 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Text with Decision Forests using Categorical-Set Splits
Paper and Code
Sep 28, 2020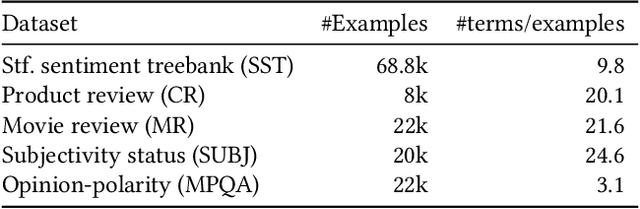
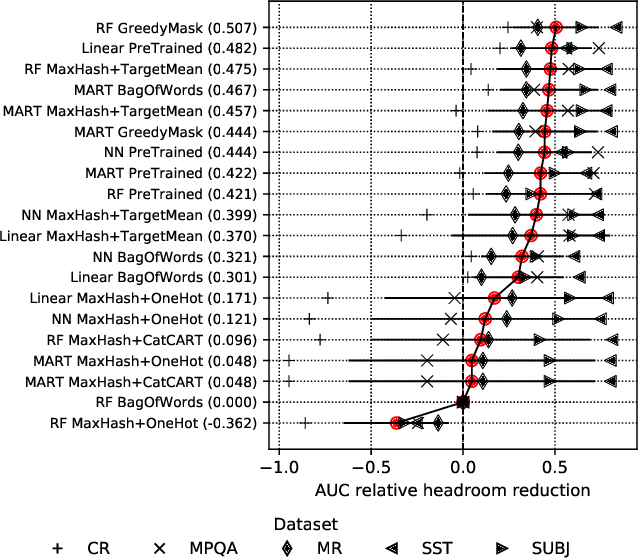
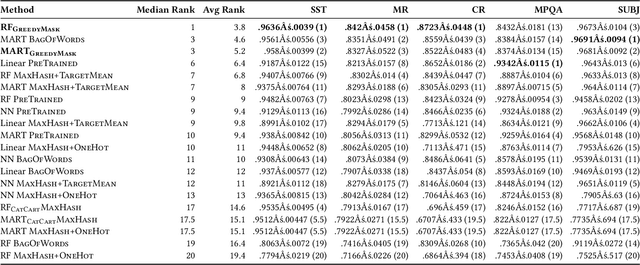
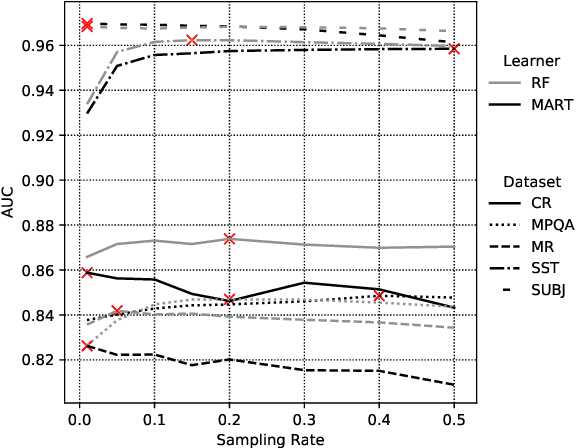
Decision forest algorithms model data by learning a binary tree structure recursively where every node splits the feature space into two regions, sending examples into the left or right branches. This "decision" is the result of the evaluation of a condition. For example, a node may split input data by applying a threshold to a numerical feature value. Such decisions are learned using (often greedy) algorithms that attempt to optimize a local loss function. Crucially, whether an algorithm exists to find and evaluate splits for a feature type (e.g., text) determines whether a decision forest algorithm can model that feature type at all. In this work, we set out to devise such an algorithm for textual features, thereby equipping decision forests with the ability to directly model text without the need for feature transformation. Our algorithm is efficient during training and the resulting splits are fast to evaluate with our extension of the QuickScorer inference algorithm. Experiments on benchmark text classification datasets demonstrate the utility and effectiveness of our proposal.