 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness in generative modeling
Oct 06, 2022
We design general-purpose algorithms for addressing fairness issues and mode collapse in generative modeling. More precisely, to design fair algorithms for as many sensitive variables as possible, including variables we might not be aware of, we assume no prior knowledge of sensitive variables: our algorithms use unsupervised fairness only, meaning no information related to the sensitive variables is used for our fairness-improving methods. All images of faces (even generated ones) have been removed to mitigate legal risks.
Improving Nevergrad's Algorithm Selection Wizard NGOpt through Automated Algorithm Configuration
Sep 09, 2022Algorithm selection wizards are effective and versatile tools that automatically select an optimization algorithm given high-level information about the problem and available computational resources, such as number and type of decision variables, maximal number of evaluations, possibility to parallelize evaluations, etc. State-of-the-art algorithm selection wizards are complex and difficult to improve. We propose in this work the use of automated configuration methods for improving their performance by finding better configurations of the algorithms that compose them. In particular, we use elitist iterated racing (irace) to find CMA configurations for specific artificial benchmarks that replace the hand-crafted CMA configurations currently used in the NGOpt wizard provided by the Nevergrad platform. We discuss in detail the setup of irace for the purpose of generating configurations that work well over the diverse set of problem instances within each benchmark. Our approach improves the performance of the NGOpt wizard, even on benchmark suites that were not part of the tuning by irace.
EvolGAN: Evolutionary Generative Adversarial Networks
Sep 28, 2020

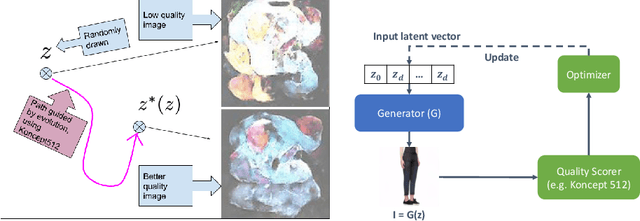
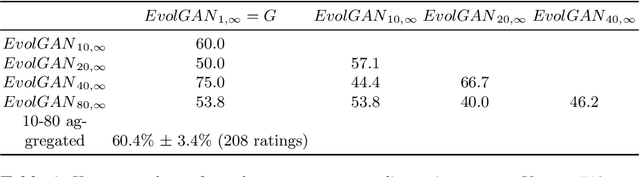
We propose to use a quality estimator and evolutionary methods to search the latent space of generative adversarial networks trained on small, difficult datasets, or both. The new method leads to the generation of significantly higher quality images while preserving the original generator's diversity. Human raters preferred an image from the new version with frequency 83.7pc for Cats, 74pc for FashionGen, 70.4pc for Horses, and 69.2pc for Artworks, and minor improvements for the already excellent GANs for faces. This approach applies to any quality scorer and GAN generator.
Versatile Black-Box Optimization
Apr 29, 2020

