 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoly-EPO: Training Exploratory Reasoning Models
Apr 19, 2026Exploration is a cornerstone of learning from experience: it enables agents to find solutions to complex problems, generalize to novel ones, and scale performance with test-time compute. In this paper, we present a framework for post-training language models (LMs) that explicitly encourages optimistic exploration and promotes a synergy between exploration and exploitation. The central idea is to train the LM to generate sets of responses that are collectively accurate under the reward function and exploratory in their reasoning strategies. We first develop a general recipe for optimizing LMs with set reinforcement learning (set RL) under arbitrary objective functions, showing how standard RL algorithms can be adapted to this setting through a modification to the advantage computation. We then propose Polychromic Exploratory Policy Optimization (Poly-EPO), which instantiates this framework with an objective that explicitly synergizes exploration and exploitation. Across a range of reasoning benchmarks, we show that Poly-EPO improves generalization, as evidenced by higher pass@$k$ coverage, preserves greater diversity in model generations, and effectively scales with test-time compute.
Asking the Right Questions: Improving Reasoning with Generated Stepping Stones
Feb 22, 2026Recent years have witnessed tremendous progress in enabling LLMs to solve complex reasoning tasks such as math and coding. As we start to apply LLMs to harder tasks that they may not be able to solve in one shot, it is worth paying attention to their ability to construct intermediate stepping stones that prepare them to better solve the tasks. Examples of stepping stones include simplifications, alternative framings, or subproblems. We study properties and benefits of stepping stones in the context of modern reasoning LLMs via ARQ (\textbf{A}king the \textbf{R}ight \textbf{Q}uestions), our simple framework which introduces a question generator to the default reasoning pipeline. We first show that good stepping stone questions exist and are transferrable, meaning that good questions can be generated, and they substantially help LLMs of various capabilities in solving the target tasks. We next frame stepping stone generation as a post-training task and show that we can fine-tune LLMs to generate more useful stepping stones by SFT and RL on synthetic data.
Superhuman AI for Stratego Using Self-Play Reinforcement Learning and Test-Time Search
Nov 10, 2025Few classical games have been regarded as such significant benchmarks of artificial intelligence as to have justified training costs in the millions of dollars. Among these, Stratego -- a board wargame exemplifying the challenge of strategic decision making under massive amounts of hidden information -- stands apart as a case where such efforts failed to produce performance at the level of top humans. This work establishes a step change in both performance and cost for Stratego, showing that it is now possible not only to reach the level of top humans, but to achieve vastly superhuman level -- and that doing so requires not an industrial budget, but merely a few thousand dollars. We achieved this result by developing general approaches for self-play reinforcement learning and test-time search under imperfect information.
Diffusion Models are Secretly Exchangeable: Parallelizing DDPMs via Autospeculation
May 06, 2025Denoising Diffusion Probabilistic Models (DDPMs) have emerged as powerful tools for generative modeling. However, their sequential computation requirements lead to significant inference-time bottlenecks. In this work, we utilize the connection between DDPMs and Stochastic Localization to prove that, under an appropriate reparametrization, the increments of DDPM satisfy an exchangeability property. This general insight enables near-black-box adaptation of various performance optimization techniques from autoregressive models to the diffusion setting. To demonstrate this, we introduce \emph{Autospeculative Decoding} (ASD), an extension of the widely used speculative decoding algorithm to DDPMs that does not require any auxiliary draft models. Our theoretical analysis shows that ASD achieves a $\tilde{O} (K^{\frac{1}{3}})$ parallel runtime speedup over the $K$ step sequential DDPM. We also demonstrate that a practical implementation of autospeculative decoding accelerates DDPM inference significantly in various domains.
What's the Move? Hybrid Imitation Learning via Salient Points
Dec 06, 2024



While imitation learning (IL) offers a promising framework for teaching robots various behaviors, learning complex tasks remains challenging. Existing IL policies struggle to generalize effectively across visual and spatial variations even for simple tasks. In this work, we introduce SPHINX: Salient Point-based Hybrid ImitatioN and eXecution, a flexible IL policy that leverages multimodal observations (point clouds and wrist images), along with a hybrid action space of low-frequency, sparse waypoints and high-frequency, dense end effector movements. Given 3D point cloud observations, SPHINX learns to infer task-relevant points within a point cloud, or salient points, which support spatial generalization by focusing on semantically meaningful features. These salient points serve as anchor points to predict waypoints for long-range movement, such as reaching target poses in free-space. Once near a salient point, SPHINX learns to switch to predicting dense end-effector movements given close-up wrist images for precise phases of a task. By exploiting the strengths of different input modalities and action representations for different manipulation phases, SPHINX tackles complex tasks in a sample-efficient, generalizable manner. Our method achieves 86.7% success across 4 real-world and 2 simulated tasks, outperforming the next best state-of-the-art IL baseline by 41.1% on average across 440 real world trials. SPHINX additionally generalizes to novel viewpoints, visual distractors, spatial arrangements, and execution speeds with a 1.7x speedup over the most competitive baseline. Our website (http://sphinx-manip.github.io) provides open-sourced code for data collection, training, and evaluation, along with supplementary videos.
Imitation Bootstrapped Reinforcement Learning
Nov 20, 2023



