 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Efficiency: Scaling AI Sustainably
Jun 08, 2024



Barroso's seminal contributions in energy-proportional warehouse-scale computing launched an era where modern datacenters have become more energy efficient and cost effective than ever before. At the same time, modern AI applications have driven ever-increasing demands in computing, highlighting the importance of optimizing efficiency across the entire deep learning model development cycle. This paper characterizes the carbon impact of AI, including both operational carbon emissions from training and inference as well as embodied carbon emissions from datacenter construction and hardware manufacturing. We highlight key efficiency optimization opportunities for cutting-edge AI technologies, from deep learning recommendation models to multi-modal generative AI tasks. To scale AI sustainably, we must also go beyond efficiency and optimize across the life cycle of computing infrastructures, from hardware manufacturing to datacenter operations and end-of-life processing for the hardware.
Large Language Models for Compiler Optimization
Sep 11, 2023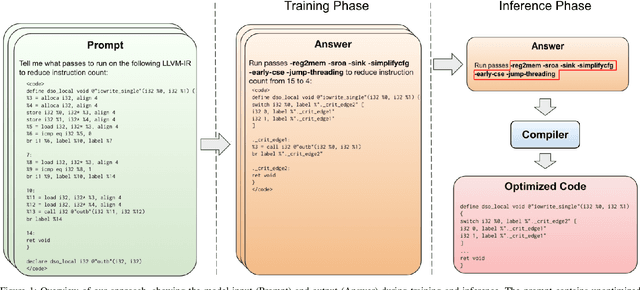
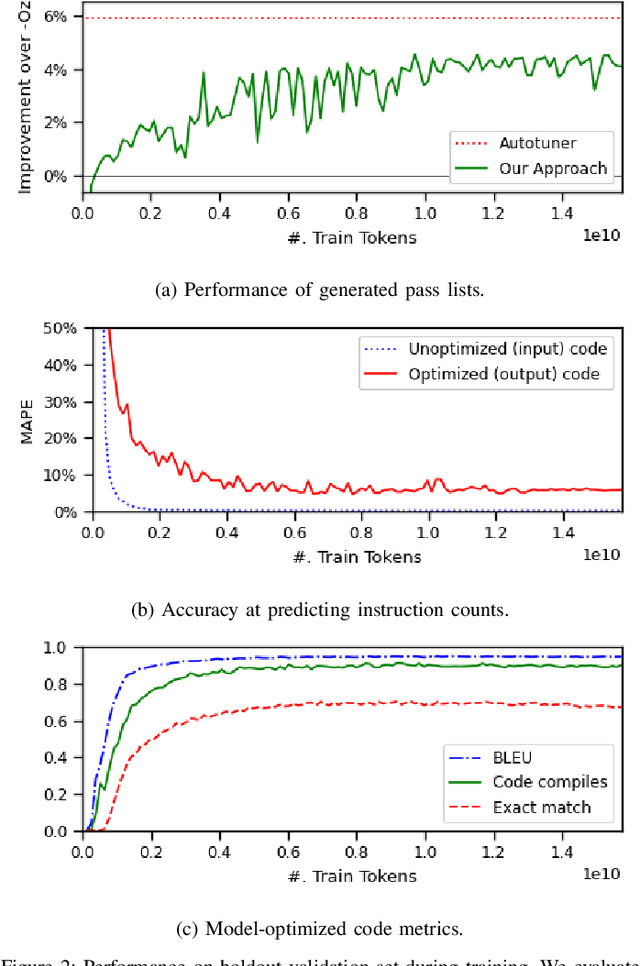
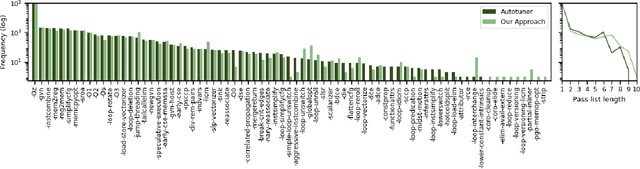
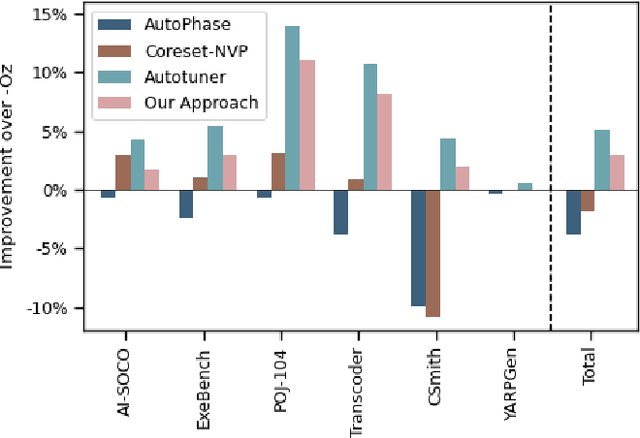
We explore the novel application of Large Language Models to code optimization. We present a 7B-parameter transformer model trained from scratch to optimize LLVM assembly for code size. The model takes as input unoptimized assembly and outputs a list of compiler options to best optimize the program. Crucially, during training, we ask the model to predict the instruction counts before and after optimization, and the optimized code itself. These auxiliary learning tasks significantly improve the optimization performance of the model and improve the model's depth of understanding. We evaluate on a large suite of test programs. Our approach achieves a 3.0% improvement in reducing instruction counts over the compiler, outperforming two state-of-the-art baselines that require thousands of compilations. Furthermore, the model shows surprisingly strong code reasoning abilities, generating compilable code 91% of the time and perfectly emulating the output of the compiler 70% of the time.
