 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArcMark: Multi-bit LLM Watermark via Optimal Transport
Feb 06, 2026Watermarking is an important tool for promoting the responsible use of language models (LMs). Existing watermarks insert a signal into generated tokens that either flags LM-generated text (zero-bit watermarking) or encodes more complex messages (multi-bit watermarking). Though a number of recent multi-bit watermarks insert several bits into text without perturbing average next-token predictions, they largely extend design principles from the zero-bit setting, such as encoding a single bit per token. Notably, the information-theoretic capacity of multi-bit watermarking -- the maximum number of bits per token that can be inserted and detected without changing average next-token predictions -- has remained unknown. We address this gap by deriving the first capacity characterization of multi-bit watermarks. Our results inform the design of ArcMark: a new watermark construction based on coding-theoretic principles that, under certain assumptions, achieves the capacity of the multi-bit watermark channel. In practice, ArcMark outperforms competing multi-bit watermarks in terms of bit rate per token and detection accuracy. Our work demonstrates that LM watermarking is fundamentally a channel coding problem, paving the way for principled coding-theoretic approaches to watermark design.
GeoClip: Geometry-Aware Clipping for Differentially Private SGD
Jun 06, 2025
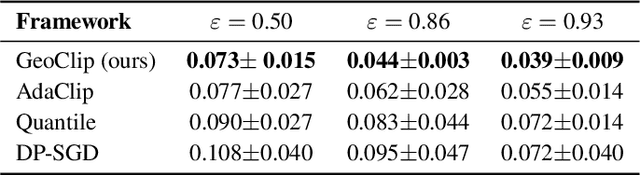


Differentially private stochastic gradient descent (DP-SGD) is the most widely used method for training machine learning models with provable privacy guarantees. A key challenge in DP-SGD is setting the per-sample gradient clipping threshold, which significantly affects the trade-off between privacy and utility. While recent adaptive methods improve performance by adjusting this threshold during training, they operate in the standard coordinate system and fail to account for correlations across the coordinates of the gradient. We propose GeoClip, a geometry-aware framework that clips and perturbs gradients in a transformed basis aligned with the geometry of the gradient distribution. GeoClip adaptively estimates this transformation using only previously released noisy gradients, incurring no additional privacy cost. We provide convergence guarantees for GeoClip and derive a closed-form solution for the optimal transformation that minimizes the amount of noise added while keeping the probability of gradient clipping under control. Experiments on both tabular and image datasets demonstrate that GeoClip consistently outperforms existing adaptive clipping methods under the same privacy budget.
POCAII: Parameter Optimization with Conscious Allocation using Iterative Intelligence
May 16, 2025In this paper we propose for the first time the hyperparameter optimization (HPO) algorithm POCAII. POCAII differs from the Hyperband and Successive Halving literature by explicitly separating the search and evaluation phases and utilizing principled approaches to exploration and exploitation principles during both phases. Such distinction results in a highly flexible scheme for managing a hyperparameter optimization budget by focusing on search (i.e., generating competing configurations) towards the start of the HPO process while increasing the evaluation effort as the HPO comes to an end. POCAII was compared to state of the art approaches SMAC, BOHB and DEHB. Our algorithm shows superior performance in low-budget hyperparameter optimization regimes. Since many practitioners do not have exhaustive resources to assign to HPO, it has wide applications to real-world problems. Moreover, the empirical evidence showed how POCAII demonstrates higher robustness and lower variance in the results. This is again very important when considering realistic scenarios with extremely expensive models to train.
Lower Bounds on the MMSE of Adversarially Inferring Sensitive Features
May 13, 2025We propose an adversarial evaluation framework for sensitive feature inference based on minimum mean-squared error (MMSE) estimation with a finite sample size and linear predictive models. Our approach establishes theoretical lower bounds on the true MMSE of inferring sensitive features from noisy observations of other correlated features. These bounds are expressed in terms of the empirical MMSE under a restricted hypothesis class and a non-negative error term. The error term captures both the estimation error due to finite number of samples and the approximation error from using a restricted hypothesis class. For linear predictive models, we derive closed-form bounds, which are order optimal in terms of the noise variance, on the approximation error for several classes of relationships between the sensitive and non-sensitive features, including linear mappings, binary symmetric channels, and class-conditional multi-variate Gaussian distributions. We also present a new lower bound that relies on the MSE computed on a hold-out validation dataset of the MMSE estimator learned on finite-samples and a restricted hypothesis class. Through empirical evaluation, we demonstrate that our framework serves as an effective tool for MMSE-based adversarial evaluation of sensitive feature inference that balances theoretical guarantees with practical efficiency.
Reveal-or-Obscure: A Differentially Private Sampling Algorithm for Discrete Distributions
Apr 20, 2025We introduce a differentially private (DP) algorithm called reveal-or-obscure (ROO) to generate a single representative sample from a dataset of $n$ observations drawn i.i.d. from an unknown discrete distribution $P$. Unlike methods that add explicit noise to the estimated empirical distribution, ROO achieves $\epsilon$-differential privacy by randomly choosing whether to "reveal" or "obscure" the empirical distribution. While ROO is structurally identical to Algorithm 1 proposed by Cheu and Nayak (arXiv:2412.10512), we prove a strictly better bound on the sampling complexity than that established in Theorem 12 of (arXiv:2412.10512). To further improve the privacy-utility trade-off, we propose a novel generalized sampling algorithm called Data-Specific ROO (DS-ROO), where the probability of obscuring the empirical distribution of the dataset is chosen adaptively. We prove that DS-ROO satisfies $\epsilon$-DP, and provide empirical evidence that DS-ROO can achieve better utility under the same privacy budget of vanilla ROO.
Label Noise Robustness for Domain-Agnostic Fair Corrections via Nearest Neighbors Label Spreading
Jun 13, 2024Last-layer retraining methods have emerged as an efficient framework for correcting existing base models. Within this framework, several methods have been proposed to deal with correcting models for subgroup fairness with and without group membership information. Importantly, prior work has demonstrated that many methods are susceptible to noisy labels. To this end, we propose a drop-in correction for label noise in last-layer retraining, and demonstrate that it achieves state-of-the-art worst-group accuracy for a broad range of symmetric label noise and across a wide variety of datasets exhibiting spurious correlations. Our proposed approach uses label spreading on a latent nearest neighbors graph and has minimal computational overhead compared to existing methods.
Theoretical Guarantees of Data Augmented Last Layer Retraining Methods
May 09, 2024



