 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Table Question Answering with Accessible LLMs
Jan 06, 2026Given a table T in a database and a question Q in natural language, the table question answering (TQA) task aims to return an accurate answer to Q based on the content of T. Recent state-of-the-art solutions leverage large language models (LLMs) to obtain high-quality answers. However, most rely on proprietary, large-scale LLMs with costly API access, posing a significant financial barrier. This paper instead focuses on TQA with smaller, open-weight LLMs that can run on a desktop or laptop. This setting is challenging, as such LLMs typically have weaker capabilities than large proprietary models, leading to substantial performance degradation with existing methods. We observe that a key reason for this degradation is that prior approaches often require the LLM to solve a highly sophisticated task using long, complex prompts, which exceed the capabilities of small open-weight LLMs. Motivated by this observation, we present Orchestra, a multi-agent approach that unlocks the potential of accessible LLMs for high-quality, cost-effective TQA. Orchestra coordinates a group of LLM agents, each responsible for a relatively simple task, through a structured, layered workflow to solve complex TQA problems -- akin to an orchestra. By reducing the prompt complexity faced by each agent, Orchestra significantly improves output reliability. We implement Orchestra on top of AgentScope, an open-source multi-agent framework, and evaluate it on multiple TQA benchmarks using a wide range of open-weight LLMs. Experimental results show that Orchestra achieves strong performance even with small- to medium-sized models. For example, with Qwen2.5-14B, Orchestra reaches 72.1% accuracy on WikiTQ, approaching the best prior result of 75.3% achieved with GPT-4; with larger Qwen, Llama, or DeepSeek models, Orchestra outperforms all prior methods and establishes new state-of-the-art results across all benchmarks.
AdaCuRL: Adaptive Curriculum Reinforcement Learning with Invalid Sample Mitigation and Historical Revisiting
Nov 12, 2025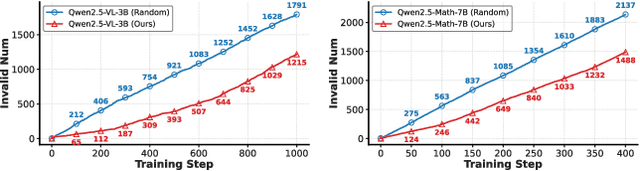
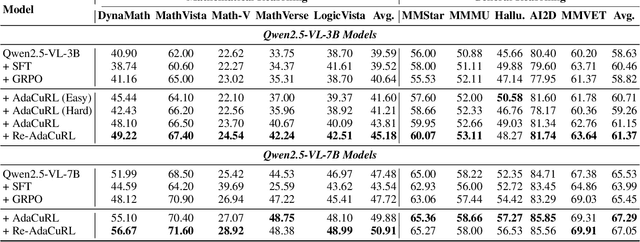
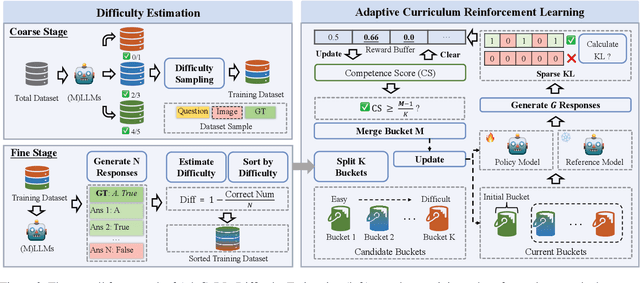
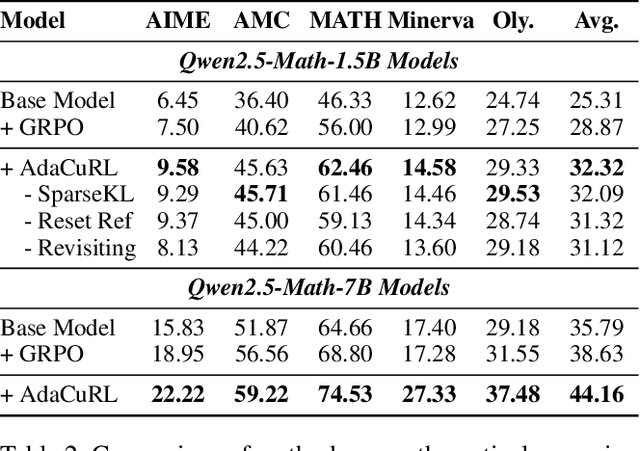
Reinforcement learning (RL) has demonstrated considerable potential for enhancing reasoning in large language models (LLMs). However, existing methods suffer from Gradient Starvation and Policy Degradation when training directly on samples with mixed difficulty. To mitigate this, prior approaches leverage Chain-of-Thought (CoT) data, but the construction of high-quality CoT annotations remains labor-intensive. Alternatively, curriculum learning strategies have been explored but frequently encounter challenges, such as difficulty mismatch, reliance on manual curriculum design, and catastrophic forgetting. To address these issues, we propose AdaCuRL, a Adaptive Curriculum Reinforcement Learning framework that integrates coarse-to-fine difficulty estimation with adaptive curriculum scheduling. This approach dynamically aligns data difficulty with model capability and incorporates a data revisitation mechanism to mitigate catastrophic forgetting. Furthermore, AdaCuRL employs adaptive reference and sparse KL strategies to prevent Policy Degradation. Extensive experiments across diverse reasoning benchmarks demonstrate that AdaCuRL consistently achieves significant performance improvements on both LLMs and MLLMs.
