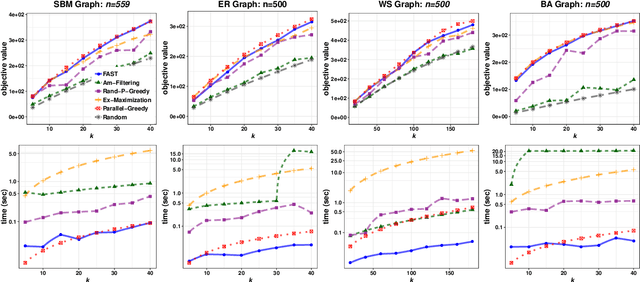
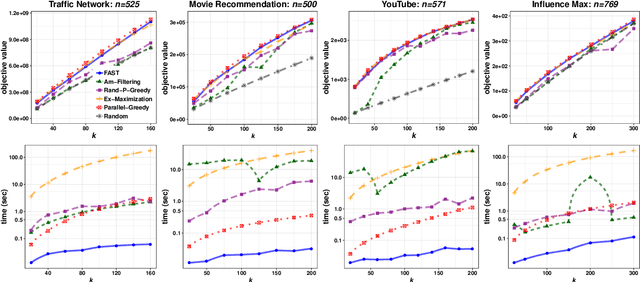
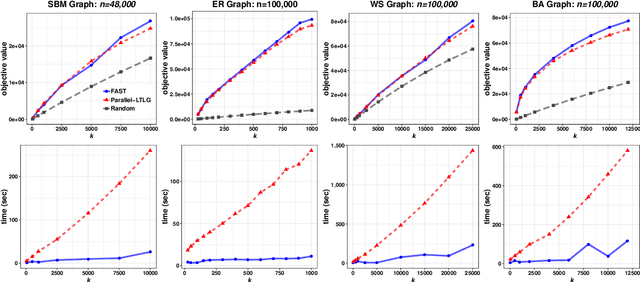
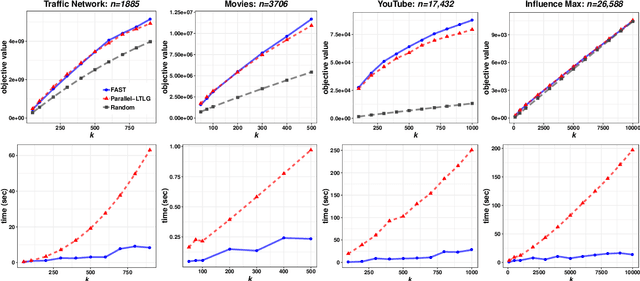
In this paper we describe a new algorithm called Fast Adaptive Sequencing Technique (FAST) for maximizing a monotone submodular function under a cardinality constraint $k$ whose approximation ratio is arbitrarily close to $1-1/e$, is $O(\log(n) \log^2(\log k))$ adaptive, and uses a total of $O(n \log\log(k))$ queries. Recent algorithms have comparable guarantees in terms of asymptotic worst case analysis, but their actual number of rounds and query complexity depend on very large constants and polynomials in terms of precision and confidence, making them impractical for large data sets. Our main contribution is a design that is extremely efficient both in terms of its non-asymptotic worst case query complexity and number of rounds, and in terms of its practical runtime. We show that this algorithm outperforms any algorithm for submodular maximization we are aware of, including hyper-optimized parallel versions of state-of-the-art serial algorithms, by running experiments on large data sets. These experiments show FAST is orders of magnitude faster than the state-of-the-art.