BenchDirect: A Directed Language Model for Compiler Benchmarks
Mar 02, 2023The exponential increase of hardware-software complexity has made it impossible for compiler engineers to find the right optimization heuristics manually. Predictive models have been shown to find near optimal heuristics with little human effort but they are limited by a severe lack of diverse benchmarks to train on. Generative AI has been used by researchers to synthesize benchmarks into existing datasets. However, the synthetic programs are short, exceedingly simple and lacking diversity in their features. We develop BenchPress, the first ML compiler benchmark generator that can be directed within source code feature representations. BenchPress synthesizes executable functions by infilling code that conditions on the program's left and right context. BenchPress uses active learning to introduce new benchmarks with unseen features into the dataset of Grewe's et al. CPU vs GPU heuristic, improving its acquired performance by 50%. BenchPress targets features that has been impossible for other synthesizers to reach. In 3 feature spaces, we outperform human-written code from GitHub, CLgen, CLSmith and the SRCIROR mutator in targeting the features of Rodinia benchmarks. BenchPress steers generation with beam search over a feature-agnostic language model. We improve this with BenchDirect which utilizes a directed LM that infills programs by jointly observing source code context and the compiler features that are targeted. BenchDirect achieves up to 36% better accuracy in targeting the features of Rodinia benchmarks, it is 1.8x more likely to give an exact match and it speeds up execution time by up to 72% compared to BenchPress. Both our models produce code that is difficult to distinguish from human-written code. We conduct a Turing test which shows our models' synthetic benchmarks are labelled as 'human-written' as often as human-written code from GitHub.
