 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLenna: Language Enhanced Reasoning Detection Assistant
Dec 05, 2023



With the fast-paced development of multimodal large language models (MLLMs), we can now converse with AI systems in natural languages to understand images. However, the reasoning power and world knowledge embedded in the large language models have been much less investigated and exploited for image perception tasks. In this paper, we propose Lenna, a language-enhanced reasoning detection assistant, which utilizes the robust multimodal feature representation of MLLMs, while preserving location information for detection. This is achieved by incorporating an additional <DET> token in the MLLM vocabulary that is free of explicit semantic context but serves as a prompt for the detector to identify the corresponding position. To evaluate the reasoning capability of Lenna, we construct a ReasonDet dataset to measure its performance on reasoning-based detection. Remarkably, Lenna demonstrates outstanding performance on ReasonDet and comes with significantly low training costs. It also incurs minimal transferring overhead when extended to other tasks. Our code and model will be available at https://git.io/Lenna.
Using Python for Model Inference in Deep Learning
Apr 01, 2021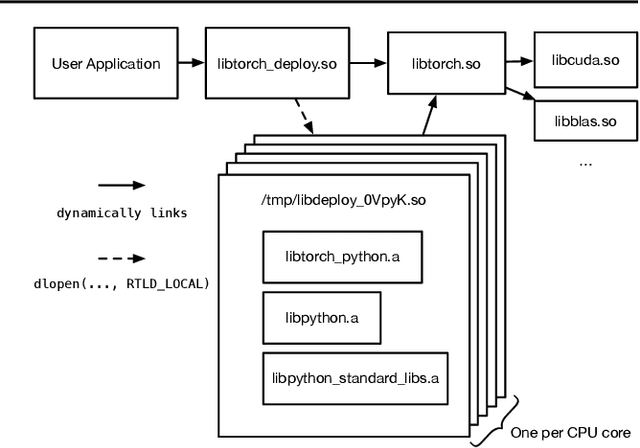


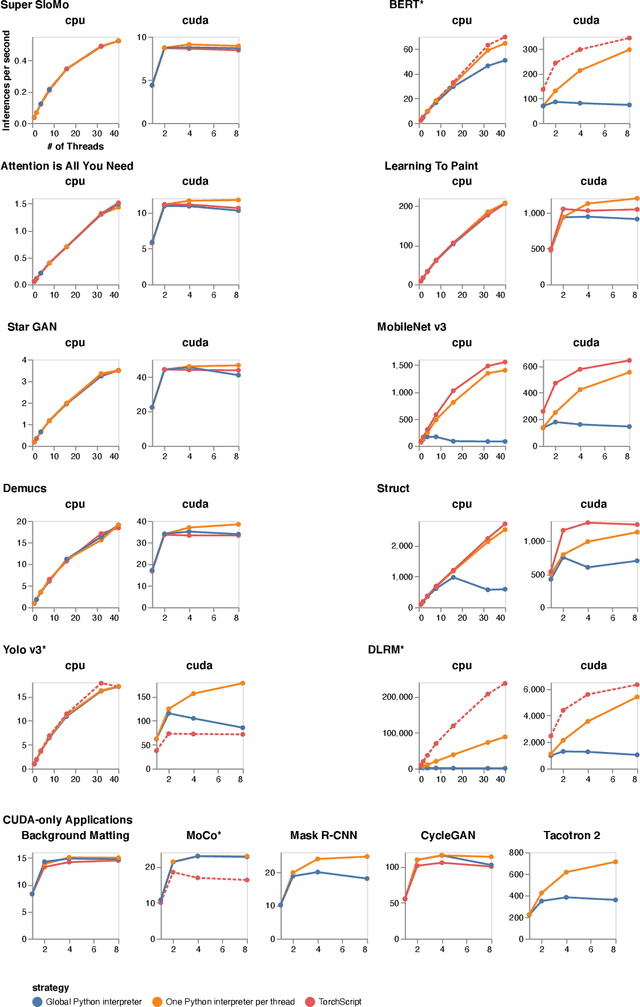
Python has become the de-facto language for training deep neural networks, coupling a large suite of scientific computing libraries with efficient libraries for tensor computation such as PyTorch or TensorFlow. However, when models are used for inference they are typically extracted from Python as TensorFlow graphs or TorchScript programs in order to meet performance and packaging constraints. The extraction process can be time consuming, impeding fast prototyping. We show how it is possible to meet these performance and packaging constraints while performing inference in Python. In particular, we present a way of using multiple Python interpreters within a single process to achieve scalable inference and describe a new container format for models that contains both native Python code and data. This approach simplifies the model deployment story by eliminating the model extraction step, and makes it easier to integrate existing performance-enhancing Python libraries. We evaluate our design on a suite of popular PyTorch models on Github, showing how they can be packaged in our inference format, and comparing their performance to TorchScript. For larger models, our packaged Python models perform the same as TorchScript, and for smaller models where there is some Python overhead, our multi-interpreter approach ensures inference is still scalable.
LazyTensor: combining eager execution with domain-specific compilers
Feb 26, 2021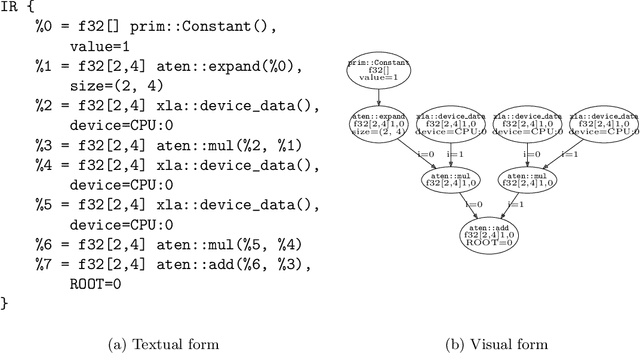



Domain-specific optimizing compilers have demonstrated significant performance and portability benefits, but require programs to be represented in their specialized IRs. Existing frontends to these compilers suffer from the "language subset problem" where some host language features are unsupported in the subset of the user's program that interacts with the domain-specific compiler. By contrast, define-by-run ML frameworks-colloquially called "eager" mode-are popular due to their ease of use and expressivity, where the full power of the host programming language can be used. LazyTensor is a technique to target domain specific compilers without sacrificing define-by-run ergonomics. Initially developed to support PyTorch on Cloud TPUs, the technique, along with a substantially shared implementation, has been used by Swift for TensorFlow across CPUs, GPUs, and TPUs, demonstrating the generality of the approach across (1) Tensor implementations, (2) hardware accelerators, and (3) programming languages.