 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeasoning Generative Models for a Generalization Aftertaste
Mar 19, 2026The use of discriminators to train or fine-tune generative models has proven to be a rather successful framework. A notable example is Generative Adversarial Networks (GANs) that minimize a loss incurred by training discriminators along with other paradigms that boost generative models via discriminators that satisfy weak learner constraints. More recently, even diffusion models have shown advantages with some kind of discriminator guidance. In this work, we extend a strong-duality result related to $f$-divergences which gives rise to a discriminator-guided recipe that allows us to \textit{refine} any generative model. We then show that the refined generative models provably improve generalization, compared to its non-refined counterpart. In particular, our analysis reveals that the gap in generalization is improved based on the Rademacher complexity of the discriminator set used for refinement. Our recipe subsumes a recently introduced score-based diffusion approach (Kim et al., 2022) that has shown great empirical success, however allows us to shed light on the generalization guarantees of this method by virtue of our analysis. Thus, our work provides a theoretical validation for existing work, suggests avenues for new algorithms, and contributes to our understanding of generalization in generative models at large.
Principled Foundations for Preference Optimization
Jul 10, 2025In this paper, we show that direct preference optimization (DPO) is a very specific form of a connection between two major theories in the ML context of learning from preferences: loss functions (Savage) and stochastic choice (Doignon-Falmagne and Machina). The connection is established for all of Savage's losses and at this level of generality, (i) it includes support for abstention on the choice theory side, (ii) it includes support for non-convex objectives on the ML side, and (iii) it allows to frame for free some notable extensions of the DPO setting, including margins and corrections for length. Getting to understand how DPO operates from a general principled perspective is crucial because of the huge and diverse application landscape of models, because of the current momentum around DPO, but also -- and importantly -- because many state of the art variations on DPO definitely occupy a small region of the map that we cover. It also helps to understand the pitfalls of departing from this map, and figure out workarounds.
How to Boost Any Loss Function
Jul 02, 2024Boosting is a highly successful ML-born optimization setting in which one is required to computationally efficiently learn arbitrarily good models based on the access to a weak learner oracle, providing classifiers performing at least slightly differently from random guessing. A key difference with gradient-based optimization is that boosting's original model does not requires access to first order information about a loss, yet the decades long history of boosting has quickly evolved it into a first order optimization setting -- sometimes even wrongfully \textit{defining} it as such. Owing to recent progress extending gradient-based optimization to use only a loss' zeroth ($0^{th}$) order information to learn, this begs the question: what loss functions can be efficiently optimized with boosting and what is the information really needed for boosting to meet the \textit{original} boosting blueprint's requirements? We provide a constructive formal answer essentially showing that \textit{any} loss function can be optimized with boosting and thus boosting can achieve a feat not yet known to be possible in the classical $0^{th}$ order setting, since loss functions are not required to be be convex, nor differentiable or Lipschitz -- and in fact not required to be continuous either. Some tools we use are rooted in quantum calculus, the mathematical field -- not to be confounded with quantum computation -- that studies calculus without passing to the limit, and thus without using first order information.
Label Noise Robustness for Domain-Agnostic Fair Corrections via Nearest Neighbors Label Spreading
Jun 13, 2024Last-layer retraining methods have emerged as an efficient framework for correcting existing base models. Within this framework, several methods have been proposed to deal with correcting models for subgroup fairness with and without group membership information. Importantly, prior work has demonstrated that many methods are susceptible to noisy labels. To this end, we propose a drop-in correction for label noise in last-layer retraining, and demonstrate that it achieves state-of-the-art worst-group accuracy for a broad range of symmetric label noise and across a wide variety of datasets exhibiting spurious correlations. Our proposed approach uses label spreading on a latent nearest neighbors graph and has minimal computational overhead compared to existing methods.