BenchPress: A Deep Active Benchmark Generator
Aug 16, 2022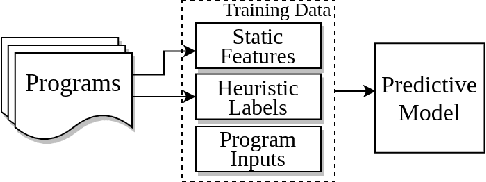

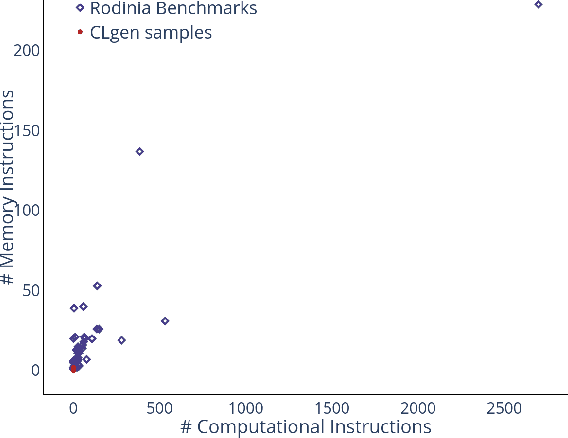
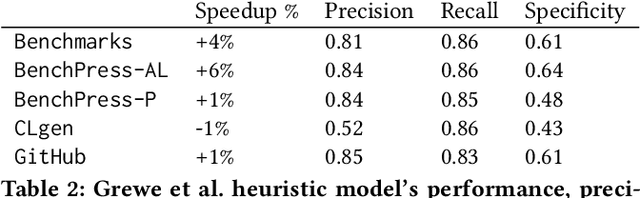
We develop BenchPress, the first ML benchmark generator for compilers that is steerable within feature space representations of source code. BenchPress synthesizes compiling functions by adding new code in any part of an empty or existing sequence by jointly observing its left and right context, achieving excellent compilation rate. BenchPress steers benchmark generation towards desired target features that has been impossible for state of the art synthesizers (or indeed humans) to reach. It performs better in targeting the features of Rodinia benchmarks in 3 different feature spaces compared with (a) CLgen - a state of the art ML synthesizer, (b) CLSmith fuzzer, (c) SRCIROR mutator or even (d) human-written code from GitHub. BenchPress is the first generator to search the feature space with active learning in order to generate benchmarks that will improve a downstream task. We show how using BenchPress, Grewe's et al. CPU vs GPU heuristic model can obtain a higher speedup when trained on BenchPress's benchmarks compared to other techniques. BenchPress is a powerful code generator: Its generated samples compile at a rate of 86%, compared to CLgen's 2.33%. Starting from an empty fixed input, BenchPress produces 10x more unique, compiling OpenCL benchmarks than CLgen, which are significantly larger and more feature diverse.
Sustainable AI: Environmental Implications, Challenges and Opportunities
Oct 30, 2021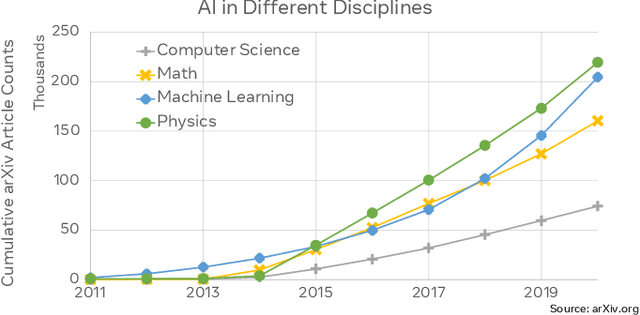
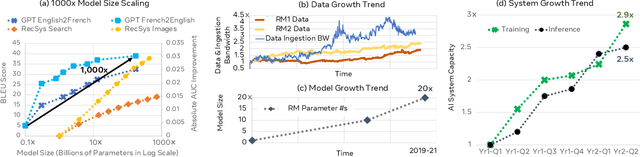
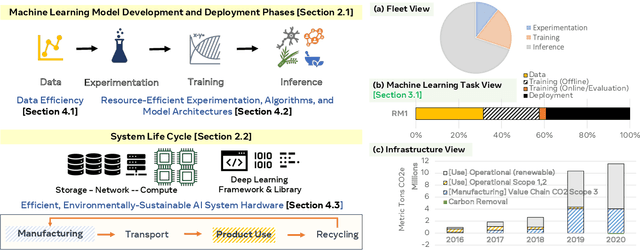
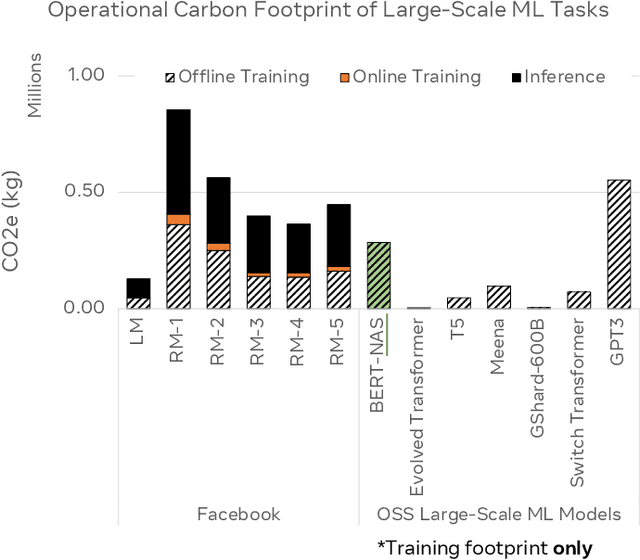