Ensuring fair predictions across many distinct subpopulations in the training data can be prohibitive for large models. Recently, simple linear last layer retraining strategies, in combination with data augmentation methods such as upweighting, downsampling and mixup, have been shown to achieve state-of-the-art performance for worst-group accuracy, which quantifies accuracy for the least prevalent subpopulation. For linear last layer retraining and the abovementioned augmentations, we present the optimal worst-group accuracy when modeling the distribution of the latent representations (input to the last layer) as Gaussian for each subpopulation. We evaluate and verify our results for both synthetic and large publicly available datasets.
An Adversarial Approach to Evaluating the Robustness of Event Identification Models
Feb 19, 2024



Intelligent machine learning approaches are finding active use for event detection and identification that allow real-time situational awareness. Yet, such machine learning algorithms have been shown to be susceptible to adversarial attacks on the incoming telemetry data. This paper considers a physics-based modal decomposition method to extract features for event classification and focuses on interpretable classifiers including logistic regression and gradient boosting to distinguish two types of events: load loss and generation loss. The resulting classifiers are then tested against an adversarial algorithm to evaluate their robustness. The adversarial attack is tested in two settings: the white box setting, wherein the attacker knows exactly the classification model; and the gray box setting, wherein the attacker has access to historical data from the same network as was used to train the classifier, but does not know the classification model. Thorough experiments on the synthetic South Carolina 500-bus system highlight that a relatively simpler model such as logistic regression is more susceptible to adversarial attacks than gradient boosting.
Robustness to Subpopulation Shift with Domain Label Noise via Regularized Annotation of Domains
Feb 16, 2024



Existing methods for last layer retraining that aim to optimize worst-group accuracy (WGA) rely heavily on well-annotated groups in the training data. We show, both in theory and practice, that annotation-based data augmentations using either downsampling or upweighting for WGA are susceptible to domain annotation noise, and in high-noise regimes approach the WGA of a model trained with vanilla empirical risk minimization. We introduce Regularized Annotation of Domains (RAD) in order to train robust last layer classifiers without the need for explicit domain annotations. Our results show that RAD is competitive with other recently proposed domain annotation-free techniques. Most importantly, RAD outperforms state-of-the-art annotation-reliant methods even with only 5% noise in the training data for several publicly available datasets.
Parameter Optimization with Conscious Allocation (POCA)
Dec 29, 2023



The performance of modern machine learning algorithms depends upon the selection of a set of hyperparameters. Common examples of hyperparameters are learning rate and the number of layers in a dense neural network. Auto-ML is a branch of optimization that has produced important contributions in this area. Within Auto-ML, hyperband-based approaches, which eliminate poorly-performing configurations after evaluating them at low budgets, are among the most effective. However, the performance of these algorithms strongly depends on how effectively they allocate the computational budget to various hyperparameter configurations. We present the new Parameter Optimization with Conscious Allocation (POCA), a hyperband-based algorithm that adaptively allocates the inputted budget to the hyperparameter configurations it generates following a Bayesian sampling scheme. We compare POCA to its nearest competitor at optimizing the hyperparameters of an artificial toy function and a deep neural network and find that POCA finds strong configurations faster in both settings.