 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing GAN Training Instabilities via Tunable Classification Losses
Oct 27, 2023



Generative adversarial networks (GANs), modeled as a zero-sum game between a generator (G) and a discriminator (D), allow generating synthetic data with formal guarantees. Noting that D is a classifier, we begin by reformulating the GAN value function using class probability estimation (CPE) losses. We prove a two-way correspondence between CPE loss GANs and $f$-GANs which minimize $f$-divergences. We also show that all symmetric $f$-divergences are equivalent in convergence. In the finite sample and model capacity setting, we define and obtain bounds on estimation and generalization errors. We specialize these results to $\alpha$-GANs, defined using $\alpha$-loss, a tunable CPE loss family parametrized by $\alpha\in(0,\infty]$. We next introduce a class of dual-objective GANs to address training instabilities of GANs by modeling each player's objective using $\alpha$-loss to obtain $(\alpha_D,\alpha_G)$-GANs. We show that the resulting non-zero sum game simplifies to minimizing an $f$-divergence under appropriate conditions on $(\alpha_D,\alpha_G)$. Generalizing this dual-objective formulation using CPE losses, we define and obtain upper bounds on an appropriately defined estimation error. Finally, we highlight the value of tuning $(\alpha_D,\alpha_G)$ in alleviating training instabilities for the synthetic 2D Gaussian mixture ring as well as the large publicly available Celeb-A and LSUN Classroom image datasets.
Towards Addressing GAN Training Instabilities: Dual-objective GANs with Tunable Parameters
Feb 28, 2023

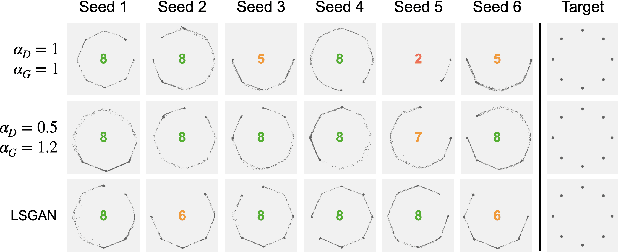

In an effort to address the training instabilities of GANs, we introduce a class of dual-objective GANs with different value functions (objectives) for the generator (G) and discriminator (D). In particular, we model each objective using $\alpha$-loss, a tunable classification loss, to obtain $(\alpha_D,\alpha_G)$-GANs, parameterized by $(\alpha_D,\alpha_G)\in [0,\infty)^2$. For sufficiently large number of samples and capacities for G and D, we show that the resulting non-zero sum game simplifies to minimizing an $f$-divergence under appropriate conditions on $(\alpha_D,\alpha_G)$. In the finite sample and capacity setting, we define estimation error to quantify the gap in the generator's performance relative to the optimal setting with infinite samples and obtain upper bounds on this error, showing it to be order optimal under certain conditions. Finally, we highlight the value of tuning $(\alpha_D,\alpha_G)$ in alleviating training instabilities for the synthetic 2D Gaussian mixture ring and the Stacked MNIST datasets.
AugLoss: A Learning Methodology for Real-World Dataset Corruption
Jun 05, 2022
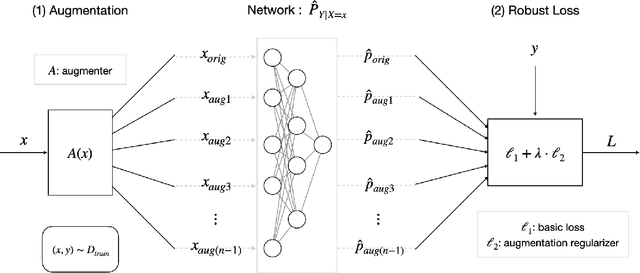
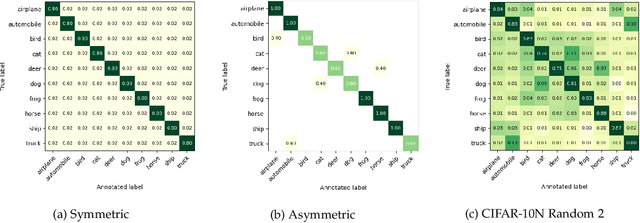
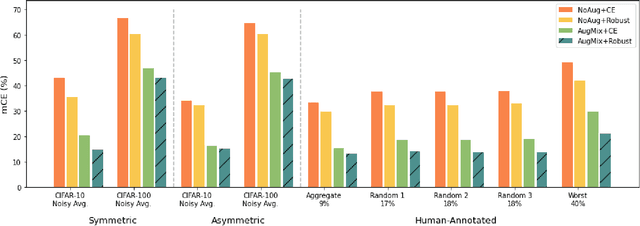
Deep Learning (DL) models achieve great successes in many domains. However, DL models increasingly face safety and robustness concerns, including noisy labeling in the training stage and feature distribution shifts in the testing stage. Previous works made significant progress in addressing these problems, but the focus has largely been on developing solutions for only one problem at a time. For example, recent work has argued for the use of tunable robust loss functions to mitigate label noise, and data augmentation (e.g., AugMix) to combat distribution shifts. As a step towards addressing both problems simultaneously, we introduce AugLoss, a simple but effective methodology that achieves robustness against both train-time noisy labeling and test-time feature distribution shifts by unifying data augmentation and robust loss functions. We conduct comprehensive experiments in varied settings of real-world dataset corruption to showcase the gains achieved by AugLoss compared to previous state-of-the-art methods. Lastly, we hope this work will open new directions for designing more robust and reliable DL models under real-world corruptions.