This paper explores the environmental impact of the super-linear growth trends for AI from a holistic perspective, spanning Data, Algorithms, and System Hardware. We characterize the carbon footprint of AI computing by examining the model development cycle across industry-scale machine learning use cases and, at the same time, considering the life cycle of system hardware. Taking a step further, we capture the operational and manufacturing carbon footprint of AI computing and present an end-to-end analysis for what and how hardware-software design and at-scale optimization can help reduce the overall carbon footprint of AI. Based on the industry experience and lessons learned, we share the key challenges and chart out important development directions across the many dimensions of AI. We hope the key messages and insights presented in this paper can inspire the community to advance the field of AI in an environmentally-responsible manner.
Using Python for Model Inference in Deep Learning
Apr 01, 2021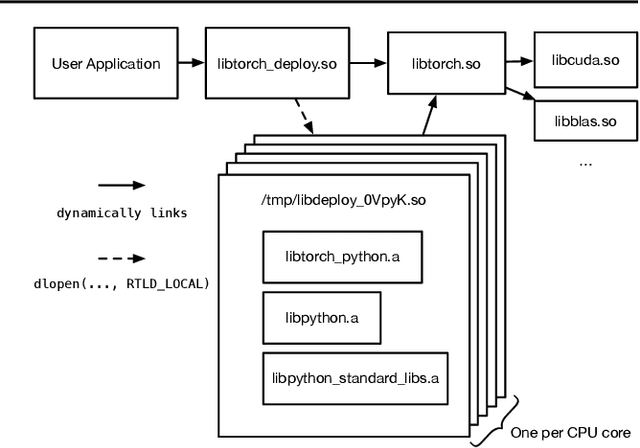


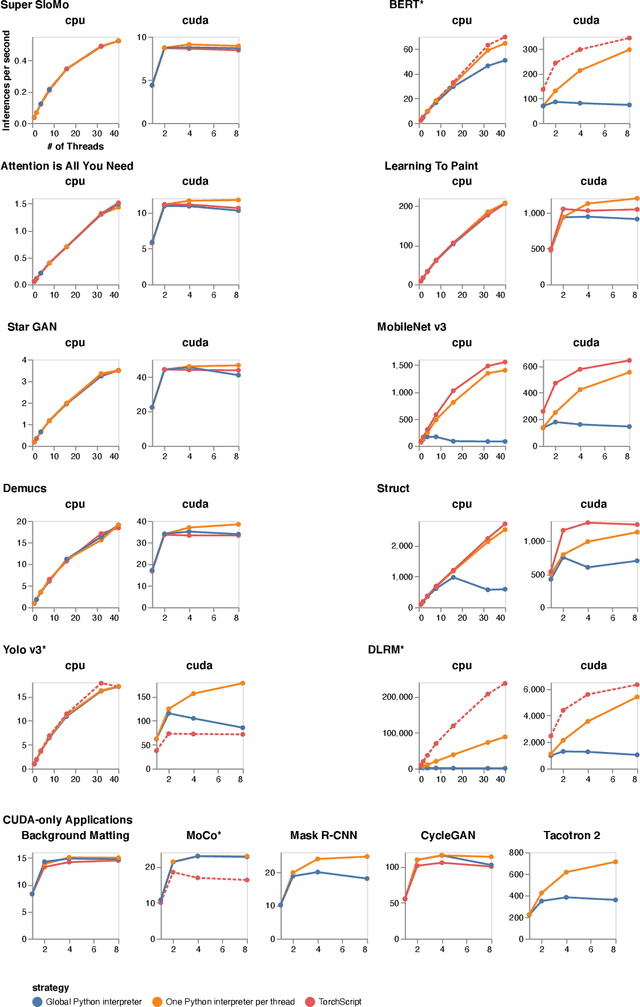
Python has become the de-facto language for training deep neural networks, coupling a large suite of scientific computing libraries with efficient libraries for tensor computation such as PyTorch or TensorFlow. However, when models are used for inference they are typically extracted from Python as TensorFlow graphs or TorchScript programs in order to meet performance and packaging constraints. The extraction process can be time consuming, impeding fast prototyping. We show how it is possible to meet these performance and packaging constraints while performing inference in Python. In particular, we present a way of using multiple Python interpreters within a single process to achieve scalable inference and