 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning without Peeking: Provable Privacy and Generalization Bounds for LLM Post-Training
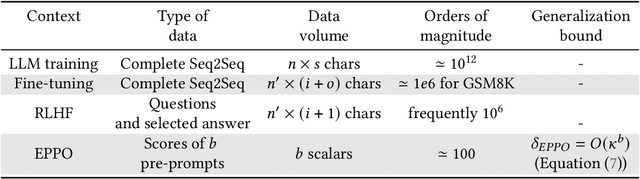
Jul 02, 2025Gradient-based optimization is the workhorse of deep learning, offering efficient and scalable training via backpropagation. However, its reliance on large volumes of labeled data raises privacy and security concerns such as susceptibility to data poisoning attacks and the risk of overfitting. In contrast, black box optimization methods, which treat the model as an opaque function, relying solely on function evaluations to guide optimization, offer a promising alternative in scenarios where data access is restricted, adversarial risks are high, or overfitting is a concern. However, black box methods also pose significant challenges, including poor scalability to high-dimensional parameter spaces, as prevalent in large language models (LLMs), and high computational costs due to reliance on numerous model evaluations. This paper introduces BBoxER, an evolutionary black-box method for LLM post-training that induces an information bottleneck via implicit compression of the training data. Leveraging the tractability of information flow, we provide strong theoretical bounds on generalization, differential privacy, susceptibility to data poisoning attacks, and robustness to extraction attacks. BBoxER operates on top of pre-trained LLMs, offering a lightweight and modular enhancement suitable for deployment in restricted or privacy-sensitive environments, in addition to non-vacuous generalization guarantees. In experiments with LLMs, we demonstrate empirically that Retrofitting methods are able to learn, showing how a few iterations of BBoxER improve performance and generalize well on a benchmark of reasoning datasets. This positions BBoxER as an attractive add-on on top of gradient-based optimization.
From Bytes to Ideas: Language Modeling with Autoregressive U-Nets
Jun 17, 2025Tokenization imposes a fixed granularity on the input text, freezing how a language model operates on data and how far in the future it predicts. Byte Pair Encoding (BPE) and similar schemes split text once, build a static vocabulary, and leave the model stuck with that choice. We relax this rigidity by introducing an autoregressive U-Net that learns to embed its own tokens as it trains. The network reads raw bytes, pools them into words, then pairs of words, then up to 4 words, giving it a multi-scale view of the sequence. At deeper stages, the model must predict further into the future -- anticipating the next few words rather than the next byte -- so deeper stages focus on broader semantic patterns while earlier stages handle fine details. When carefully tuning and controlling pretraining compute, shallow hierarchies tie strong BPE baselines, and deeper hierarchies have a promising trend. Because tokenization now lives inside the model, the same system can handle character-level tasks and carry knowledge across low-resource languages.
Evolutionary Pre-Prompt Optimization for Mathematical Reasoning
Dec 05, 2024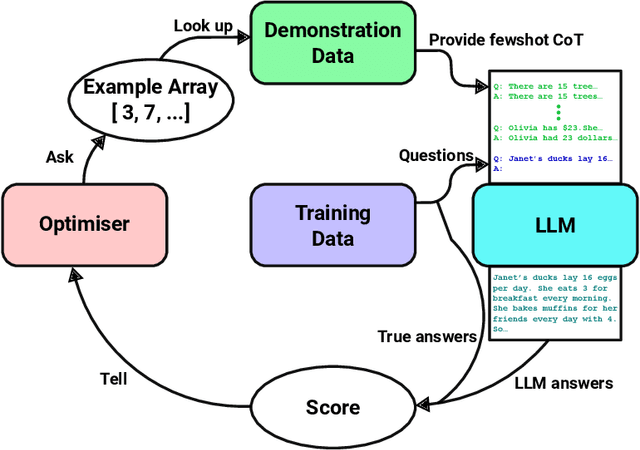
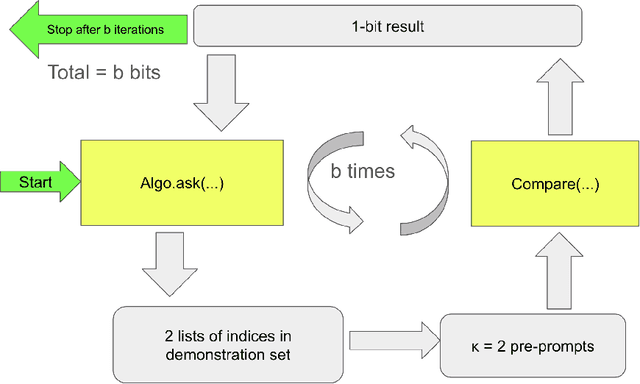
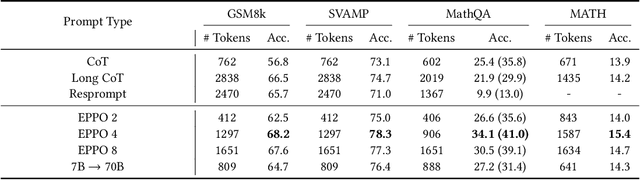
Recent advancements have highlighted that large language models (LLMs), when given a small set of task-specific examples, demonstrate remarkable proficiency, a capability that extends to complex reasoning tasks. In particular, the combination of few-shot learning with the chain-of-thought (CoT) approach has been pivotal in steering models towards more logically consistent conclusions. This paper explores the optimization of example selection for designing effective CoT pre-prompts and shows that the choice of the optimization algorithm, typically in favor of comparison-based methods such as evolutionary computation, significantly enhances efficacy and feasibility. Specifically, thanks to a limited exploitative and overfitted optimization, Evolutionary Pre-Prompt Optimization (EPPO) brings an improvement over the naive few-shot approach exceeding 10 absolute points in exact match scores on benchmark datasets such as GSM8k and MathQA. These gains are consistent across various contexts and are further amplified when integrated with self-consistency (SC)
Mixture of Experts in Image Classification: What's the Sweet Spot?