Boosting gets full Attention for Relational Learning
Feb 22, 2024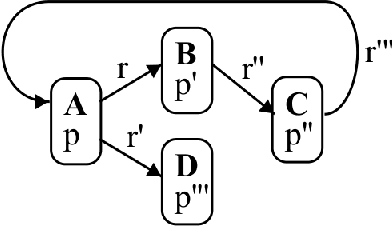
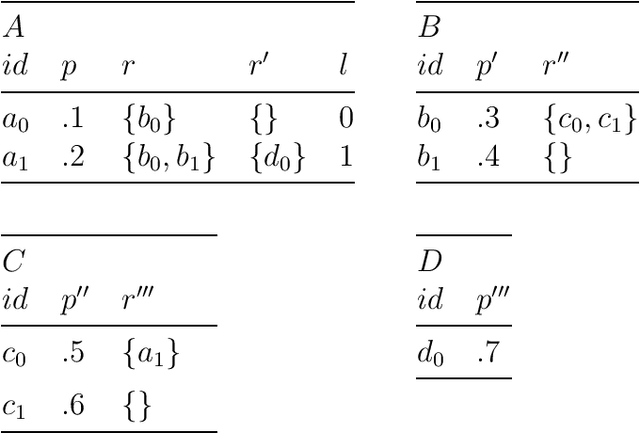
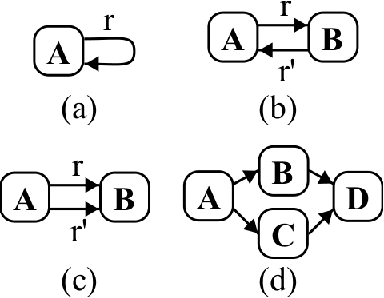

More often than not in benchmark supervised ML, tabular data is flat, i.e. consists of a single $m \times d$ (rows, columns) file, but cases abound in the real world where observations are described by a set of tables with structural relationships. Neural nets-based deep models are a classical fit to incorporate general topological dependence among description features (pixels, words, etc.), but their suboptimality to tree-based models on tabular data is still well documented. In this paper, we introduce an attention mechanism for structured data that blends well with tree-based models in the training context of (gradient) boosting. Each aggregated model is a tree whose training involves two steps: first, simple tabular models are learned descending tables in a top-down fashion with boosting's class residuals on tables' features. Second, what has been learned progresses back bottom-up via attention and aggregation mechanisms, progressively crafting new features that complete at the end the set of observation features over which a single tree is learned, boosting's iteration clock is incremented and new class residuals are computed. Experiments on simulated and real-world domains display the competitiveness of our method against a state of the art containing both tree-based and neural nets-based models.
Tempered Calculus for ML: Application to Hyperbolic Model Embedding
Feb 08, 2024



Most mathematical distortions used in ML are fundamentally integral in nature: $f$-divergences, Bregman divergences, (regularized) optimal transport distances, integral probability metrics, geodesic distances, etc. In this paper, we unveil a grounded theory and tools which can help improve these distortions to better cope with ML requirements. We start with a generalization of Riemann integration that also encapsulates functions that are not strictly additive but are, more generally, $t$-additive, as in nonextensive statistical mechanics. Notably, this recovers Volterra's product integral as a special case. We then generalize the Fundamental Theorem of calculus using an extension of the (Euclidean) derivative. This, along with a series of more specific Theorems, serves as a basis for results showing how one can specifically design, alter, or change fundamental properties of distortion measures in a simple way, with a special emphasis on geometric- and ML-related properties that are the metricity, hyperbolicity, and encoding. We show how to apply it to a problem that has recently gained traction in ML: hyperbolic embeddings with a "cheap" and accurate encoding along the hyperbolic vs Euclidean scale. We unveil a new application for which the Poincar\'e disk model has very appealing features, and our theory comes in handy: \textit{model} embeddings for boosted combinations of decision trees, trained using the log-loss (trees) and logistic loss (combinations).