describe a new container format for models that contains both native Python code and data. This approach simplifies the model deployment story by eliminating the model extraction step, and makes it easier to integrate existing performance-enhancing Python libraries. We evaluate our design on a suite of popular PyTorch models on Github, showing how they can be packaged in our inference format, and comparing their performance to TorchScript. For larger models, our packaged Python models perform the same as TorchScript, and for smaller models where there is some Python overhead, our multi-interpreter approach ensures inference is still scalable.
Understanding Training Efficiency of Deep Learning Recommendation Models at Scale
Nov 11, 2020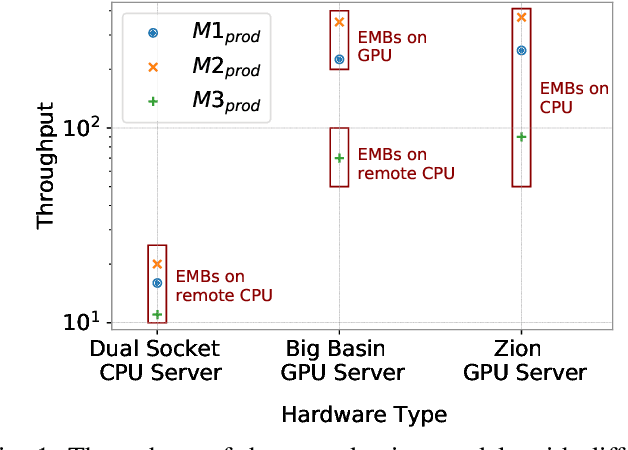
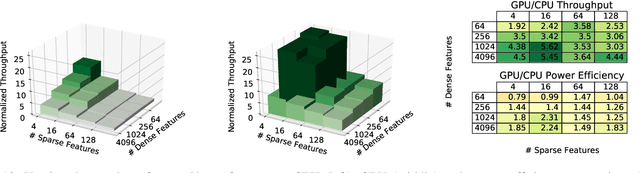
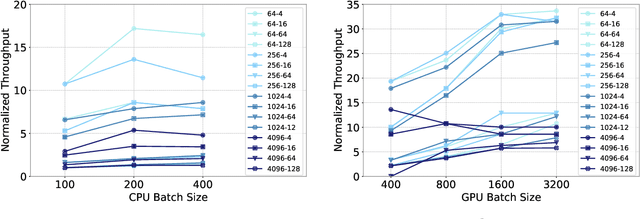
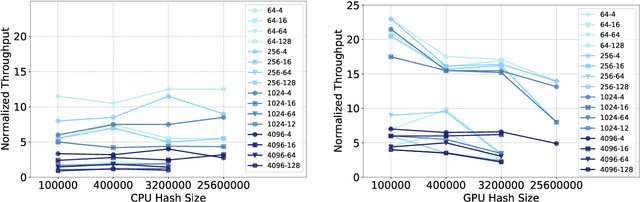
The use of GPUs has proliferated for machine learning workflows and is now considered mainstream for many deep learning models. Meanwhile, when training state-of-the-art personal recommendation models, which consume the highest number of compute cycles at our large-scale datacenters, the use of GPUs came with various challenges due to having both compute-intensive and memory-intensive components. GPU performance and efficiency of these recommendation models are largely affected by model architecture configurations such as dense and sparse features, MLP dimensions. Furthermore, these models often contain large embedding tables that do not fit into limited GPU memory. The goal of this paper is to explain the intricacies of using GPUs for training recommendation models, factors affecting hardware efficiency at scale, and learnings from a new scale-up GPU server design, Zion.
