 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrospective X Training: Feedback Conditioning Improves Scaling Across all LLM Training Stages
May 19, 2026We tackle the question of how to scale more efficiently across the many, ever-growing stages of current LLM training pipelines. Our guiding intuition stems from the fact that the dynamics of later stages of the pipeline, e.g. post-training, can be used to inform earlier stages such as pre-training. To this end, we propose Introspective Training (or IXT), inspired by offline reward-conditioned reinforcement learning and applicable to any stage of training. IXT uses a thinking reward model to annotate data with natural language critique based feedback, enabling quality aware training from the earliest stages of the pipeline. Models are then trained by prefix-conditioning the data with the generated feedback -- ensuring that not all tokens are treated equally starting much earlier in training than usual. Comprehensive experiments on 7.5-12B transformer-based dense LLMs trained from scratch all the way up to 18 Trillion tokens seen show that our method: bends scaling curves resulting in up to 2.8x more compute efficiency generally; and reaches performance levels unachievable for models trained otherwise in domains such as math and code.
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
Golden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text
Jan 30, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a cornerstone for unlocking complex reasoning in Large Language Models (LLMs). Yet, scaling up RL is bottlenecked by limited existing verifiable data, where improvements increasingly saturate over prolonged training. To overcome this, we propose Golden Goose, a simple trick to synthesize unlimited RLVR tasks from unverifiable internet text by constructing a multiple-choice question-answering version of the fill-in-the-middle task. Given a source text, we prompt an LLM to identify and mask key reasoning steps, then generate a set of diverse, plausible distractors. This enables us to leverage reasoning-rich unverifiable corpora typically excluded from prior RLVR data construction (e.g., science textbooks) to synthesize GooseReason-0.7M, a large-scale RLVR dataset with over 0.7 million tasks spanning mathematics, programming, and general scientific domains. Empirically, GooseReason effectively revives models saturated on existing RLVR data, yielding robust, sustained gains under continuous RL and achieving new state-of-the-art results for 1.5B and 4B-Instruct models across 15 diverse benchmarks. Finally, we deploy Golden Goose in a real-world setting, synthesizing RLVR tasks from raw FineWeb scrapes for the cybersecurity domain, where no prior RLVR data exists. Training Qwen3-4B-Instruct on the resulting data GooseReason-Cyber sets a new state-of-the-art in cybersecurity, surpassing a 7B domain-specialized model with extensive domain-specific pre-training and post-training. This highlights the potential of automatically scaling up RLVR data by exploiting abundant, reasoning-rich, unverifiable internet text.
Critique-out-Loud Reward Models
Aug 21, 2024Traditionally, reward models used for reinforcement learning from human feedback (RLHF) are trained to directly predict preference scores without leveraging the generation capabilities of the underlying large language model (LLM). This limits the capabilities of reward models as they must reason implicitly about the quality of a response, i.e., preference modeling must be performed in a single forward pass through the model. To enable reward models to reason explicitly about the quality of a response, we introduce Critique-out-Loud (CLoud) reward models. CLoud reward models operate by first generating a natural language critique of the assistant's response that is then used to predict a scalar reward for the quality of the response. We demonstrate the success of CLoud reward models for both Llama-3-8B and 70B base models: compared to classic reward models CLoud reward models improve pairwise preference classification accuracy on RewardBench by 4.65 and 5.84 percentage points for the 8B and 70B base models respectively. Furthermore, CLoud reward models lead to a Pareto improvement for win rate on ArenaHard when used as the scoring model for Best-of-N. Finally, we explore how to exploit the dynamic inference compute capabilities of CLoud reward models by performing self-consistency decoding for reward prediction.
