 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Belief Learning
Paper and Code
Mar 06, 2021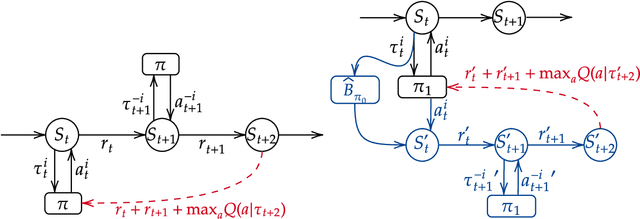
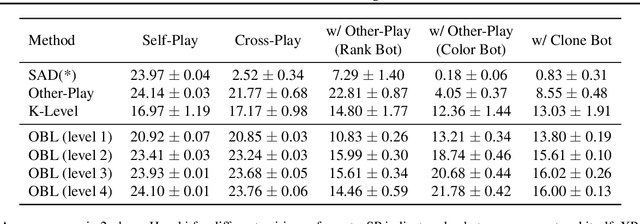
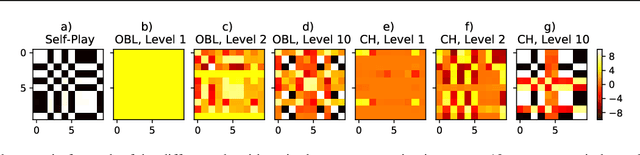

The standard problem setting in Dec-POMDPs is self-play, where the goal is to find a set of policies that play optimally together. Policies learned through self-play may adopt arbitrary conventions and rely on multi-step counterfactual reasoning based on assumptions about other agents' actions and thus fail when paired with humans or independently trained agents. In contrast, no current methods can learn optimal policies that are fully grounded, i.e., do not rely on counterfactual information from observing other agents' actions. To address this, we present off-belief learning} (OBL): at each time step OBL agents assume that all past actions were taken by a given, fixed policy ($\pi_0$), but that future actions will be taken by an optimal policy under these same assumptions. When $\pi_0$ is uniform random, OBL learns the optimal grounded policy. OBL can be iterated in a hierarchy, where the optimal policy from one level becomes the input to the next. This introduces counterfactual reasoning in a controlled manner. Unlike independent RL which may converge to any equilibrium policy, OBL converges to a unique policy, making it more suitable for zero-shot coordination. OBL can be scaled to high-dimensional settings with a fictitious transition mechanism and shows strong performance in both a simple toy-setting and the benchmark human-AI/zero-shot coordination problem Hanabi.