MLPerf Training Benchmark
Oct 30, 2019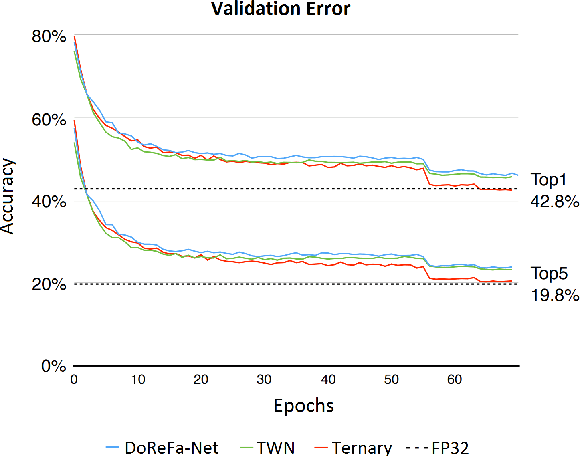
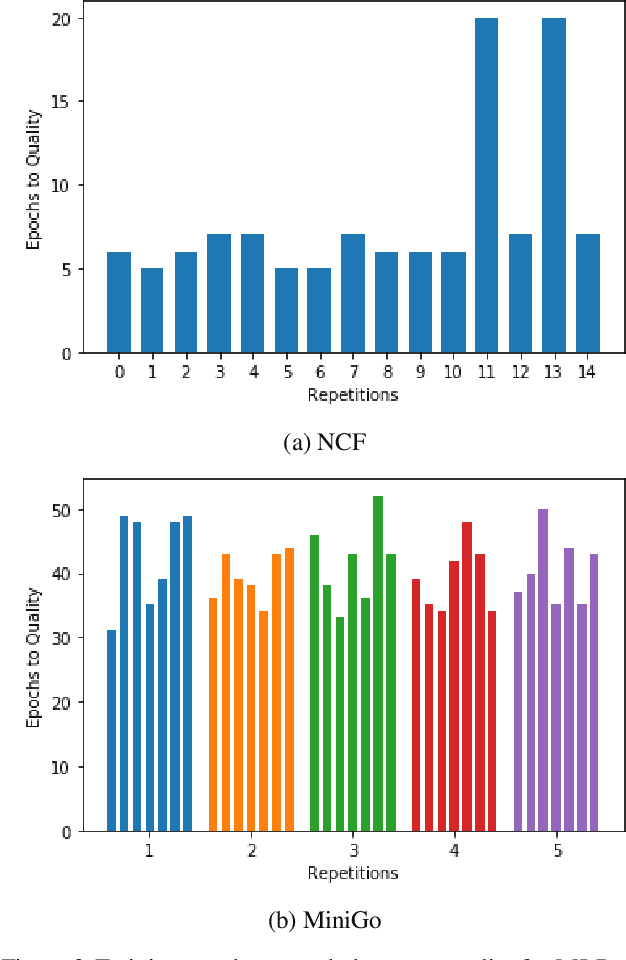
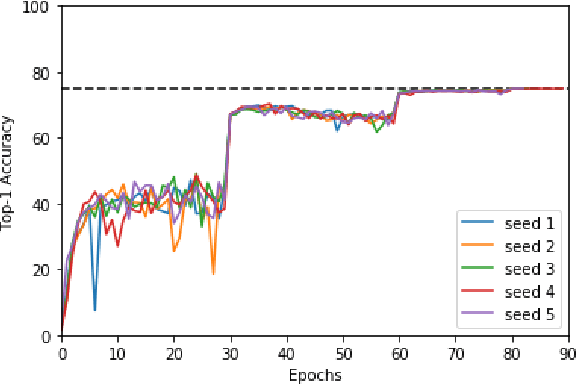
Machine learning is experiencing an explosion of software and hardware solutions, and needs industry-standard performance benchmarks to drive design and enable competitive evaluation. However, machine learning training presents a number of unique challenges to benchmarking that do not exist in other domains: (1) some optimizations that improve training throughput actually increase time to solution, (2) training is stochastic and time to solution has high variance, and (3) the software and hardware systems are so diverse that they cannot be fairly benchmarked with the same binary, code, or even hyperparameters. We present MLPerf, a machine learning benchmark that overcomes these challenges. We quantitatively evaluate the efficacy of MLPerf in driving community progress on performance and scalability across two rounds of results from multiple vendors.
Exploiting Parallelism Opportunities with Deep Learning Frameworks
