 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Efficient Speculative Decoding for Llama at Scale: Challenges and Solutions
Aug 11, 2025Speculative decoding is a standard method for accelerating the inference speed of large language models. However, scaling it for production environments poses several engineering challenges, including efficiently implementing different operations (e.g., tree attention and multi-round speculative decoding) on GPU. In this paper, we detail the training and inference optimization techniques that we have implemented to enable EAGLE-based speculative decoding at a production scale for Llama models. With these changes, we achieve a new state-of-the-art inference latency for Llama models. For example, Llama4 Maverick decodes at a speed of about 4 ms per token (with a batch size of one) on 8 NVIDIA H100 GPUs, which is 10% faster than the previously best known method. Furthermore, for EAGLE-based speculative decoding, our optimizations enable us to achieve a speed-up for large batch sizes between 1.4x and 2.0x at production scale.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding
Apr 29, 2024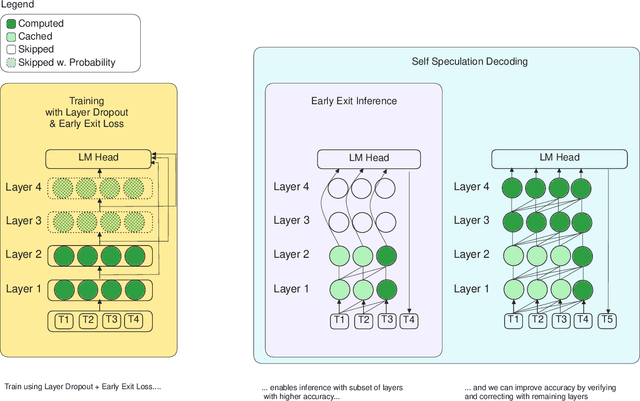
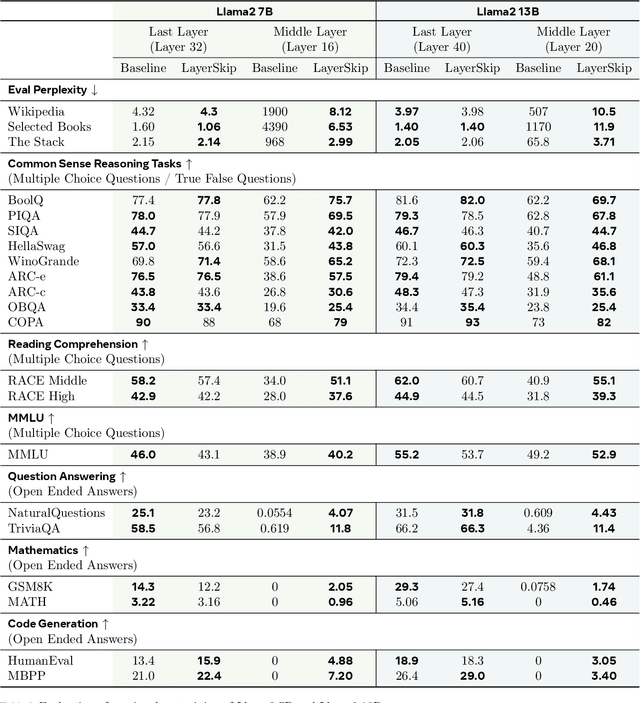
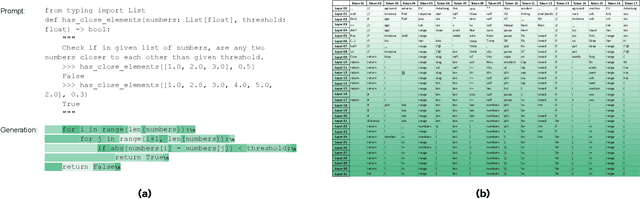
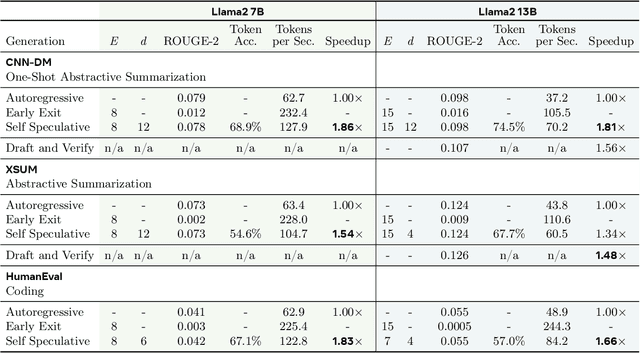
We present LayerSkip, an end-to-end solution to speed-up inference of large language models (LLMs). First, during training we apply layer dropout, with low dropout rates for earlier layers and higher dropout rates for later layers, and an early exit loss where all transformer layers share the same exit. Second, during inference, we show that this training recipe increases the accuracy of early exit at earlier layers, without adding any auxiliary layers or modules to the model. Third, we present a novel self-speculative decoding solution where we exit at early layers and verify and correct with remaining layers of the model. Our proposed self-speculative decoding approach has less memory footprint than other speculative decoding approaches and benefits from shared compute and activations of the draft and verification stages. We run experiments on different Llama model sizes on different types of training: pretraining from scratch, continual pretraining, finetuning on specific data domain, and finetuning on specific task. We implement our inference solution and show speedups of up to 2.16x on summarization for CNN/DM documents, 1.82x on coding, and 2.0x on TOPv2 semantic parsing task.
