 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Distributed Training: Random Forest with Billions of Examples
Paper and Code
Apr 18, 2018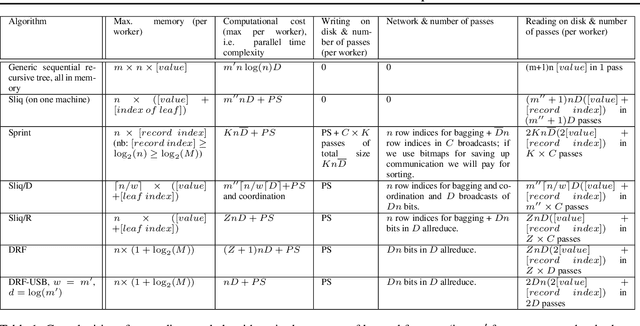
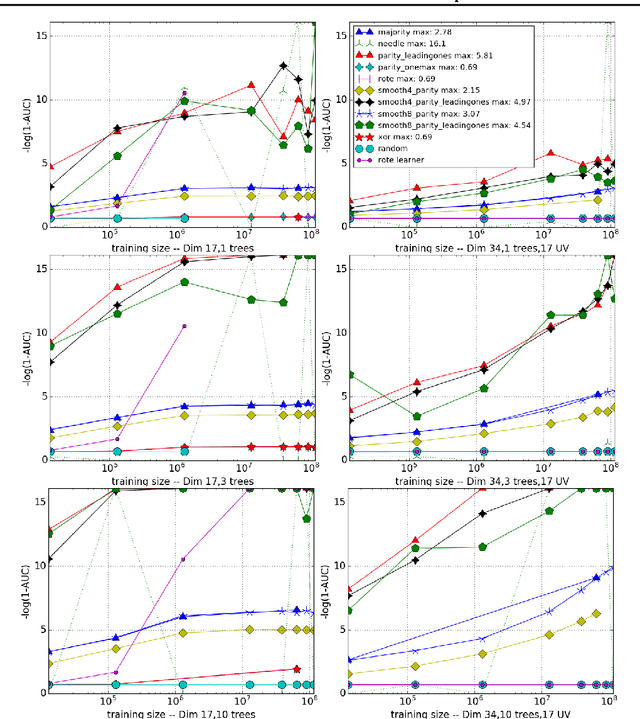
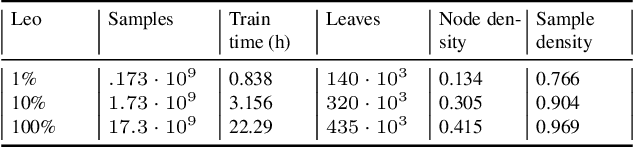
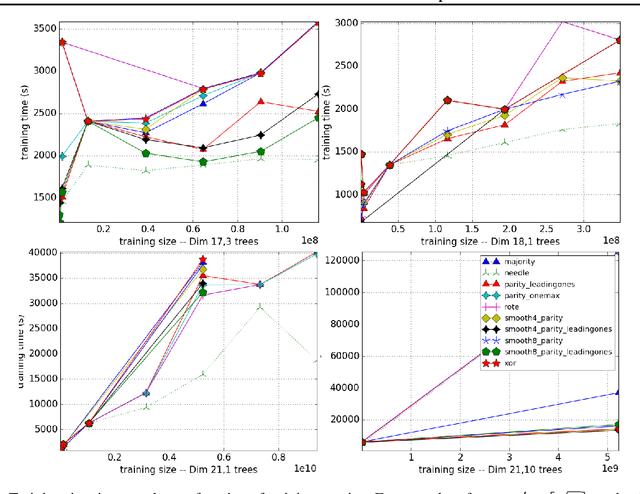
We introduce an exact distributed algorithm to train Random Forest models as well as other decision forest models without relying on approximating best split search. We explain the proposed algorithm and compare it to related approaches for various complexity measures (time, ram, disk, and network complexity analysis). We report its running performances on artificial and real-world datasets of up to 18 billions examples. This figure is several orders of magnitude larger than datasets tackled in the existing literature. Finally, we empirically show that Random Forest benefits from being trained on more data, even in the case of already gigantic datasets. Given a dataset with 17.3B examples with 82 features (3 numerical, other categorical with high arity), our implementation trains a tree in 22h.