Aug 13, 2019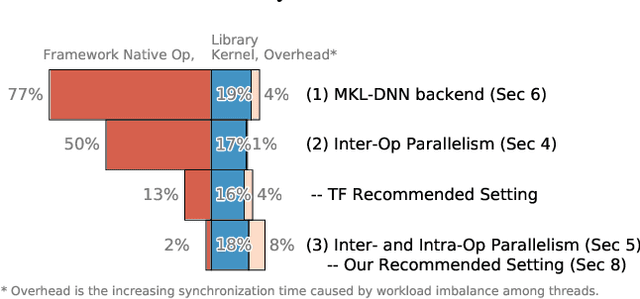
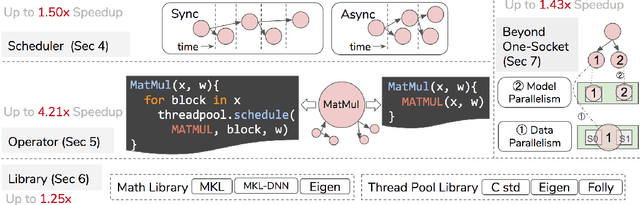
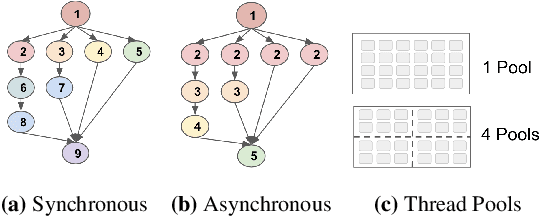
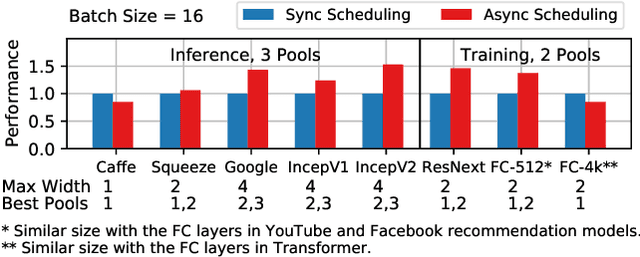
State-of-the-art machine learning frameworks support a wide variety of design features to enable a flexible machine learning programming interface and to ease the programmability burden on machine learning developers. Identifying and using a performance-optimal setting in feature-rich frameworks, however, involves a non-trivial amount of performance characterization and domain-specific knowledge. This paper takes a deep dive into analyzing the performance impact of key design features and the role of parallelism. The observations and insights distill into a simple set of guidelines that one can use to achieve much higher training and inference speedup. The evaluation results show that our proposed performance tuning guidelines outperform both the Intel and TensorFlow recommended settings by 1.29x and 1.34x, respectively, across a diverse set of real-world deep learning models.
