 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$α$-GAN: Convergence and Estimation Guarantees
Paper and Code
May 12, 2022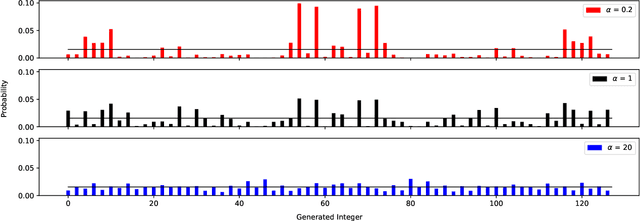

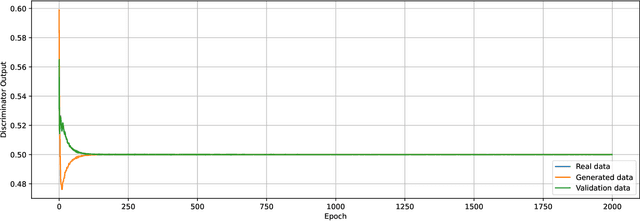

We prove a two-way correspondence between the min-max optimization of general CPE loss function GANs and the minimization of associated $f$-divergences. We then focus on $\alpha$-GAN, defined via the $\alpha$-loss, which interpolates several GANs (Hellinger, vanilla, Total Variation) and corresponds to the minimization of the Arimoto divergence. We show that the Arimoto divergences induced by $\alpha$-GAN equivalently converge, for all $\alpha\in \mathbb{R}_{>0}\cup\{\infty\}$. However, under restricted learning models and finite samples, we provide estimation bounds which indicate diverse GAN behavior as a function of $\alpha$. Finally, we present empirical results on a toy dataset that highlight the practical utility of tuning the $\alpha$ hyperparameter.