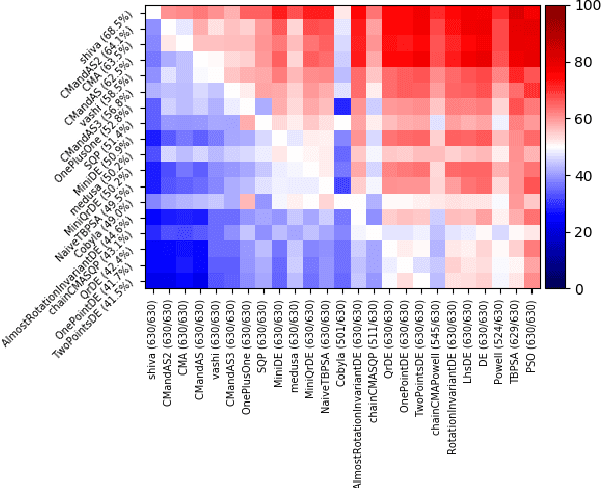

Choosing automatically the right algorithm using problem descriptors is a classical component of combinatorial optimization. It is also a good tool for making evolutionary algorithms fast, robust and versatile. We present Shiwa, an algorithm good at both discrete and continuous, noisy and noise-free, sequential and parallel, black-box optimization. Our algorithm is experimentally compared to competitors on YABBOB, a BBOB comparable testbed, and on some variants of it, and then validated on several real world testbeds.
Polygames: Improved Zero Learning
Jan 27, 2020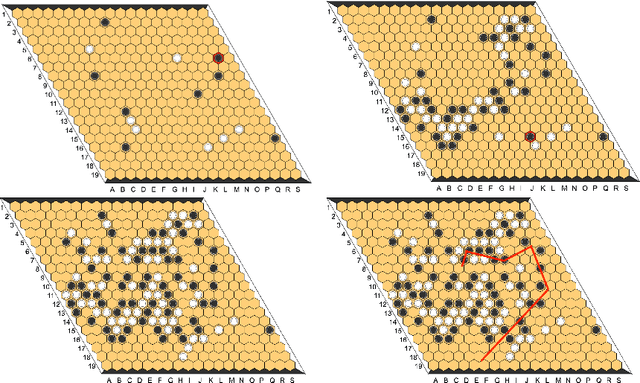
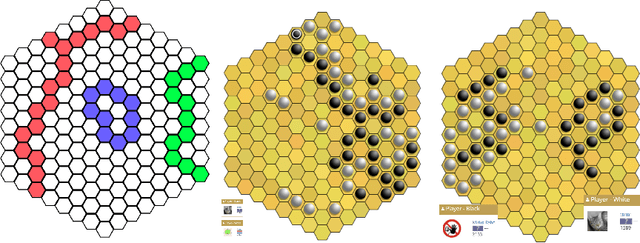
Since DeepMind's AlphaZero, Zero learning quickly became the state-of-the-art method for many board games. It can be improved using a fully convolutional structure (no fully connected layer). Using such an architecture plus global pooling, we can create bots independent of the board size. The training can be made more robust by keeping track of the best checkpoints during the training and by training against them. Using these features, we release Polygames, our framework for Zero learning, with its library of games and its checkpoints. We won against strong humans at the game of Hex in 19x19, which was often said to be untractable for zero learning; and in Havannah. We also won several first places at the TAAI competitions.
BCMA-ES: A Bayesian approach to CMA-ES
Apr 02, 2019

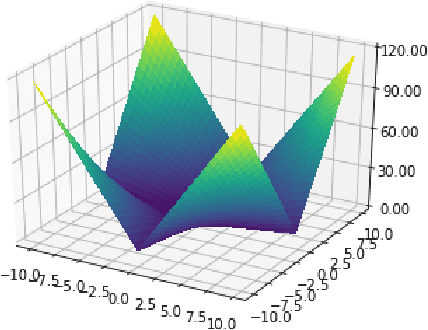
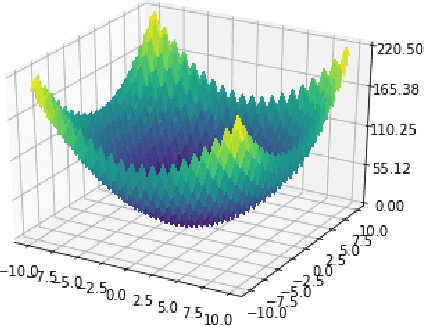
This paper introduces a novel theoretically sound approach for the celebrated CMA-ES algorithm. Assuming the parameters of the multi variate normal distribution for the minimum follow a conjugate prior distribution, we derive their optimal update at each iteration step. Not only provides this Bayesian framework a justification for the update of the CMA-ES algorithm but it also gives two new versions of CMA-ES either assuming normal-Wishart or normal-Inverse Wishart priors, depending whether we parametrize the likelihood by its covariance or precision matrix. We support our theoretical findings by numerical experiments that show fast convergence of these modified versions of CMA-ES.
Automatically Reinforcing a Game AI
Jul 27, 2016



A recent research trend in Artificial Intelligence (AI) is the combination of several programs into one single, stronger, program; this is termed portfolio methods. We here investigate the application of such methods to Game Playing Programs (GPPs). In addition, we consider the case in which only one GPP is available - by decomposing this single GPP into several ones through the use of parameters or even simply random seeds. These portfolio methods are trained in a learning phase. We propose two different offline approaches. The simplest one, BestArm, is a straightforward optimization of seeds or parame- ters; it performs quite well against the original GPP, but performs poorly against an opponent which repeats games and learns. The second one, namely Nash-portfolio, performs similarly in a "one game" test, and is much more robust against an opponent who learns. We also propose an online learning portfolio, which tests several of the GPP repeatedly and progressively switches to the best one - using a bandit algorithm.
Learning opening books in partially observable games: using random seeds in Phantom Go
Jul 08, 2016


Many artificial intelligences (AIs) are randomized. One can be lucky or unlucky with the random seed; we quantify this effect and show that, maybe contrarily to intuition, this is far from being negligible. Then, we apply two different existing algorithms for selecting good seeds and good probability distributions over seeds. This mainly leads to learning an opening book. We apply this to Phantom Go, which, as all phantom games, is hard for opening book learning. We improve the winning rate from 50% to 70% in 5x5 against the same AI, and from approximately 0% to 40% in 5x5, 7x7 and 9x9 against a stronger (learning) opponent.
A Critical Reassessment of Evolutionary Algorithms on the cryptanalysis of the simplified data encryption standard algorithm
Jul 08, 2014



In this paper we analyze the cryptanalysis of the simplified data encryption standard algorithm using meta-heuristics and in particular genetic algorithms. The classic fitness function when using such an algorithm is to compare n-gram statistics of a the decrypted message with those of the target message. We show that using such a function is irrelevant in case of Genetic Algorithm, simply because there is no correlation between the distance to the real key (the optimum) and the value of the fitness, in other words, there is no hidden gradient. In order to emphasize this assumption we experimentally show that a genetic algorithm perform worse than a random search on the cryptanalysis of the simplified data encryption standard algorithm.