K-level Reasoning for Zero-Shot Coordination in Hanabi
Jul 14, 2022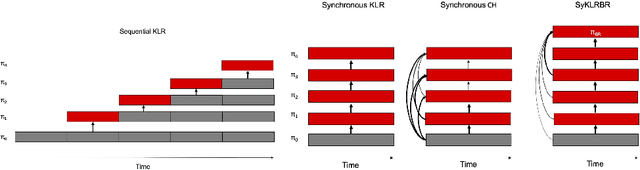
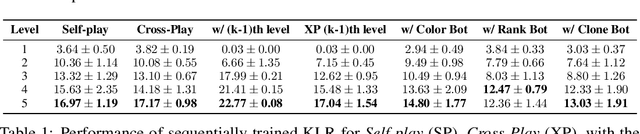

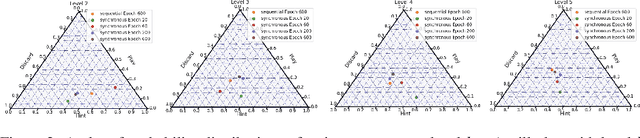
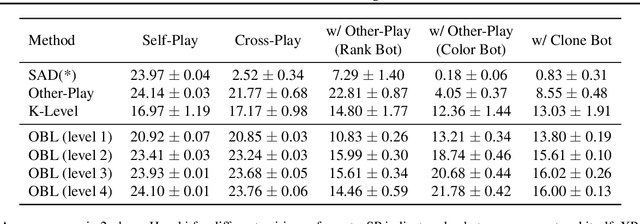
The standard problem setting in cooperative multi-agent settings is self-play (SP), where the goal is to train a team of agents that works well together. However, optimal SP policies commonly contain arbitrary conventions ("handshakes") and are not compatible with other, independently trained agents or humans. This latter desiderata was recently formalized by Hu et al. 2020 as the zero-shot coordination (ZSC) setting and partially addressed with their Other-Play (OP) algorithm, which showed improved ZSC and human-AI performance in the card game Hanabi. OP assumes access to the symmetries of the environment and prevents agents from breaking these in a mutually incompatible way during training. However, as the authors point out, discovering symmetries for a given environment is a computationally hard problem. Instead, we show that through a simple adaption of k-level reasoning (KLR) Costa Gomes et al. 2006, synchronously training all levels, we can obtain competitive ZSC and ad-hoc teamplay performance in Hanabi, including when paired with a human-like proxy bot. We also introduce a new method, synchronous-k-level reasoning with a best response (SyKLRBR), which further improves performance on our synchronous KLR by co-training a best response.
* Neurips 2021. 15 pages. 2 figures
CompilerGym: Robust, Performant Compiler Optimization Environments for AI Research
Sep 17, 2021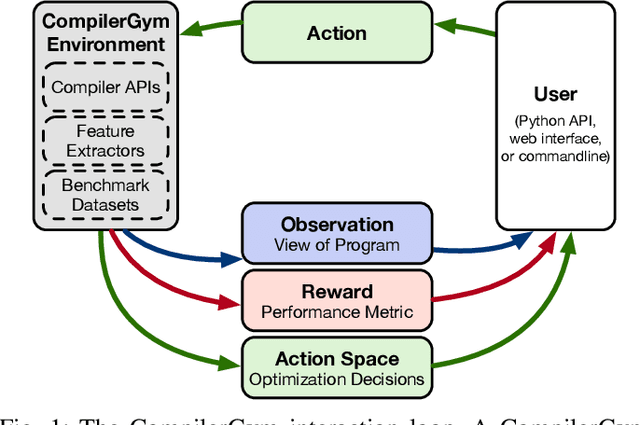
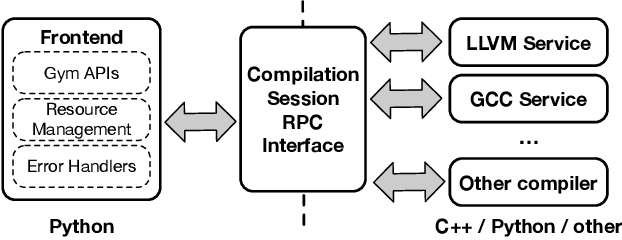
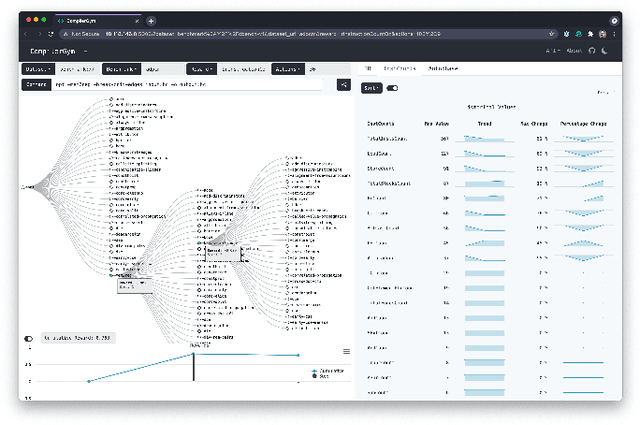
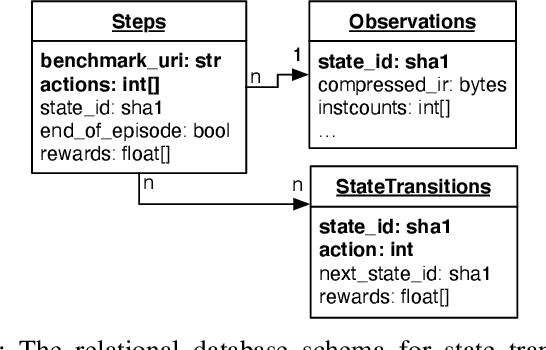
Interest in applying Artificial Intelligence (AI) techniques to compiler optimizations is increasing rapidly, but compiler research has a high entry barrier. Unlike in other domains, compiler and AI researchers do not have access to the datasets and frameworks that enable fast iteration and development of ideas, and getting started requires a significant engineering investment. What is needed is an easy, reusable experimental infrastructure for real world compiler optimization tasks that can serve as a common benchmark for comparing techniques, and as a platform to accelerate progress in the field. We introduce CompilerGym, a set of environments for real world compiler optimization tasks, and a