 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Nevergrad's Algorithm Selection Wizard NGOpt through Automated Algorithm Configuration
Sep 09, 2022Algorithm selection wizards are effective and versatile tools that automatically select an optimization algorithm given high-level information about the problem and available computational resources, such as number and type of decision variables, maximal number of evaluations, possibility to parallelize evaluations, etc. State-of-the-art algorithm selection wizards are complex and difficult to improve. We propose in this work the use of automated configuration methods for improving their performance by finding better configurations of the algorithms that compose them. In particular, we use elitist iterated racing (irace) to find CMA configurations for specific artificial benchmarks that replace the hand-crafted CMA configurations currently used in the NGOpt wizard provided by the Nevergrad platform. We discuss in detail the setup of irace for the purpose of generating configurations that work well over the diverse set of problem instances within each benchmark. Our approach improves the performance of the NGOpt wizard, even on benchmark suites that were not part of the tuning by irace.
Explainable Landscape Analysis in Automated Algorithm Performance Prediction
Mar 22, 2022
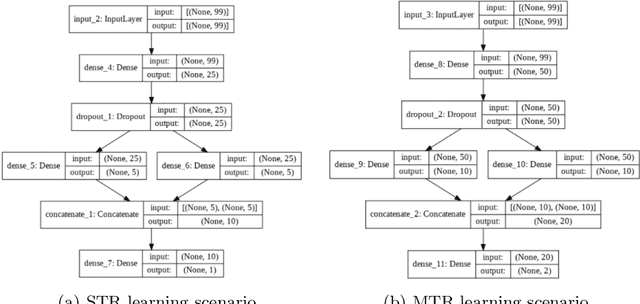

Predicting the performance of an optimization algorithm on a new problem instance is crucial in order to select the most appropriate algorithm for solving that problem instance. For this purpose, recent studies learn a supervised machine learning (ML) model using a set of problem landscape features linked to the performance achieved by the optimization algorithm. However, these models are black-box with the only goal of achieving good predictive performance, without providing explanations which landscape features contribute the most to the prediction of the performance achieved by the optimization algorithm. In this study, we investigate the expressiveness of problem landscape features utilized by different supervised ML models in automated algorithm performance prediction. The experimental results point out that the selection of the supervised ML method is crucial, since different supervised ML regression models utilize the problem landscape features differently and there is no common pattern with regard to which landscape features are the most informative.
Explainable Landscape-Aware Optimization Performance Prediction
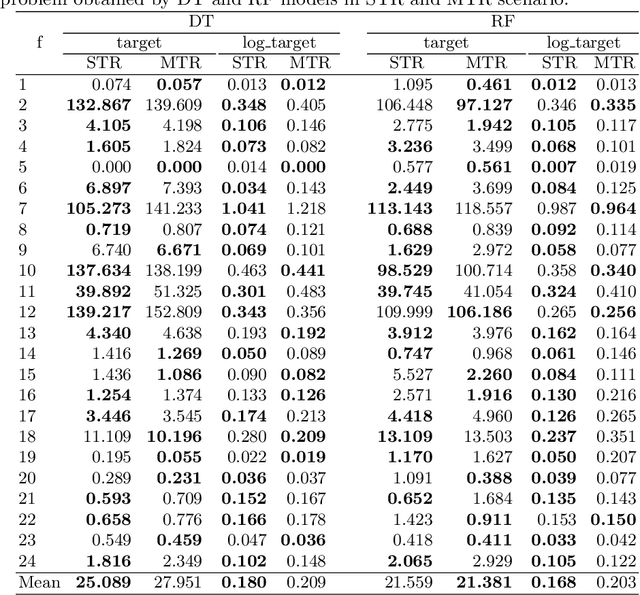
Oct 22, 2021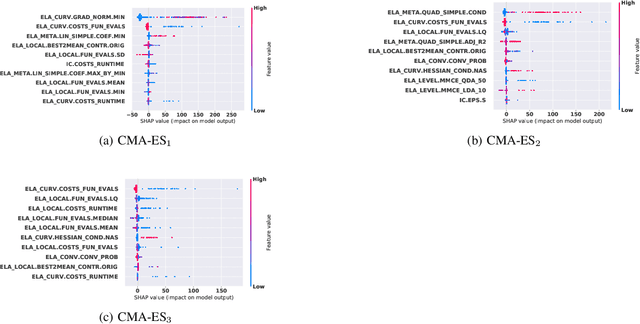
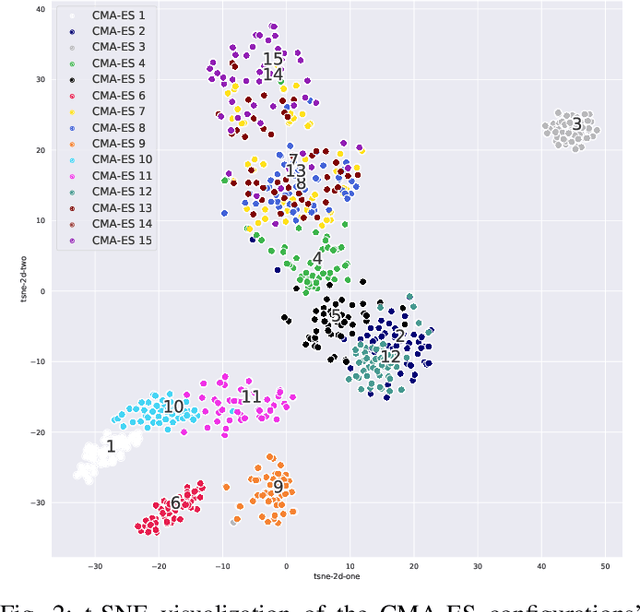
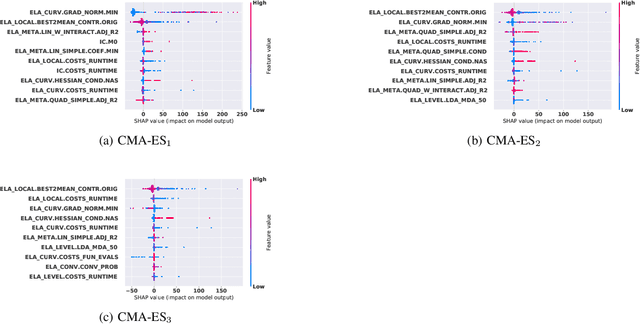

Efficient solving of an unseen optimization problem is related to appropriate selection of an optimization algorithm and its hyper-parameters. For this purpose, automated algorithm performance prediction should be performed that in most commonly-applied practices involves training a supervised ML algorithm using a set of problem landscape features. However, the main issue of training such models is their limited explainability since they only provide information about the joint impact of the set of landscape features to the end prediction results. In this study, we are investigating explainable landscape-aware regression models where the contribution of each landscape feature to the prediction of the optimization algorithm performance is estimated on a global and local level. The global level provides information about the impact of the feature across all benchmark problems' instances, while the local level provides information about the impact on a specific problem instance. The experimental results are obtained using the COCO benchmark problems and three differently configured modular CMA-ESs. The results show a proof of concept that different set of features are important for different problem instances, which indicates that further personalization of the landscape space is required when training an automated algorithm performance prediction model.