 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting gets full Attention for Relational Learning
Feb 22, 2024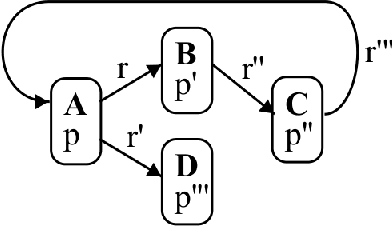
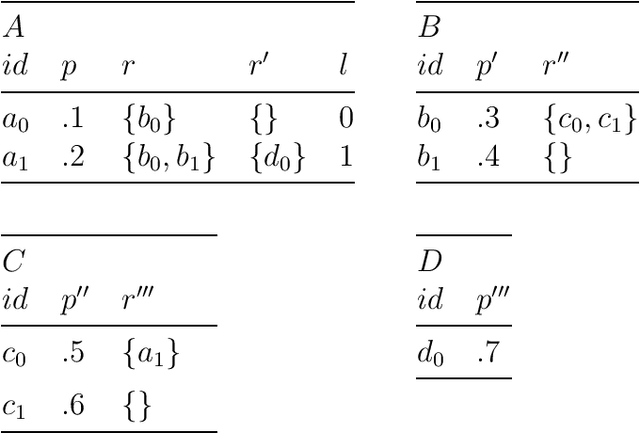

More often than not in benchmark supervised ML, tabular data is flat, i.e. consists of a single $m \times d$ (rows, columns) file, but cases abound in the real world where observations are described by a set of tables with structural relationships. Neural nets-based deep models are a classical fit to incorporate general topological dependence among description features (pixels, words, etc.), but their suboptimality to tree-based models on tabular data is still well documented. In this paper, we introduce an attention mechanism for structured data that blends well with tree-based models in the training context of (gradient) boosting. Each aggregated model is a tree whose training involves two steps: first, simple tabular models are learned descending tables in a top-down fashion with boosting's class residuals on tables' features. Second, what has been learned progresses back bottom-up via attention and aggregation mechanisms, progressively crafting new features that complete at the end the set of observation features over which a single tree is learned, boosting's iteration clock is incremented and new class residuals are computed. Experiments on simulated and real-world domains display the competitiveness of our method against a state of the art containing both tree-based and neural nets-based models.
Generative Forests
Aug 07, 2023Tabular data represents one of the most prevalent form of data. When it comes to data generation, many approaches would learn a density for the data generation process, but would not necessarily end up with a sampler, even less so being exact with respect to the underlying density. A second issue is on models: while complex modeling based on neural nets thrives in image or text generation (etc.), less is known for powerful generative models on tabular data. A third problem is the visible chasm on tabular data between training algorithms for supervised learning with remarkable properties (e.g. boosting), and a comparative lack of guarantees when it comes to data generation. In this paper, we tackle the three problems, introducing new tree-based generative models convenient for density modeling and tabular data generation that improve on modeling capabilities of recent proposals, and a training algorithm which simplifies the training setting of previous approaches and displays boosting-compliant convergence. This algorithm has the convenient property to rely on a supervised training scheme that can be implemented by a few tweaks to the most popular induction scheme for decision tree induction with two classes. Experiments are provided on missing data imputation and comparing generated data to real data, displaying the quality of the results obtained by our approach, in particular against state of the art.
Yggdrasil Decision Forests: A Fast and Extensible Decision Forests Library
Dec 06, 2022Yggdrasil Decision Forests is a library for the training, serving and interpretation of decision forest models, targeted both at research and production work, implemented in C++, and available in C++, command line interface, Python (under the name TensorFlow Decision Forests), JavaScript, and Go. The library has been developed organically since 2018 following a set of four design principles applicable to machine learning libraries and frameworks: simplicity of use, safety of use, modularity and high-level abstraction, and integration with other machine learning libraries. In this paper, we describe those principles in detail and present how they have been used to guide the design of the library. We then showcase the use of our library on a set of classical machine learning problems. Finally, we report a benchmark comparing our library to related solutions.
Generative Trees: Adversarial and Copycat
Jan 26, 2022



While Generative Adversarial Networks (GANs) achieve spectacular results on unstructured data like images, there is still a gap on tabular data, data for which state of the art supervised learning still favours to a large extent decision tree (DT)-based models. This paper proposes a new path forward for the generation of tabular data, exploiting decades-old understanding of the supervised task's best components for DT induction, from losses (properness), models (tree-based) to algorithms (boosting). The \textit{properness} condition on the supervised loss -- which postulates the optimality of Bayes rule -- leads us to a variational GAN-style loss formulation which is \textit{tight} when discriminators meet a calibration property trivially satisfied by DTs, and, under common assumptions about the supervised loss, yields "one loss to train against them all" for the generator: the $\chi^2$. We then introduce tree-based generative models, \textit{generative trees} (GTs), meant to mirror on the generative side the good properties of DTs for classifying tabular data, with a boosting-compliant \textit{adversarial} training algorithm for GTs. We also introduce \textit{copycat training}, in which the generator copies at run time the underlying tree (graph) of the discriminator DT and completes it for the hardest discriminative task, with boosting compliant convergence. We test our algorithms on tasks including fake/real distinction, training from fake data and missing data imputation. Each one of these tasks displays that GTs can provide comparatively simple -- and interpretable -- contenders to sophisticated state of the art methods for data generation (using neural network models) or missing data imputation (relying on multiple imputation by chained equations with complex tree-based modeling).