toolkit for exposing new optimization tasks to compiler researchers. CompilerGym enables anyone to experiment on production compiler optimization problems through an easy-to-use package, regardless of their experience with compilers. We build upon the popular OpenAI Gym interface enabling researchers to interact with compilers using Python and a familiar API. We describe the CompilerGym architecture and implementation, characterize the optimization spaces and computational efficiencies of three included compiler environments, and provide extensive empirical evaluations. Compared to prior works, CompilerGym offers larger datasets and optimization spaces, is 27x more computationally efficient, is fault-tolerant, and capable of detecting reproducibility bugs in the underlying compilers. In making it easy for anyone to experiment with compilers - irrespective of their background - we aim to accelerate progress in the AI and compiler research domains.
Learning Space Partitions for Path Planning
Jul 14, 2021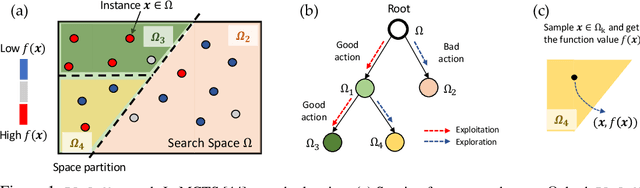

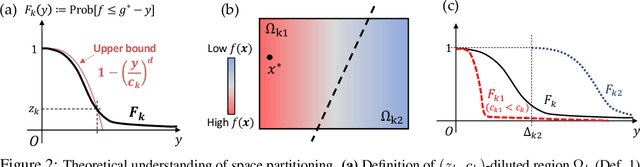
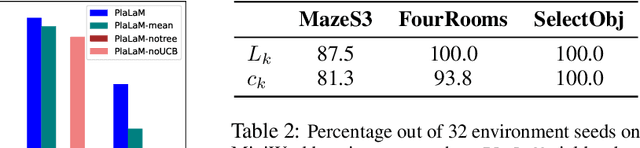
Path planning, the problem of efficiently discovering high-reward trajectories, often requires optimizing a high-dimensional and multimodal reward function. Popular approaches like CEM and CMA-ES greedily focus on promising regions of the search space and may get trapped in local maxima. DOO and VOOT balance exploration and exploitation, but use space partitioning strategies independent of the reward function to be optimized. Recently, LaMCTS empirically learns to partition the search space in a reward-sensitive manner for black-box optimization. In this paper, we develop a novel formal regret analysis for when and why such an adaptive region partitioning scheme works. We also propose a new path planning method PlaLaM which improves the function value estimation within each sub-region, and uses a latent representation of the search space. Empirically, PlaLaM outperforms existing path planning methods in 2D navigation tasks, especially in the presence of difficult-to-escape local optima, and shows benefits when plugged into model-based RL with planning components such as PETS. These gains transfer to highly multimodal real-world tasks, where we outperform strong baselines in compiler phase ordering by up to 245% and in molecular design by up to 0.4 on properties on a 0-1 scale. Code is available at https://github.com/yangkevin2/plalam.