Despite the considerable potential of reinforcement learning (RL), robotics control tasks predominantly rely on imitation learning (IL) owing to its better sample efficiency. However, given the high cost of collecting extensive demonstrations, RL is still appealing if it can utilize limited imitation data for efficient autonomous self-improvement. Existing RL methods that utilize demonstrations either initialize the replay buffer with demonstrations and oversample them during RL training, which does not benefit from the generalization potential of modern IL methods, or pretrain the RL policy with IL on the demonstrations, which requires additional mechanisms to prevent catastrophic forgetting during RL fine-tuning. We propose imitation bootstrapped reinforcement learning (IBRL), a novel framework that first trains an IL policy on a limited number of demonstrations and then uses it to propose alternative actions for both online exploration and target value bootstrapping. IBRL achieves SoTA performance and sample efficiency on 7 challenging sparse reward continuous control tasks in simulation while learning directly from pixels. As a highlight of our method, IBRL achieves $6.4\times$ higher success rate than RLPD, a strong method that combines the idea of oversampling demonstrations with modern RL improvements, under the budget of 10 demos and 100K interactions in the challenging PickPlaceCan task in the Robomimic benchmark.
Toward Grounded Social Reasoning
Jun 14, 2023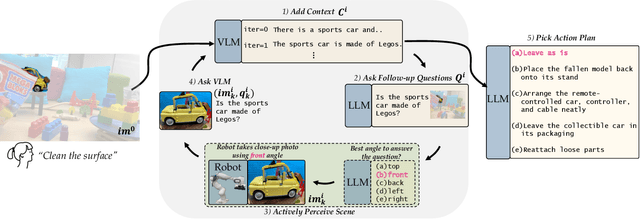
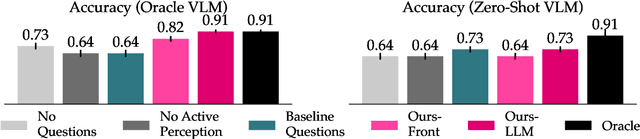

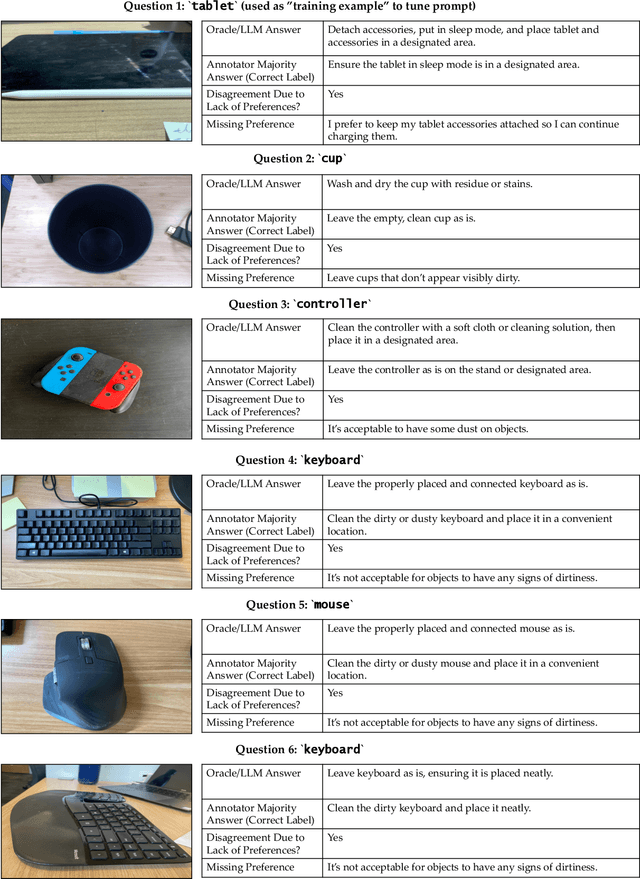
Consider a robot tasked with tidying a desk with a meticulously constructed Lego sports car. A human may recognize that it is not socially appropriate to disassemble the sports car and put it away as part of the "tidying". How can a robot reach that conclusion? Although large language models (LLMs) have recently been used to enable social reasoning, grounding this reasoning in the real world has been challenging. To reason in the real world, robots must go beyond passively querying LLMs and *actively gather information from the environment* that is required to make the right decision. For instance, after detecting that there is an occluded car, the robot may need to actively perceive the car to know whether it is an advanced model car made out of Legos or a toy car built by a toddler. We propose an approach that leverages an LLM and vision language model (VLM) to help a robot actively perceive its environment to perform grounded social reasoning. To evaluate our framework at scale, we release the MessySurfaces dataset which contains images of 70 real-world surfaces that need to be cleaned. We additionally illustrate our approach with a robot on 2 carefully designed surfaces. We find an average 12.9% improvement on the MessySurfaces benchmark and an average 15% improvement on the robot experiments over baselines that do not use active perception. The dataset, code, and videos of our approach can be found at https://minaek.github.io/groundedsocialreasoning.
The Update Equivalence Framework for Decision-Time Planning
Apr 25, 2023