LoopTune: Optimizing Tensor Computations with Reinforcement Learning
Sep 08, 2023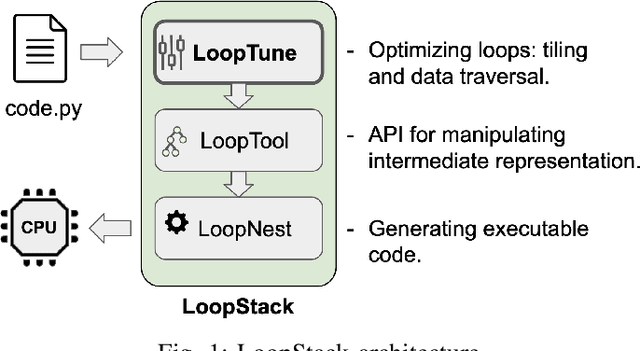
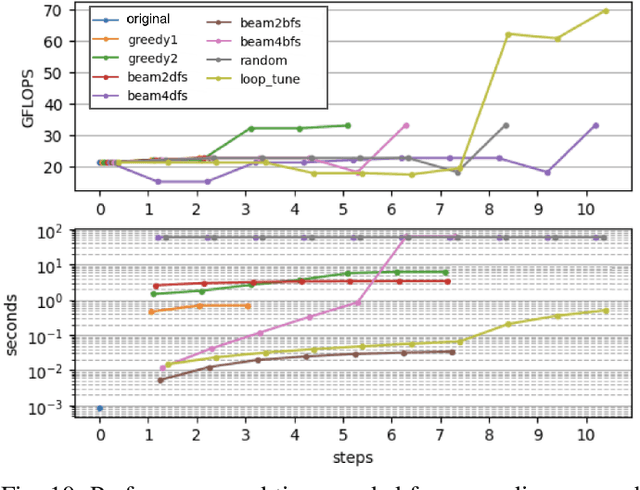
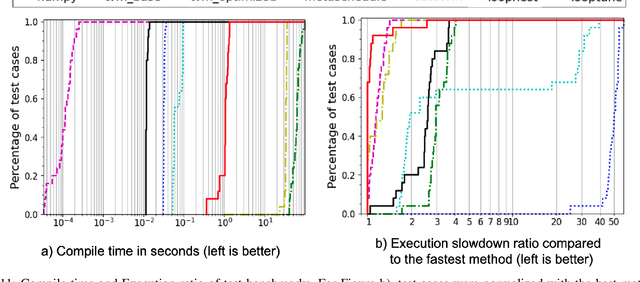
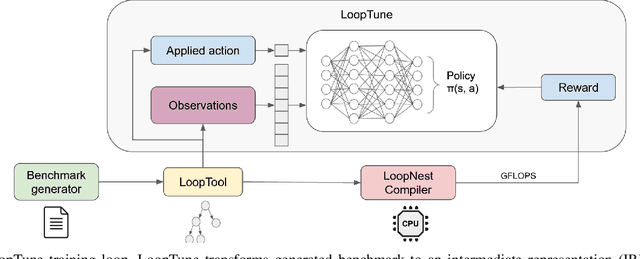
Advanced compiler technology is crucial for enabling machine learning applications to run on novel hardware, but traditional compilers fail to deliver performance, popular auto-tuners have long search times and expert-optimized libraries introduce unsustainable costs. To address this, we developed LoopTune, a deep reinforcement learning compiler that optimizes tensor computations in deep learning models for the CPU. LoopTune optimizes tensor traversal order while using the ultra-fast lightweight code generator LoopNest to perform hardware-specific optimizations. With a novel graph-based representation and action space, LoopTune speeds up LoopNest by 3.2x, generating an order of magnitude faster code than TVM, 2.8x faster than MetaSchedule, and 1.08x faster than AutoTVM, consistently performing at the level of the hand-tuned library Numpy. Moreover, LoopTune tunes code in order of seconds.