Off-Belief Learning
Mar 06, 2021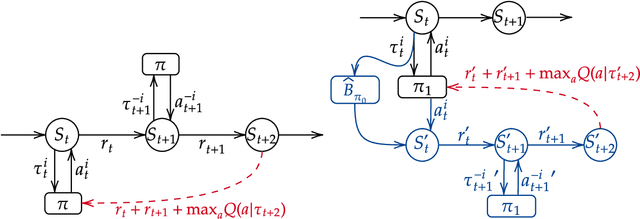
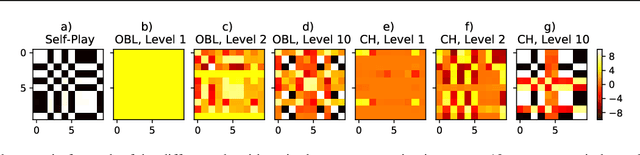

The standard problem setting in Dec-POMDPs is self-play, where the goal is to find a set of policies that play optimally together. Policies learned through self-play may adopt arbitrary conventions and rely on multi-step counterfactual reasoning based on assumptions about other agents' actions and thus fail when paired with humans or independently trained agents. In contrast, no current methods can learn optimal policies that are fully grounded, i.e., do not rely on counterfactual information from observing other agents' actions. To address this, we present off-belief learning} (OBL): at each time step OBL agents assume that all past actions were taken by a given, fixed policy ($\pi_0$), but that future actions will be taken by an optimal policy under these same assumptions. When $\pi_0$ is uniform random, OBL learns the optimal grounded policy. OBL can be iterated in a hierarchy, where the optimal policy from one level becomes the input to the next. This introduces counterfactual reasoning in a controlled manner. Unlike independent RL which may converge to any equilibrium policy, OBL converges to a unique policy, making it more suitable for zero-shot coordination. OBL can be scaled to high-dimensional settings with a fictitious transition mechanism and shows strong performance in both a simple toy-setting and the benchmark human-AI/zero-shot coordination problem Hanabi.