The Architectural Implications of Facebook's DNN-based Personalized Recommendation
Jun 18, 2019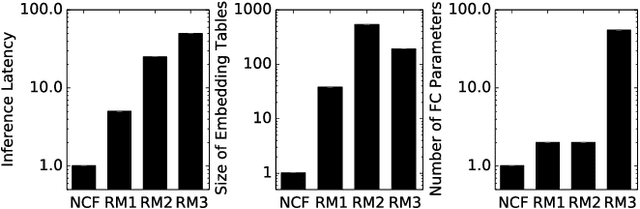
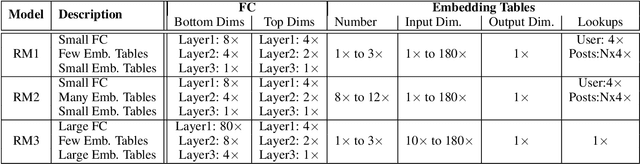
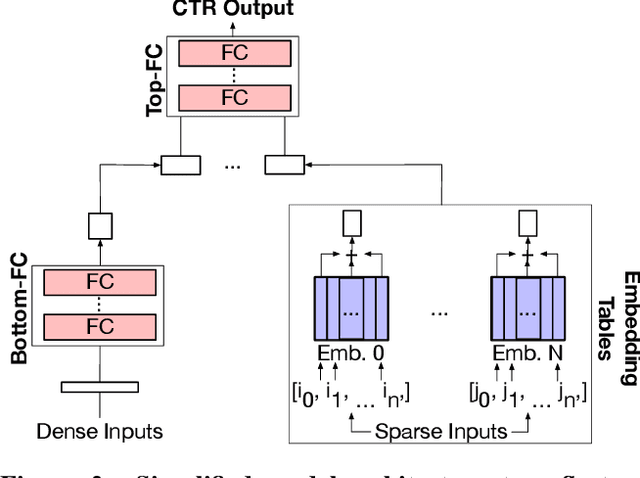
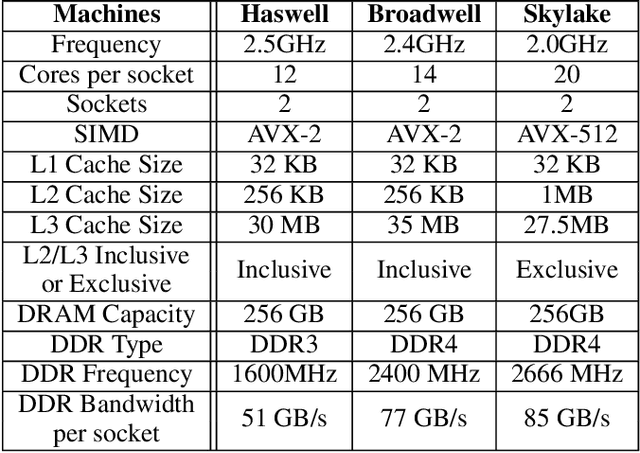
The widespread application of deep learning has changed the landscape of computation in the data center. In particular, personalized recommendation for content ranking is now largely accomplished leveraging deep neural networks. However, despite the importance of these models and the amount of compute cycles they consume, relatively little research attention has been devoted to systems for recommendation. To facilitate research and to advance the understanding of these workloads, this paper presents a set of real-world, production-scale DNNs for personalized recommendation coupled with relevant performance metrics for evaluation. In addition to releasing a set of open-source workloads, we conduct in-depth analysis that underpins future system design and optimization for at-scale recommendation: Inference latency varies by 60% across three Intel server generations, batching and co-location of inferences can drastically improve latency-bounded throughput, and the diverse composition of recommendation models leads to different optimization strategies.