Modeling Text with Decision Forests using Categorical-Set Splits
Sep 28, 2020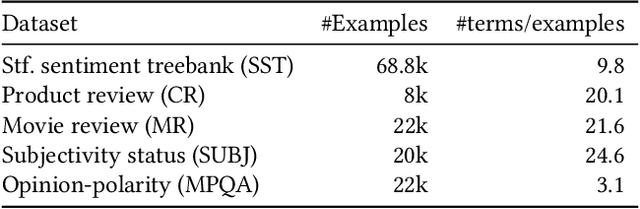
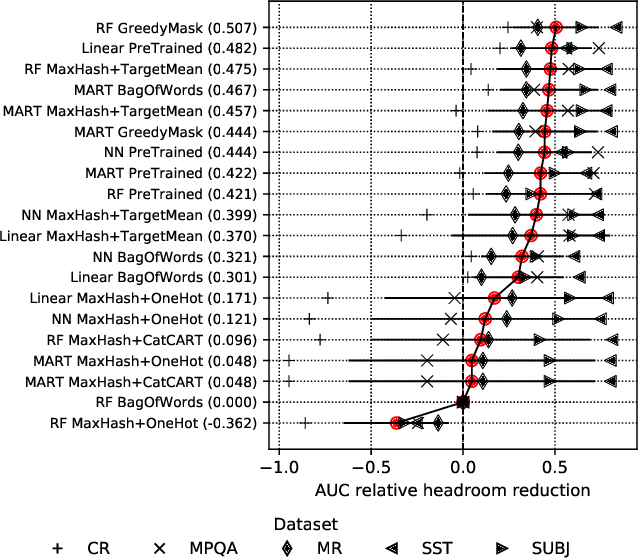
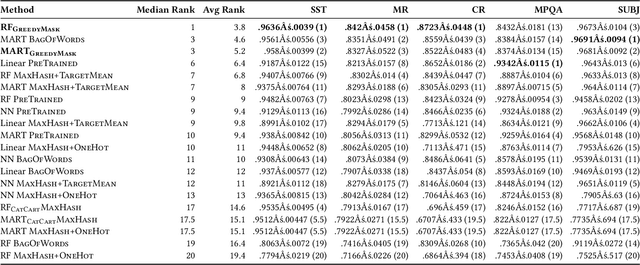
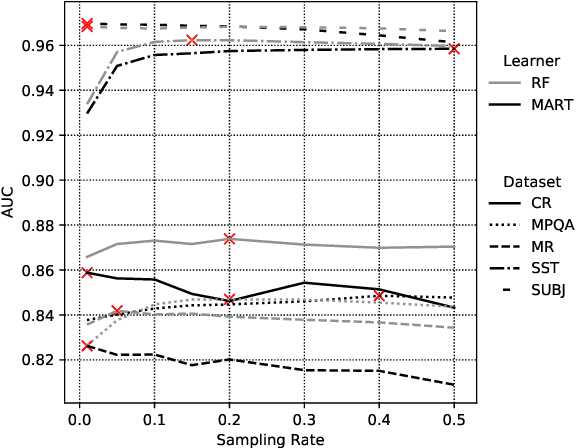
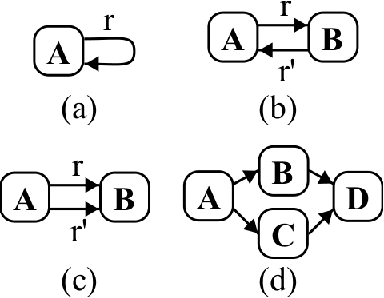
Decision forest algorithms model data by learning a binary tree structure recursively where every node splits the feature space into two regions, sending examples into the left or right branches. This "decision" is the result of the evaluation of a condition. For example, a node may split input data by applying a threshold to a numerical feature value. Such decisions are learned using (often greedy) algorithms that attempt to optimize a local loss function. Crucially, whether an algorithm exists to find and evaluate splits for a feature type (e.g., text) determines whether a decision forest algorithm can model that feature type at all. In this work, we set out to devise such an algorithm for textual features, thereby equipping decision forests with the ability to directly model text without the need for feature transformation. Our algorithm is efficient during training and the resulting splits are fast to evaluate with our extension of the QuickScorer inference algorithm. Experiments on benchmark text classification datasets demonstrate the utility and effectiveness of our proposal.