AutoMat: Enabling Automated Crystal Structure Reconstruction from Microscopy via Agentic Tool Use
May 19, 2025



Machine learning-based interatomic potentials and force fields depend critically on accurate atomic structures, yet such data are scarce due to the limited availability of experimentally resolved crystals. Although atomic-resolution electron microscopy offers a potential source of structural data, converting these images into simulation-ready formats remains labor-intensive and error-prone, creating a bottleneck for model training and validation. We introduce AutoMat, an end-to-end, agent-assisted pipeline that automatically transforms scanning transmission electron microscopy (STEM) images into atomic crystal structures and predicts their physical properties. AutoMat combines pattern-adaptive denoising, physics-guided template retrieval, symmetry-aware atomic reconstruction, fast relaxation and property prediction via MatterSim, and coordinated orchestration across all stages. We propose the first dedicated STEM2Mat-Bench for this task and evaluate performance using lattice RMSD, formation energy MAE, and structure-matching success rate. By orchestrating external tool calls, AutoMat enables a text-only LLM to outperform vision-language models in this domain, achieving closed-loop reasoning throughout the pipeline. In large-scale experiments over 450 structure samples, AutoMat substantially outperforms existing multimodal large language models and tools. These results validate both AutoMat and STEM2Mat-Bench, marking a key step toward bridging microscopy and atomistic simulation in materials science.The code and dataset are publicly available at https://github.com/yyt-2378/AutoMat and https://huggingface.co/datasets/yaotianvector/STEM2Mat.
GPG: A Simple and Strong Reinforcement Learning Baseline for Model Reasoning
Apr 03, 2025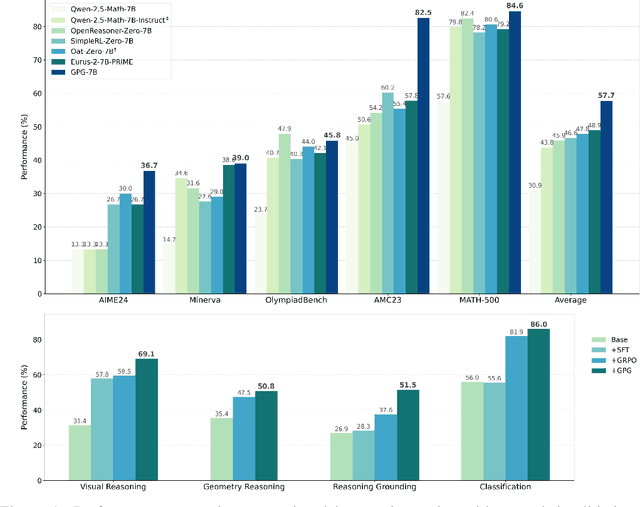
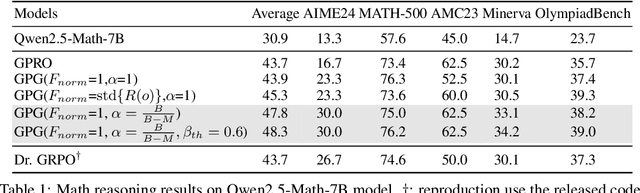
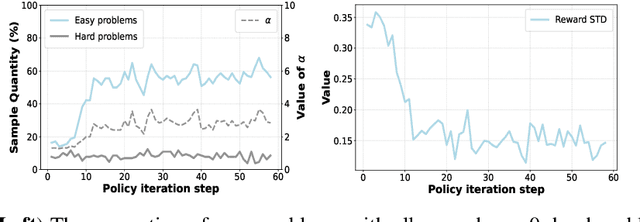

Reinforcement Learning (RL) can directly enhance the reasoning capabilities of large language models without extensive reliance on Supervised Fine-Tuning (SFT). In this work, we revisit the traditional Policy Gradient (PG) mechanism and propose a minimalist RL approach termed Group Policy Gradient (GPG). Unlike conventional methods, GPG directly optimize the original RL objective, thus obviating the need for surrogate loss functions. As illustrated in our paper, by eliminating both the critic and reference models, and avoiding KL divergence constraints, our approach significantly simplifies the training process when compared to Group Relative Policy Optimization (GRPO). Our approach achieves superior performance without relying on auxiliary techniques or adjustments. Extensive experiments demonstrate that our method not only reduces computational costs but also consistently outperforms GRPO across various unimodal and multimodal tasks. Our code is available at https://github.com/AMAP-ML/GPG.