The process of revising (or constructing) a policy immediately prior to execution -- known as decision-time planning -- is key to achieving superhuman performance in perfect-information settings like chess and Go. A recent line of work has extended decision-time planning to more general imperfect-information settings, leading to superhuman performance in poker. However, these methods requires considering subgames whose sizes grow quickly in the amount of non-public information, making them unhelpful when the amount of non-public information is large. Motivated by this issue, we introduce an alternative framework for decision-time planning that is not based on subgames but rather on the notion of update equivalence. In this framework, decision-time planning algorithms simulate updates of synchronous learning algorithms. This framework enables us to introduce a new family of principled decision-time planning algorithms that do not rely on public information, opening the door to sound and effective decision-time planning in settings with large amounts of non-public information. In experiments, members of this family produce comparable or superior results compared to state-of-the-art approaches in Hanabi and improve performance in 3x3 Abrupt Dark Hex and Phantom Tic-Tac-Toe.
Language Instructed Reinforcement Learning for Human-AI Coordination
Apr 13, 2023

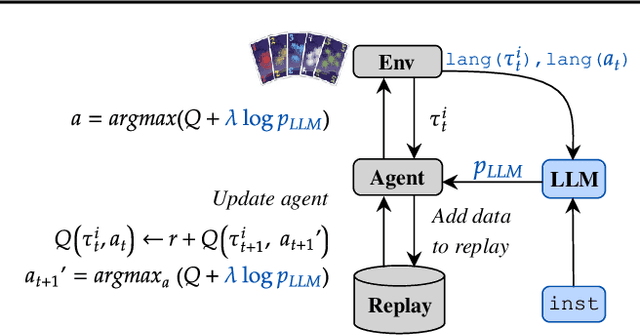

One of the fundamental quests of AI is to produce agents that coordinate well with humans. This problem is challenging, especially in domains that lack high quality human behavioral data, because multi-agent reinforcement learning (RL) often converges to different equilibria from the ones that humans prefer. We propose a novel framework, instructRL, that enables humans to specify what kind of strategies they expect from their AI partners through natural language instructions. We use pretrained large language models to generate a prior policy conditioned on the human instruction and use the prior to regularize the RL objective. This leads to the RL agent converging to equilibria that are aligned with human preferences. We show that instructRL converges to human-like policies that satisfy the given instructions in a proof-of-concept environment as well as the challenging Hanabi benchmark. Finally, we show that knowing the language instruction significantly boosts human-AI coordination performance in human evaluations in Hanabi.
Human-AI Coordination via Human-Regularized Search and Learning
Oct 11, 2022
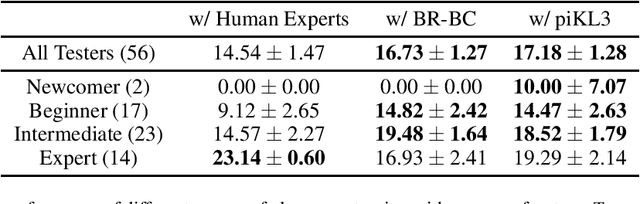
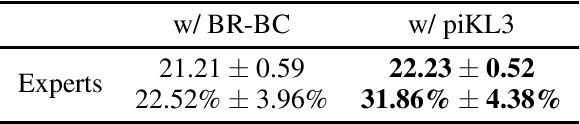
We consider the problem of making AI agents that collaborate well with humans in partially observable fully cooperative environments given datasets of human behavior. Inspired by piKL, a human-data-regularized search method that improves upon a behavioral cloning policy without diverging far away from it, we develop a three-step algorithm that achieve strong performance in coordinating with real humans in the Hanabi benchmark. We first use a regularized search algorithm and behavioral cloning to produce a better human model that captures diverse skill levels. Then, we integrate the policy regularization idea into reinforcement learning to train a human-like best response to the human model. Finally, we apply regularized search on top of the best response policy at test time to handle out-of-distribution challenges when playing with humans. We evaluate our method in two large scale experiments with humans. First, we show that our method outperforms experts when playing with a group of diverse human players in ad-hoc teams. Second, we show that our method beats a vanilla best response to behavioral cloning baseline by having experts play repeatedly with the two agents.