Nov 27, 2024
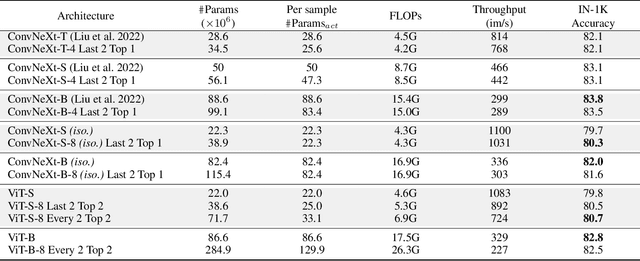

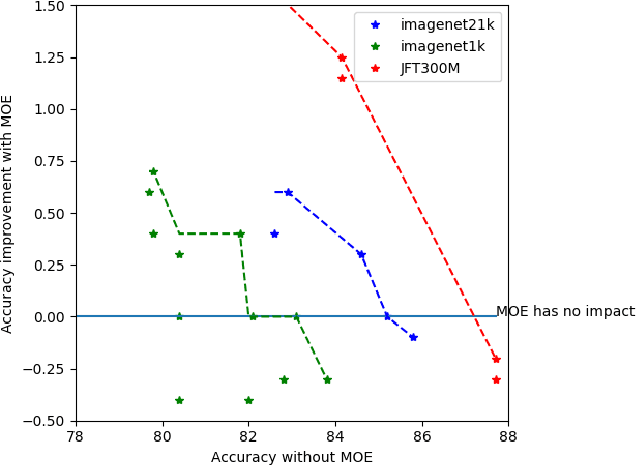
Mixture-of-Experts (MoE) models have shown promising potential for parameter-efficient scaling across various domains. However, the implementation in computer vision remains limited, and often requires large-scale datasets comprising billions of samples. In this study, we investigate the integration of MoE within computer vision models and explore various MoE configurations on open datasets. When introducing MoE layers in image classification, the best results are obtained for models with a moderate number of activated parameters per sample. However, such improvements gradually vanish when the number of parameters per sample increases.
Evolutionary Retrofitting
Oct 15, 2024AfterLearnER (After Learning Evolutionary Retrofitting) consists in applying non-differentiable optimization, including evolutionary methods, to refine fully-trained machine learning models by optimizing a set of carefully chosen parameters or hyperparameters of the model, with respect to some actual, exact, and hence possibly non-differentiable error signal, performed on a subset of the standard validation set. The efficiency of AfterLearnER is demonstrated by tackling non-differentiable signals such as threshold-based criteria in depth sensing, the word error rate in speech re-synthesis, image quality in 3D generative adversarial networks (GANs), image generation via Latent Diffusion Models (LDM), the number of kills per life at Doom, computational accuracy or BLEU in code translation, and human appreciations in image synthesis. In some cases, this retrofitting is performed dynamically at inference time by taking into account user inputs. The advantages of AfterLearnER are its versatility (no gradient is needed), the possibility to use non-differentiable feedback including human evaluations, the limited overfitting, supported by a theoretical study and its anytime behavior. Last but not least, AfterLearnER requires only a minimal amount of feedback, i.e., a few dozens to a few hundreds of scalars, rather than the tens of thousands needed in most related published works. Compared to fine-tuning (typically using the same loss, and gradient-based optimization on a smaller but still big dataset at a fine grain), AfterLearnER uses a minimum amount of data on the real objective function without requiring differentiability.