KIMAs: A Configurable Knowledge Integrated Multi-Agent System
Feb 13, 2025Knowledge-intensive conversations supported by large language models (LLMs) have become one of the most popular and helpful applications that can assist people in different aspects. Many current knowledge-intensive applications are centered on retrieval-augmented generation (RAG) techniques. While many open-source RAG frameworks facilitate the development of RAG-based applications, they often fall short in handling practical scenarios complicated by heterogeneous data in topics and formats, conversational context management, and the requirement of low-latency response times. This technical report presents a configurable knowledge integrated multi-agent system, KIMAs, to address these challenges. KIMAs features a flexible and configurable system for integrating diverse knowledge sources with 1) context management and query rewrite mechanisms to improve retrieval accuracy and multi-turn conversational coherency, 2) efficient knowledge routing and retrieval, 3) simple but effective filter and reference generation mechanisms, and 4) optimized parallelizable multi-agent pipeline execution. Our work provides a scalable framework for advancing the deployment of LLMs in real-world settings. To show how KIMAs can help developers build knowledge-intensive applications with different scales and emphases, we demonstrate how we configure the system to three applications already running in practice with reliable performance.
Talk to Right Specialists: Routing and Planning in Multi-agent System for Question Answering
Jan 14, 2025



Leveraging large language models (LLMs), an agent can utilize retrieval-augmented generation (RAG) techniques to integrate external knowledge and increase the reliability of its responses. Current RAG-based agents integrate single, domain-specific knowledge sources, limiting their ability and leading to hallucinated or inaccurate responses when addressing cross-domain queries. Integrating multiple knowledge bases into a unified RAG-based agent raises significant challenges, including increased retrieval overhead and data sovereignty when sensitive data is involved. In this work, we propose RopMura, a novel multi-agent system that addresses these limitations by incorporating highly efficient routing and planning mechanisms. RopMura features two key components: a router that intelligently selects the most relevant agents based on knowledge boundaries and a planner that decomposes complex multi-hop queries into manageable steps, allowing for coordinating cross-domain responses. Experimental results demonstrate that RopMura effectively handles both single-hop and multi-hop queries, with the routing mechanism enabling precise answers for single-hop queries and the combined routing and planning mechanisms achieving accurate, multi-step resolutions for complex queries.
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing
May 27, 2024As the field of image generation rapidly advances, traditional diffusion models and those integrated with multimodal large language models (LLMs) still encounter limitations in interpreting complex prompts and preserving image consistency pre and post-editing. To tackle these challenges, we present an innovative image editing framework that employs the robust Chain-of-Thought (CoT) reasoning and localizing capabilities of multimodal LLMs to aid diffusion models in generating more refined images. We first meticulously design a CoT process comprising instruction decomposition, region localization, and detailed description. Subsequently, we fine-tune the LISA model, a lightweight multimodal LLM, using the CoT process of Multimodal LLMs and the mask of the edited image. By providing the diffusion models with knowledge of the generated prompt and image mask, our models generate images with a superior understanding of instructions. Through extensive experiments, our model has demonstrated superior performance in image generation, surpassing existing state-of-the-art models. Notably, our model exhibits an enhanced ability to understand complex prompts and generate corresponding images, while maintaining high fidelity and consistency in images before and after generation.