Variational Model-based Policy Optimization
Jun 24, 2020
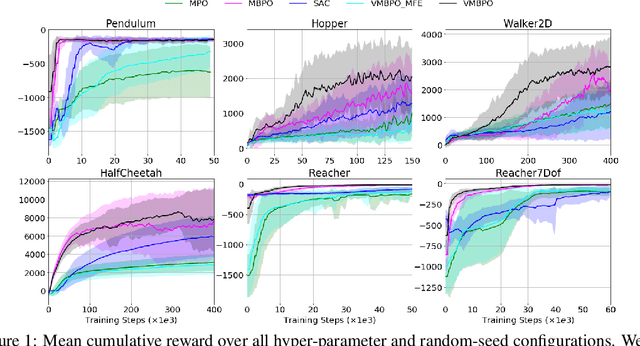
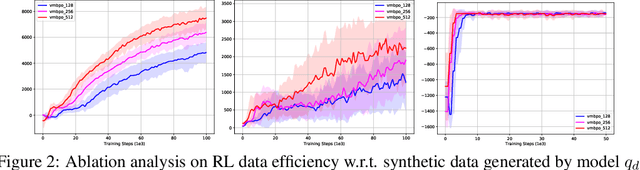
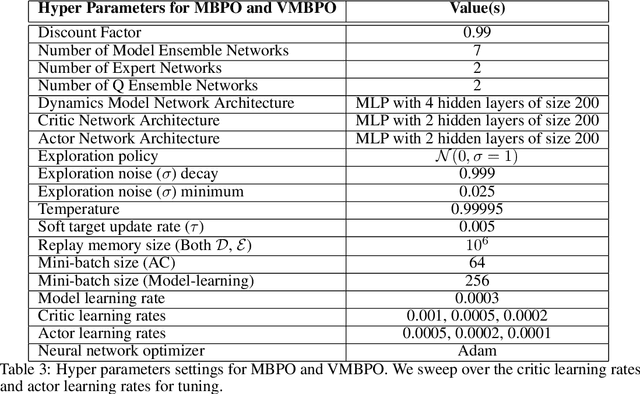
Model-based reinforcement learning (RL) algorithms allow us to combine model-generated data with those collected from interaction with the real system in order to alleviate the data efficiency problem in RL. However, designing such algorithms is often challenging because the bias in simulated data may overshadow the ease of data generation. A potential solution to this challenge is to jointly learn and improve model and policy using a universal objective function. In this paper, we leverage the connection between RL and probabilistic inference, and formulate such an objective function as a variational lower-bound of a log-likelihood. This allows us to use expectation maximization (EM) and iteratively fix a baseline policy and learn a variational distribution, consisting of a model and a policy (E-step), followed by improving the baseline policy given the learned variational distribution (M-step). We propose model-based and model-free policy iteration (actor-critic) style algorithms for the E-step and show how the variational distribution learned by them can be used to optimize the M-step in a fully model-based fashion. Our experiments on a number of continuous control tasks show that despite being more complex, our model-based (E-step) algorithm, called {\em variational model-based policy optimization} (VMBPO), is more sample-efficient and robust to hyper-parameter tuning than its model-free (E-step) counterpart. Using the same control tasks, we also compare VMBPO with several state-of-the-art model-based and model-free RL algorithms and show its sample efficiency and performance.
Control-Aware Representations for Model-based Reinforcement Learning
Jun 24, 2020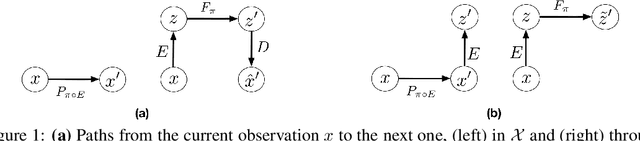


A major challenge in modern reinforcement learning (RL) is efficient control of dynamical systems from high-dimensional sensory observations. Learning controllable embedding (LCE) is a promising approach that addresses this challenge by embedding the observations into a lower-dimensional latent space, estimating the latent dynamics, and utilizing it to perform control in the latent space. Two important questions in this area are how to learn a representation that is amenable to the control problem at hand, and how to achieve an end-to-end framework for representation learning and control. In this paper, we take a few steps towards addressing these questions. We first formulate a LCE model to learn representations that are suitable to be used by a policy iteration style algorithm in the latent space. We call this model control-aware representation learning (CARL). We derive a loss function for CARL that has close connection to the prediction, consistency, and curvature (PCC) principle for representation learning. We derive three implementations of CARL. In the offline implementation, we replace the locally-linear control algorithm (e.g.,~iLQR) used by the existing LCE methods with a RL algorithm, namely model-based soft actor-critic, and show that it results in significant improvement. In online CARL, we interleave representation learning and control, and demonstrate further gain in performance. Finally, we propose value-guided CARL, a variation in which we optimize a weighted version of the CARL loss function, where the weights depend on the TD-error of the current policy. We evaluate the proposed algorithms by extensive experiments on benchmark tasks and compare them with several LCE baselines.