Diverse Diffusion: Enhancing Image Diversity in Text-to-Image Generation
Oct 19, 2023Latent diffusion models excel at producing high-quality images from text. Yet, concerns appear about the lack of diversity in the generated imagery. To tackle this, we introduce Diverse Diffusion, a method for boosting image diversity beyond gender and ethnicity, spanning into richer realms, including color diversity.Diverse Diffusion is a general unsupervised technique that can be applied to existing text-to-image models. Our approach focuses on finding vectors in the Stable Diffusion latent space that are distant from each other. We generate multiple vectors in the latent space until we find a set of vectors that meets the desired distance requirements and the required batch size.To evaluate the effectiveness of our diversity methods, we conduct experiments examining various characteristics, including color diversity, LPIPS metric, and ethnicity/gender representation in images featuring humans.The results of our experiments emphasize the significance of diversity in generating realistic and varied images, offering valuable insights for improving text-to-image models. Through the enhancement of image diversity, our approach contributes to the creation of more inclusive and representative AI-generated art.
PrivacyGAN: robust generative image privacy
Oct 19, 2023Classical techniques for protecting facial image privacy typically fall into two categories: data-poisoning methods, exemplified by Fawkes, which introduce subtle perturbations to images, or anonymization methods that generate images resembling the original only in several characteristics, such as gender, ethnicity, or facial expression.In this study, we introduce a novel approach, PrivacyGAN, that uses the power of image generation techniques, such as VQGAN and StyleGAN, to safeguard privacy while maintaining image usability, particularly for social media applications. Drawing inspiration from Fawkes, our method entails shifting the original image within the embedding space towards a decoy image.We evaluate our approach using privacy metrics on traditional and novel facial image datasets. Additionally, we propose new criteria for evaluating the robustness of privacy-protection methods against unknown image recognition techniques, and we demonstrate that our approach is effective even in unknown embedding transfer scenarios. We also provide a human evaluation that further proves that the modified image preserves its utility as it remains recognisable as an image of the same person by friends and family.
Optimizing with Low Budgets: a Comparison on the Black-box Optimization Benchmarking Suite and OpenAI Gym
Oct 09, 2023The growing ubiquity of machine learning (ML) has led it to enter various areas of computer science, including black-box optimization (BBO). Recent research is particularly concerned with Bayesian optimization (BO). BO-based algorithms are popular in the ML community, as they are used for hyperparameter optimization and more generally for algorithm configuration. However, their efficiency decreases as the dimensionality of the problem and the budget of evaluations increase. Meanwhile, derivative-free optimization methods have evolved independently in the optimization community. Therefore, we urge to understand whether cross-fertilization is possible between the two communities, ML and BBO, i.e., whether algorithms that are heavily used in ML also work well in BBO and vice versa. Comparative experiments often involve rather small benchmarks and show visible problems in the experimental setup, such as poor initialization of baselines, overfitting due to problem-specific setting of hyperparameters, and low statistical significance. With this paper, we update and extend a comparative study presented by Hutter et al. in 2013. We compare BBO tools for ML with more classical heuristics, first on the well-known BBOB benchmark suite from the COCO environment and then on Direct Policy Search for OpenAI Gym, a reinforcement learning benchmark. Our results confirm that BO-based optimizers perform well on both benchmarks when budgets are limited, albeit with a higher computational cost, while they are often outperformed by algorithms from other families when the evaluation budget becomes larger. We also show that some algorithms from the BBO community perform surprisingly well on ML tasks.
Fairness in generative modeling
Oct 06, 2022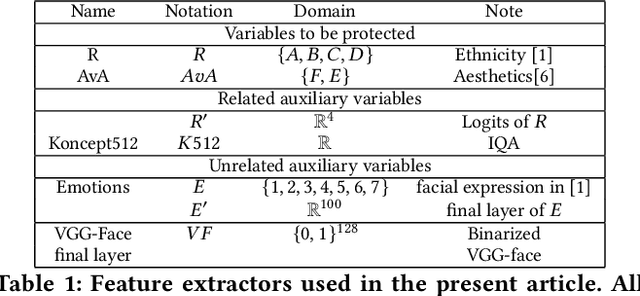
We design general-purpose algorithms for addressing fairness issues and mode collapse in generative modeling. More precisely, to design fair algorithms for as many sensitive variables as possible, including variables we might not be aware of, we assume no prior knowledge of sensitive variables: our algorithms use unsupervised fairness only, meaning no information related to the sensitive variables is used for our fairness-improving methods. All images of faces (even generated ones) have been removed to mitigate legal risks.
Improving Nevergrad's Algorithm Selection Wizard NGOpt through Automated Algorithm Configuration
Sep 09, 2022Algorithm selection wizards are effective and versatile tools that automatically select an optimization algorithm given high-level information about the problem and available computational resources, such as number and type of decision variables, maximal number of evaluations, possibility to parallelize evaluations, etc. State-of-the-art algorithm selection wizards are complex and difficult to improve. We propose in this work the use of automated configuration methods for improving their performance by finding better configurations of the algorithms that compose them. In particular, we use elitist iterated racing (irace) to find CMA configurations for specific artificial benchmarks that replace the hand-crafted CMA configurations currently used in the NGOpt wizard provided by the Nevergrad platform. We discuss in detail the setup of irace for the purpose of generating configurations that work well over the diverse set of problem instances within each benchmark. Our approach improves the performance of the NGOpt wizard, even on benchmark suites that were not part of the tuning by irace.