Exploring Privacy and Fairness Risks in Sharing Diffusion Models: An Adversarial Perspective
Mar 04, 2024



Diffusion models have recently gained significant attention in both academia and industry due to their impressive generative performance in terms of both sampling quality and distribution coverage. Accordingly, proposals are made for sharing pre-trained diffusion models across different organizations, as a way of improving data utilization while enhancing privacy protection by avoiding sharing private data directly. However, the potential risks associated with such an approach have not been comprehensively examined. In this paper, we take an adversarial perspective to investigate the potential privacy and fairness risks associated with the sharing of diffusion models. Specifically, we investigate the circumstances in which one party (the sharer) trains a diffusion model using private data and provides another party (the receiver) black-box access to the pre-trained model for downstream tasks. We demonstrate that the sharer can execute fairness poisoning attacks to undermine the receiver's downstream models by manipulating the training data distribution of the diffusion model. Meanwhile, the receiver can perform property inference attacks to reveal the distribution of sensitive features in the sharer's dataset. Our experiments conducted on real-world datasets demonstrate remarkable attack performance on different types of diffusion models, which highlights the critical importance of robust data auditing and privacy protection protocols in pertinent applications.
MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
Feb 06, 2024We introduce MobileVLM V2, a family of significantly improved vision language models upon MobileVLM, which proves that a delicate orchestration of novel architectural design, an improved training scheme tailored for mobile VLMs, and rich high-quality dataset curation can substantially benefit VLMs' performance. Specifically, MobileVLM V2 1.7B achieves better or on-par performance on standard VLM benchmarks compared with much larger VLMs at the 3B scale. Notably, our 3B model outperforms a large variety of VLMs at the 7B+ scale. Our models will be released at https://github.com/Meituan-AutoML/MobileVLM .
MobileVLM : A Fast, Strong and Open Vision Language Assistant for Mobile Devices
Dec 30, 2023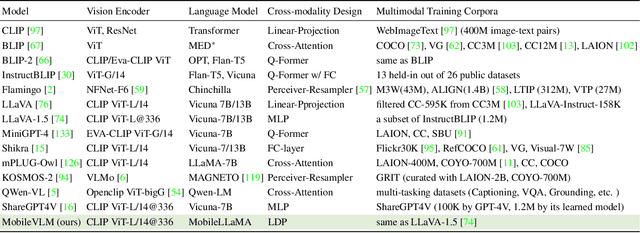
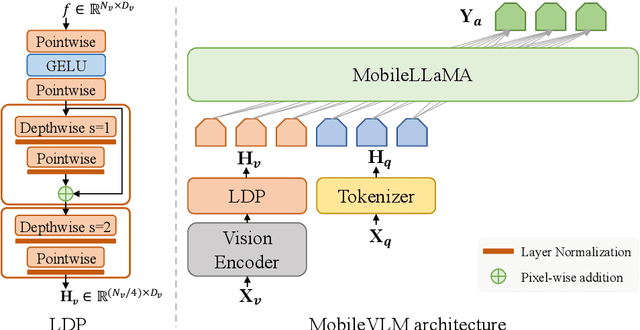
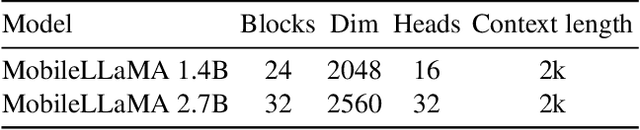
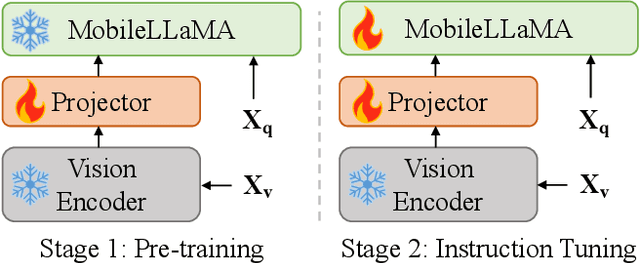
We present MobileVLM, a competent multimodal vision language model (MMVLM) targeted to run on mobile devices. It is an amalgamation of a myriad of architectural designs and techniques that are mobile-oriented, which comprises a set of language models at the scale of 1.4B and 2.7B parameters, trained from scratch, a multimodal vision model that is pre-trained in the CLIP fashion, cross-modality interaction via an efficient projector. We evaluate MobileVLM on several typical VLM benchmarks. Our models demonstrate on par performance compared with a few much larger models. More importantly, we measure the inference speed on both a Qualcomm Snapdragon 888 CPU and an NVIDIA Jeston Orin GPU, and we obtain state-of-the-art performance of 21.5 tokens and 65.3 tokens per second, respectively. Our code will be made available at: https://github.com/Meituan-AutoML/MobileVLM.