 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchDirect: A Directed Language Model for Compiler Benchmarks
Mar 02, 2023The exponential increase of hardware-software complexity has made it impossible for compiler engineers to find the right optimization heuristics manually. Predictive models have been shown to find near optimal heuristics with little human effort but they are limited by a severe lack of diverse benchmarks to train on. Generative AI has been used by researchers to synthesize benchmarks into existing datasets. However, the synthetic programs are short, exceedingly simple and lacking diversity in their features. We develop BenchPress, the first ML compiler benchmark generator that can be directed within source code feature representations. BenchPress synthesizes executable functions by infilling code that conditions on the program's left and right context. BenchPress uses active learning to introduce new benchmarks with unseen features into the dataset of Grewe's et al. CPU vs GPU heuristic, improving its acquired performance by 50%. BenchPress targets features that has been impossible for other synthesizers to reach. In 3 feature spaces, we outperform human-written code from GitHub, CLgen, CLSmith and the SRCIROR mutator in targeting the features of Rodinia benchmarks. BenchPress steers generation with beam search over a feature-agnostic language model. We improve this with BenchDirect which utilizes a directed LM that infills programs by jointly observing source code context and the compiler features that are targeted. BenchDirect achieves up to 36% better accuracy in targeting the features of Rodinia benchmarks, it is 1.8x more likely to give an exact match and it speeds up execution time by up to 72% compared to BenchPress. Both our models produce code that is difficult to distinguish from human-written code. We conduct a Turing test which shows our models' synthetic benchmarks are labelled as 'human-written' as often as human-written code from GitHub.
LF-checker: Machine Learning Acceleration of Bounded Model Checking for Concurrency Verification (Competition Contribution)
Jan 22, 2023


We describe and evaluate LF-checker, a metaverifier tool based on machine learning. It extracts multiple features of the program under test and predicts the optimal configuration (flags) of a bounded model checker with a decision tree. Our current work is specialised in concurrency verification and employs ESBMC as a back-end verification engine. In the paper, we demonstrate that LF-checker achieves better results than the default configuration of the underlying verification engine.
BenchPress: A Deep Active Benchmark Generator
Aug 16, 2022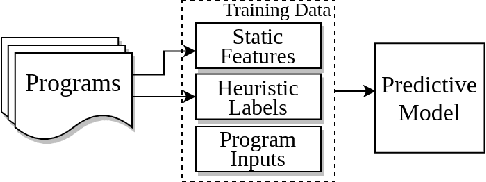

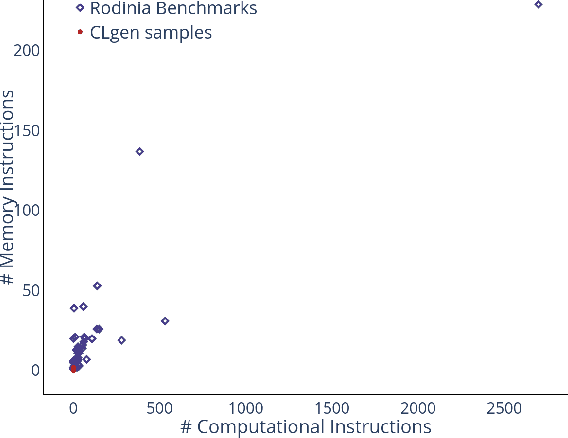
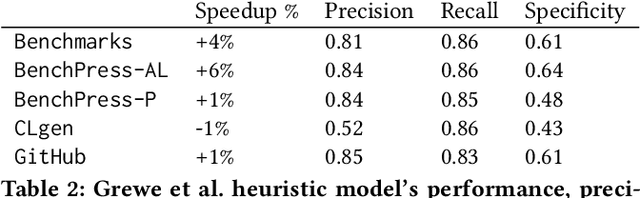
We develop BenchPress, the first ML benchmark generator for compilers that is steerable within feature space representations of source code. BenchPress synthesizes compiling functions by adding new code in any part of an empty or existing sequence by jointly observing its left and right context, achieving excellent compilation rate. BenchPress steers benchmark generation towards desired target features that has been impossible for state of the art synthesizers (or indeed humans) to reach. It performs better in targeting the features of Rodinia benchmarks in 3 different feature spaces compared with (a) CLgen - a state of the art ML synthesizer, (b) CLSmith fuzzer, (c) SRCIROR mutator or even (d) human-written code from GitHub. BenchPress is the first generator to search the feature space with active learning in order to generate benchmarks that will improve a downstream task. We show how using BenchPress, Grewe's et al. CPU vs GPU heuristic model can obtain a higher speedup when trained on BenchPress's benchmarks compared to other techniques. BenchPress is a powerful code generator: Its generated samples compile at a rate of 86%, compared to CLgen's 2.33%. Starting from an empty fixed input, BenchPress produces 10x more unique, compiling OpenCL benchmarks than CLgen, which are significantly larger and more feature diverse.