LoopStack: a Lightweight Tensor Algebra Compiler Stack
May 02, 2022

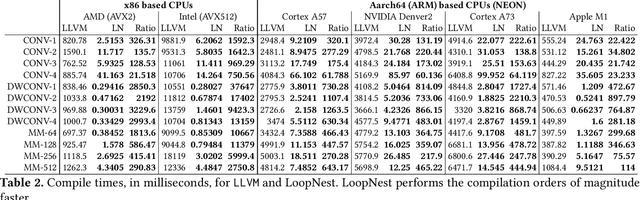
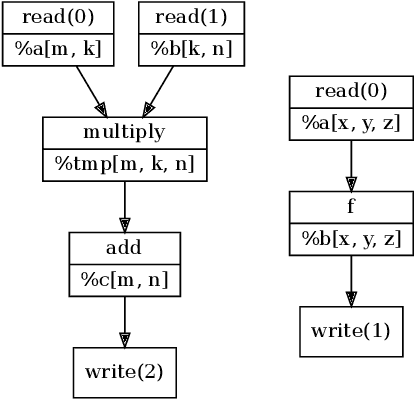
We present LoopStack, a domain specific compiler stack for tensor operations, composed of a frontend, LoopTool, and an efficient optimizing code generator, LoopNest. This stack enables us to compile entire neural networks and generate code targeting the AVX2, AVX512, NEON, and NEONfp16 instruction sets while incorporating optimizations often missing from other machine learning compiler backends. We evaluate our stack on a collection of full neural networks and commonly used network blocks as well as individual operators, and show that LoopStack generates machine code that matches and frequently exceeds the performance of in state-of-the-art machine learning frameworks in both cases. We also show that for a large collection of schedules LoopNest's compilation is orders of magnitude faster than LLVM, while resulting in equal or improved run time performance. Additionally, LoopStack has a very small memory footprint - a binary size of 245KB, and under 30K lines of effective code makes it ideal for use on mobile and embedded devices.
CompilerGym: Robust, Performant Compiler Optimization Environments for AI Research
Sep 17, 2021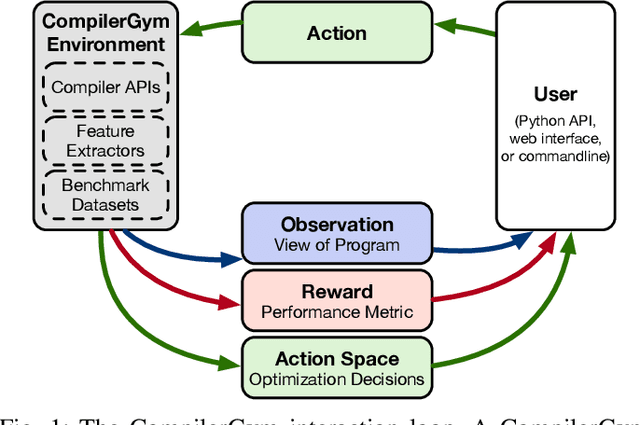
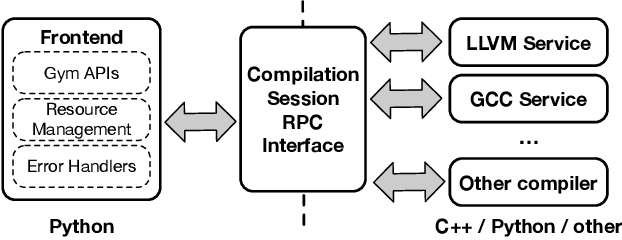
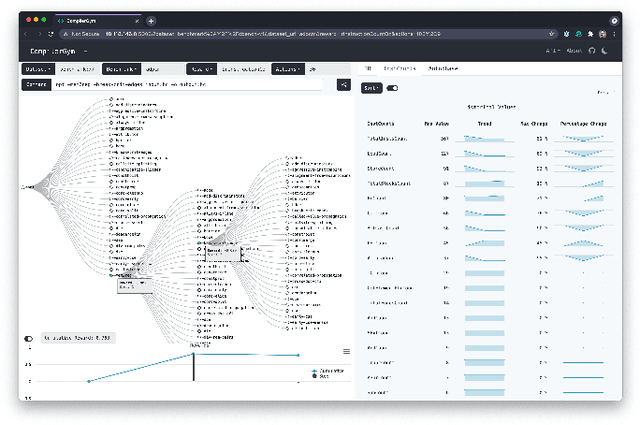
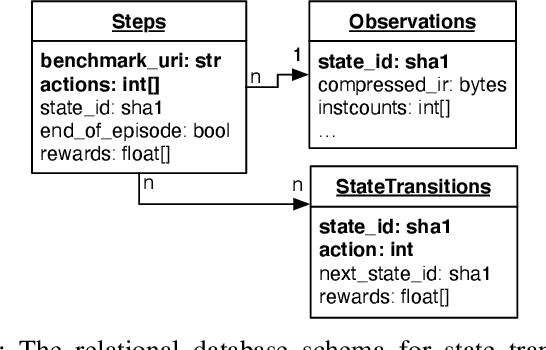
Interest in applying Artificial Intelligence (AI) techniques to compiler optimizations is increasing rapidly, but compiler research has a high entry barrier. Unlike in other domains, compiler and AI researchers do not have access to the datasets and frameworks that enable fast iteration and development of ideas, and getting started requires a significant engineering investment. What is needed is an easy, reusable experimental infrastructure for real world compiler optimization tasks that can serve as a common benchmark for comparing techniques, and as a platform to accelerate progress in the field. We introduce CompilerGym, a set of environments for real