 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLower Bounds on the MMSE of Adversarially Inferring Sensitive Features
May 13, 2025We propose an adversarial evaluation framework for sensitive feature inference based on minimum mean-squared error (MMSE) estimation with a finite sample size and linear predictive models. Our approach establishes theoretical lower bounds on the true MMSE of inferring sensitive features from noisy observations of other correlated features. These bounds are expressed in terms of the empirical MMSE under a restricted hypothesis class and a non-negative error term. The error term captures both the estimation error due to finite number of samples and the approximation error from using a restricted hypothesis class. For linear predictive models, we derive closed-form bounds, which are order optimal in terms of the noise variance, on the approximation error for several classes of relationships between the sensitive and non-sensitive features, including linear mappings, binary symmetric channels, and class-conditional multi-variate Gaussian distributions. We also present a new lower bound that relies on the MSE computed on a hold-out validation dataset of the MMSE estimator learned on finite-samples and a restricted hypothesis class. Through empirical evaluation, we demonstrate that our framework serves as an effective tool for MMSE-based adversarial evaluation of sensitive feature inference that balances theoretical guarantees with practical efficiency.
Theoretical Guarantees of Data Augmented Last Layer Retraining Methods
May 09, 2024



Ensuring fair predictions across many distinct subpopulations in the training data can be prohibitive for large models. Recently, simple linear last layer retraining strategies, in combination with data augmentation methods such as upweighting, downsampling and mixup, have been shown to achieve state-of-the-art performance for worst-group accuracy, which quantifies accuracy for the least prevalent subpopulation. For linear last layer retraining and the abovementioned augmentations, we present the optimal worst-group accuracy when modeling the distribution of the latent representations (input to the last layer) as Gaussian for each subpopulation. We evaluate and verify our results for both synthetic and large publicly available datasets.
Robustness to Subpopulation Shift with Domain Label Noise via Regularized Annotation of Domains
Feb 16, 2024



Existing methods for last layer retraining that aim to optimize worst-group accuracy (WGA) rely heavily on well-annotated groups in the training data. We show, both in theory and practice, that annotation-based data augmentations using either downsampling or upweighting for WGA are susceptible to domain annotation noise, and in high-noise regimes approach the WGA of a model trained with vanilla empirical risk minimization. We introduce Regularized Annotation of Domains (RAD) in order to train robust last layer classifiers without the need for explicit domain annotations. Our results show that RAD is competitive with other recently proposed domain annotation-free techniques. Most importantly, RAD outperforms state-of-the-art annotation-reliant methods even with only 5% noise in the training data for several publicly available datasets.
Addressing GAN Training Instabilities via Tunable Classification Losses
Oct 27, 2023



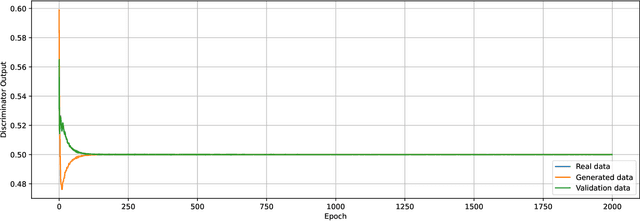
Generative adversarial networks (GANs), modeled as a zero-sum game between a generator (G) and a discriminator (D), allow generating synthetic data with formal guarantees. Noting that D is a classifier, we begin by reformulating the GAN value function using class probability estimation (CPE) losses. We prove a two-way correspondence between CPE loss GANs and $f$-GANs which minimize $f$-divergences. We also show that all symmetric $f$-divergences are equivalent in convergence. In the finite sample and model capacity setting, we define and obtain bounds on estimation and generalization errors. We specialize these results to $\alpha$-GANs, defined using $\alpha$-loss, a tunable CPE loss family parametrized by $\alpha\in(0,\infty]$. We next introduce a class of dual-objective GANs to address training instabilities of GANs by modeling each player's objective using $\alpha$-loss to obtain $(\alpha_D,\alpha_G)$-GANs. We show that the resulting non-zero sum game simplifies to minimizing an $f$-divergence under appropriate conditions on $(\alpha_D,\alpha_G)$. Generalizing this dual-objective formulation using CPE losses, we define and obtain upper bounds on an appropriately defined estimation error. Finally, we highlight the value of tuning $(\alpha_D,\alpha_G)$ in alleviating training instabilities for the synthetic 2D Gaussian mixture ring as well as the large publicly available Celeb-A and LSUN Classroom image datasets.
Towards Addressing GAN Training Instabilities: Dual-objective GANs with Tunable Parameters
Feb 28, 2023

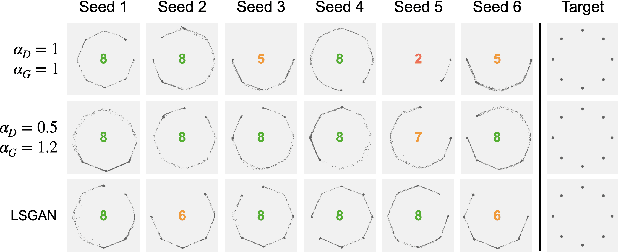

In an effort to address the training instabilities of GANs, we introduce a class of dual-objective GANs with different value functions (objectives) for the generator (G) and discriminator (D). In particular, we model each objective using $\alpha$-loss, a tunable classification loss, to obtain $(\alpha_D,\alpha_G)$-GANs, parameterized by $(\alpha_D,\alpha_G)\in [0,\infty)^2$. For sufficiently large number of samples and capacities for G and D, we show that the resulting non-zero sum game simplifies to minimizing an $f$-divergence under appropriate conditions on $(\alpha_D,\alpha_G)$. In the finite sample and capacity setting, we define estimation error to quantify the gap in the generator's performance relative to the optimal setting with infinite samples and obtain upper bounds on this error, showing it to be order optimal under certain conditions. Finally, we highlight the value of tuning $(\alpha_D,\alpha_G)$ in alleviating training instabilities for the synthetic 2D Gaussian mixture ring and the Stacked MNIST datasets.
$α$-GAN: Convergence and Estimation Guarantees
May 12, 2022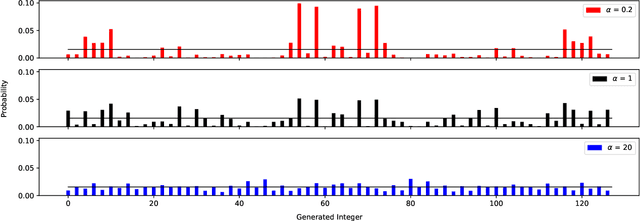


We prove a two-way correspondence between the min-max optimization of general CPE loss function GANs and the minimization of associated $f$-divergences. We then focus on $\alpha$-GAN, defined via the $\alpha$-loss, which interpolates several GANs (Hellinger, vanilla, Total Variation) and corresponds to the minimization of the Arimoto divergence. We show that the Arimoto divergences induced by $\alpha$-GAN equivalently converge, for all $\alpha\in \mathbb{R}_{>0}\cup\{\infty\}$. However, under restricted learning models and finite samples, we provide estimation bounds which indicate diverse GAN behavior as a function of $\alpha$. Finally, we present empirical results on a toy dataset that highlight the practical utility of tuning the $\alpha$ hyperparameter.