The Tempered Hilbert Simplex Distance and Its Application To Non-linear Embeddings of TEMs
Nov 22, 2023



Tempered Exponential Measures (TEMs) are a parametric generalization of the exponential family of distributions maximizing the tempered entropy function among positive measures subject to a probability normalization of their power densities. Calculus on TEMs relies on a deformed algebra of arithmetic operators induced by the deformed logarithms used to define the tempered entropy. In this work, we introduce three different parameterizations of finite discrete TEMs via Legendre functions of the negative tempered entropy function. In particular, we establish an isometry between such parameterizations in terms of a generalization of the Hilbert log cross-ratio simplex distance to a tempered Hilbert co-simplex distance. Similar to the Hilbert geometry, the tempered Hilbert distance is characterized as a $t$-symmetrization of the oriented tempered Funk distance. We motivate our construction by introducing the notion of $t$-lengths of smooth curves in a tautological Finsler manifold. We then demonstrate the properties of our generalized structure in different settings and numerically examine the quality of its differentiable approximations for optimization in machine learning settings.
Optimal Transport with Tempered Exponential Measures
Sep 07, 2023In the field of optimal transport, two prominent subfields face each other: (i) unregularized optimal transport, ``\`a-la-Kantorovich'', which leads to extremely sparse plans but with algorithms that scale poorly, and (ii) entropic-regularized optimal transport, ``\`a-la-Sinkhorn-Cuturi'', which gets near-linear approximation algorithms but leads to maximally un-sparse plans. In this paper, we show that a generalization of the latter to tempered exponential measures, a generalization of exponential families with indirect measure normalization, gets to a very convenient middle ground, with both very fast approximation algorithms and sparsity which is under control up to sparsity patterns. In addition, it fits naturally in the unbalanced optimal transport problem setting as well.
Generative Forests
Aug 07, 2023Tabular data represents one of the most prevalent form of data. When it comes to data generation, many approaches would learn a density for the data generation process, but would not necessarily end up with a sampler, even less so being exact with respect to the underlying density. A second issue is on models: while complex modeling based on neural nets thrives in image or text generation (etc.), less is known for powerful generative models on tabular data. A third problem is the visible chasm on tabular data between training algorithms for supervised learning with remarkable properties (e.g. boosting), and a comparative lack of guarantees when it comes to data generation. In this paper, we tackle the three problems, introducing new tree-based generative models convenient for density modeling and tabular data generation that improve on modeling capabilities of recent proposals, and a training algorithm which simplifies the training setting of previous approaches and displays boosting-compliant convergence. This algorithm has the convenient property to rely on a supervised training scheme that can be implemented by a few tweaks to the most popular induction scheme for decision tree induction with two classes. Experiments are provided on missing data imputation and comparing generated data to real data, displaying the quality of the results obtained by our approach, in particular against state of the art.
Boosting with Tempered Exponential Measures
Jun 08, 2023



One of the most popular ML algorithms, AdaBoost, can be derived from the dual of a relative entropy minimization problem subject to the fact that the positive weights on the examples sum to one. Essentially, harder examples receive higher probabilities. We generalize this setup to the recently introduced {\it tempered exponential measure}s (TEMs) where normalization is enforced on a specific power of the measure and not the measure itself. TEMs are indexed by a parameter $t$ and generalize exponential families ($t=1$). Our algorithm, $t$-AdaBoost, recovers AdaBoost~as a special case ($t=1$). We show that $t$-AdaBoost retains AdaBoost's celebrated exponential convergence rate when $t\in [0,1)$ while allowing a slight improvement of the rate's hidden constant compared to $t=1$. $t$-AdaBoost partially computes on a generalization of classical arithmetic over the reals and brings notable properties like guaranteed bounded leveraging coefficients for $t\in [0,1)$. From the loss that $t$-AdaBoost minimizes (a generalization of the exponential loss), we show how to derive a new family of {\it tempered} losses for the induction of domain-partitioning classifiers like decision trees. Crucially, strict properness is ensured for all while their boosting rates span the full known spectrum. Experiments using $t$-AdaBoost+trees display that significant leverage can be achieved by tuning $t$.