Exact Distributed Training: Random Forest with Billions of Examples
Apr 18, 2018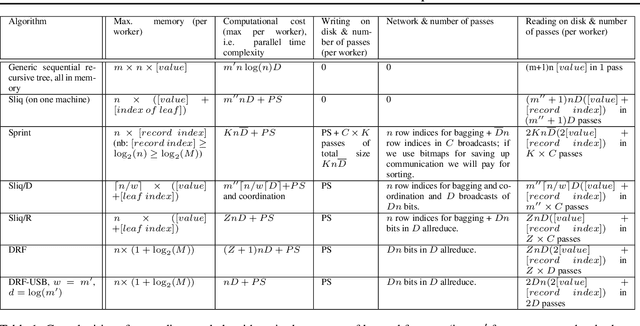
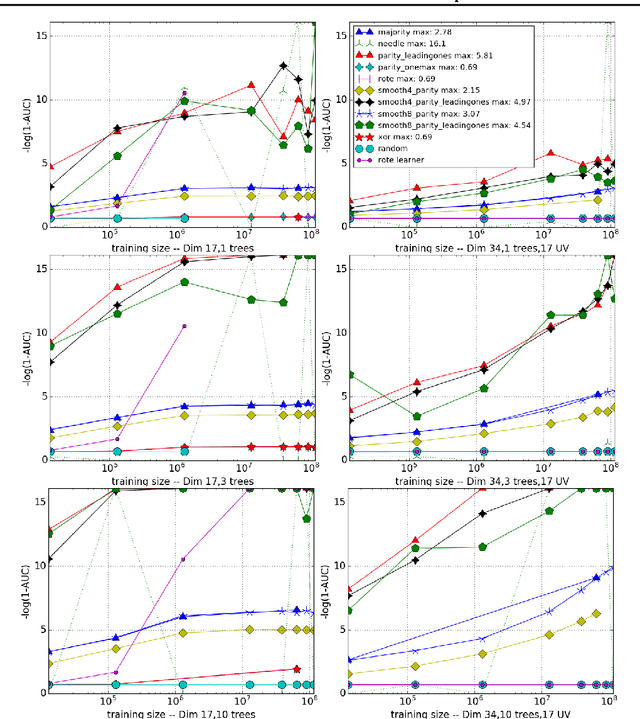
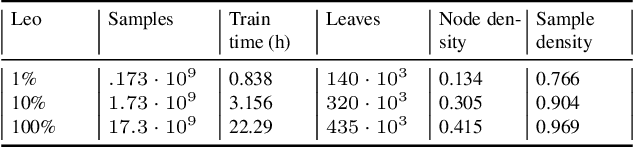
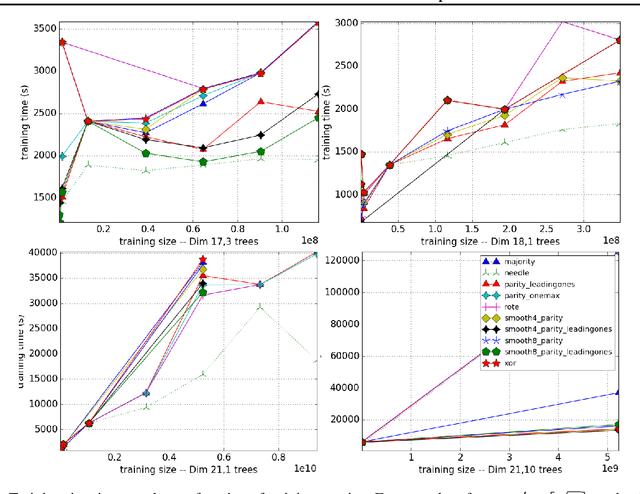
We introduce an exact distributed algorithm to train Random Forest models as well as other decision forest models without relying on approximating best split search. We explain the proposed algorithm and compare it to related approaches for various complexity measures (time, ram, disk, and network complexity analysis). We report its running performances on artificial and real-world datasets of up to 18 billions examples. This figure is several orders of magnitude larger than datasets tackled in the existing literature. Finally, we empirically show that Random Forest benefits from being trained on more data, even in the case of already gigantic datasets. Given a dataset with 17.3B examples with 82 features (3 numerical, other categorical with high arity), our implementation trains a tree in 22h.
Batched Lazy Decision Trees
Mar 08, 2016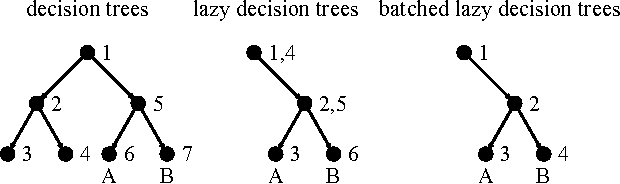


We introduce a batched lazy algorithm for supervised classification using decision trees. It avoids unnecessary visits to irrelevant nodes when it is used to make predictions with either eagerly or lazily trained decision trees. A set of experiments demonstrate that the proposed algorithm can outperform both the conventional and lazy decision tree algorithms in terms of computation time as well as memory consumption, without compromising accuracy.