 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreemptive Detection of Fake Accounts on Social Networks via Multi-Class Preferential Attachment Classifiers
Aug 10, 2023In this paper, we describe a new algorithm called Preferential Attachment k-class Classifier (PreAttacK) for detecting fake accounts in a social network. Recently, several algorithms have obtained high accuracy on this problem. However, they have done so by relying on information about fake accounts' friendships or the content they share with others--the very things we seek to prevent. PreAttacK represents a significant departure from these approaches. We provide some of the first detailed distributional analyses of how new fake (and real) accounts first attempt to request friends after joining a major network (Facebook). We show that even before a new account has made friends or shared content, these initial friend request behaviors evoke a natural multi-class extension of the canonical Preferential Attachment model of social network growth. We use this model to derive a new algorithm, PreAttacK. We prove that in relevant problem instances, PreAttacK near-optimally approximates the posterior probability that a new account is fake under this multi-class Preferential Attachment model of new accounts' (not-yet-answered) friend requests. These are the first provable guarantees for fake account detection that apply to new users, and that do not require strong homophily assumptions. This principled approach also makes PreAttacK the only algorithm with provable guarantees that obtains state-of-the-art performance on new users on the global Facebook network, where it converges to AUC=0.9 after new users send + receive a total of just 20 not-yet-answered friend requests. For comparison, state-of-the-art benchmarks do not obtain this AUC even after observing additional data on new users' first 100 friend requests. Thus, unlike mainstream algorithms, PreAttacK converges before the median new fake account has made a single friendship (accepted friend request) with a human.
The Architectural Implications of Facebook's DNN-based Personalized Recommendation
Jun 18, 2019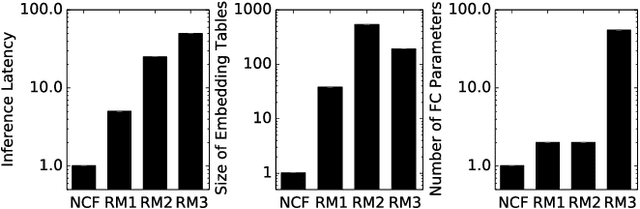
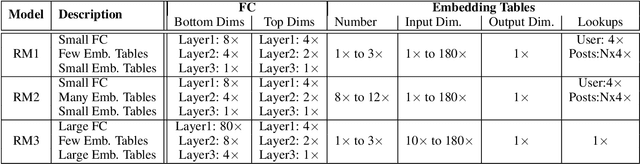
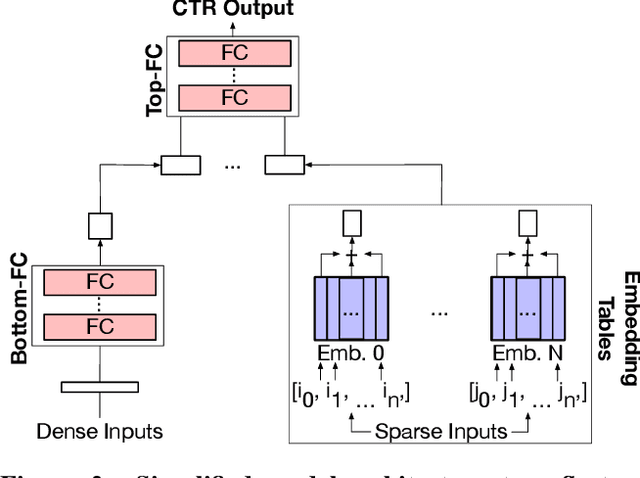
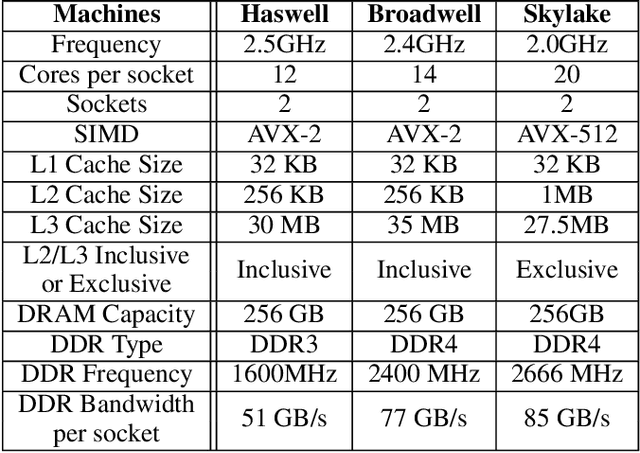
The widespread application of deep learning has changed the landscape of computation in the data center. In particular, personalized recommendation for content ranking is now largely accomplished leveraging deep neural networks. However, despite the importance of these models and the amount of compute cycles they consume, relatively little research attention has been devoted to systems for recommendation. To facilitate research and to advance the understanding of these workloads, this paper presents a set of real-world, production-scale DNNs for personalized recommendation coupled with relevant performance metrics for evaluation. In addition to releasing a set of open-source workloads, we conduct in-depth analysis that underpins future system design and optimization for at-scale recommendation: Inference latency varies by 60% across three Intel server generations, batching and co-location of inferences can drastically improve latency-bounded throughput, and the diverse composition of recommendation models leads to different optimization strategies.