world compiler optimization tasks, and a toolkit for exposing new optimization tasks to compiler researchers. CompilerGym enables anyone to experiment on production compiler optimization problems through an easy-to-use package, regardless of their experience with compilers. We build upon the popular OpenAI Gym interface enabling researchers to interact with compilers using Python and a familiar API. We describe the CompilerGym architecture and implementation, characterize the optimization spaces and computational efficiencies of three included compiler environments, and provide extensive empirical evaluations. Compared to prior works, CompilerGym offers larger datasets and optimization spaces, is 27x more computationally efficient, is fault-tolerant, and capable of detecting reproducibility bugs in the underlying compilers. In making it easy for anyone to experiment with compilers - irrespective of their background - we aim to accelerate progress in the AI and compiler research domains.
Semisupervised Learning on Heterogeneous Graphs and its Applications to Facebook News Feed
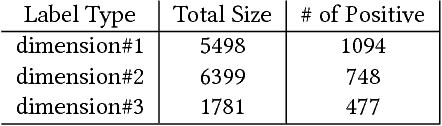
Jul 05, 2018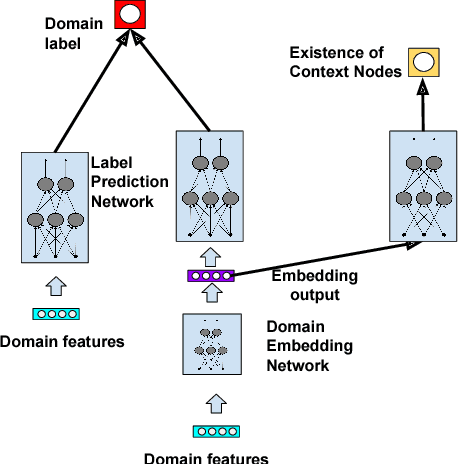
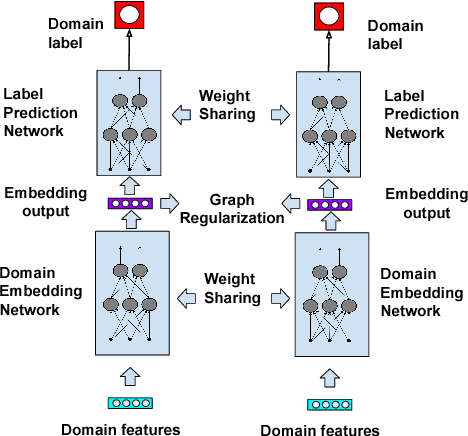
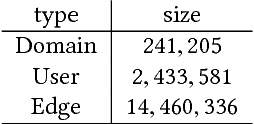
Graph-based semi-supervised learning is a fundamental machine learning problem, and has been well studied. Most studies focus on homogeneous networks (e.g. citation network, friend network). In the present paper, we propose the Heterogeneous Embedding Label Propagation (HELP) algorithm, a graph-based semi-supervised deep learning algorithm, for graphs that are characterized by heterogeneous node types. Empirically, we demonstrate the effectiveness of this method in domain classification tasks with Facebook user-domain interaction graph, and compare the performance of the proposed HELP algorithm with the state of the art algorithms. We show that the HELP algorithm improves the predictive performance across multiple tasks, together with semantically meaningful embedding that are discriminative for downstream classification or regression tasks.