 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubric-Guided Self-Distillation: Post-Training Without Rubric Verifiers
Jun 10, 2026Rubrics have emerged as an alternative to RLVR in open-ended domains where a single ground-truth final answer is not available. Existing rubric-based training methods rely on an LLM verifier that scores each rollout against rubrics. This introduces substantial training-time overhead, exposes optimization to verifier-specific biases, and reduces rubric feedback to a sparse end-of-trajectory signal. We propose Rubric-Guided Self-Distillation (RGSD), a verifier-free training method in which the base policy, conditioned on the rubric, serves as the teacher for the unconditioned student. RGSD distills the rubric-conditioned teacher distribution into the student token-by-token, replacing sparse trajectory-level rewards with dense per-token learning signals and removing the LLM judge from the training loop entirely. Across Qwen-2.5 (3B, 7B) and Qwen3-Thinking (4B, 8B) models on medical and science domains, RGSD achieves rubric satisfaction comparable to judge-based GRPO while using one on-policy rollout per prompt and no training-time verifier calls. Ablations show that raw rubrics provide a stronger teacher enrichment signal than self-generated reference responses, while a stronger GRPO judge can outperform RGSD in some settings, positioning RGSD as a complementary verifier-free alternative when verifier cost or reliability is the bottleneck.
Not Every Rubric Teaches Equally: Policy-Aware Rubric Rewards for RLVR
May 19, 2026Reinforcement learning with verifiable rewards has made post-training highly effective when correctness can be checked automatically. However, many important model behaviors require satisfying several qualitative criteria at once. Rubric-based rewards address this setting by grading prompt-specific criteria and aggregating them into a scalar reward. Yet standard static aggregations conflate a criterion's human-assigned importance with its current usefulness as an optimization signal. We show that this assumption breaks down in rubric RL: many important criteria are already saturated or currently unreachable, while criteria that distinguish rollouts are not necessarily those with the largest human weights. We introduce POW3R, a policy-aware rubric reward framework that preserves human weights and category balance as the rubric objective while adapting criterion-level reward weights during training. POW3R uses rollout-level contrast to emphasize criteria that currently separate the policy's outputs, making the GRPO reward more informative without changing the underlying evaluation target. Across three base policies on two datasets spanning multimodal and text-only settings, POW3R wins $24$ of $30$ base-policy/metric comparisons, improving both mean rubric reward and strict completion (the fraction of prompts whose response satisfies every required rubric criterion) over vanilla GRPO with rubric rewards, and reaches the same plateau in $2.5$--$4\times$ fewer training steps. Rubric rewards should therefore distinguish what should matter in the final answer from what can teach the current policy.
Reward Hacking in Rubric-Based Reinforcement Learning
May 12, 2026Reinforcement learning with verifiable rewards has enabled strong post-training gains in domains such as math and coding, though many open-ended settings rely on rubric-based rewards. We study reward hacking in rubric-based RL, where a policy is optimized against a training verifier but evaluated against a cross-family panel of three frontier judges, reducing dependence on any single evaluator. Our framework separates two sources of divergence: verifier failure, where the training verifier credits rubric criteria that reference verifiers reject, and rubric-design limitations, where even strong rubric-based verifiers favor responses that rubric-free judges rate worse overall. Across medical and science domains, weak verifiers produce large proxy-reward gains that do not transfer to the reference verifiers; exploitation grows over training and concentrates in recurring failures such as partial satisfaction of compound criteria, treating implicit content as explicit, and imprecise topical matching. Stronger verifiers substantially reduce, but do not eliminate, verifier exploitation. We also introduce a self-internalization gap, a verifier-free diagnostic based on policy log-probabilities, which tracks reference-verifier quality, detecting when the policy trained using the weak verifier stops improving. Finally, in our setting, stronger verification does not prevent reward hacking when the rubric leaves important failure modes unspecified: rubric-based verifiers prefer the RL checkpoint, while rubric-free judges prefer the base model. These disagreements coincide with gains concentrated in completeness and presence-based criteria, alongside declines in factual correctness, conciseness, relevance, and overall quality. Together, these results suggest that stronger verification reduces reward hacking, but does not by itself ensure that rubric gains correspond to broader quality gains.
CLIP Is Shortsighted: Paying Attention Beyond the First Sentence
Feb 25, 2026CLIP models learn transferable multi-modal features via image-text contrastive learning on internet-scale data. They are widely used in zero-shot classification, multi-modal retrieval, text-to-image diffusion, and as image encoders in large vision-language models. However, CLIP's pretraining is dominated by images paired with short captions, biasing the model toward encoding simple descriptions of salient objects and leading to coarse alignment on complex scenes and dense descriptions. While recent work mitigates this by fine-tuning on small-scale long-caption datasets, we identify an important common bias: both human- and LLM-generated long captions typically begin with a one-sentence summary followed by a detailed description. We show that this acts as a shortcut during training, concentrating attention on the opening sentence and early tokens and weakening alignment over the rest of the caption. To resolve this, we introduce DeBias-CLIP, which removes the summary sentence during training and applies sentence sub-sampling and text token padding to distribute supervision across all token positions. DeBias-CLIP achieves state-of-the-art long-text retrieval, improves short-text retrieval, and is less sensitive to sentence order permutations. It is a drop-in replacement for Long-CLIP with no additional trainable parameters.
Large Self-Supervised Models Bridge the Gap in Domain Adaptive Object Detection
Mar 29, 2025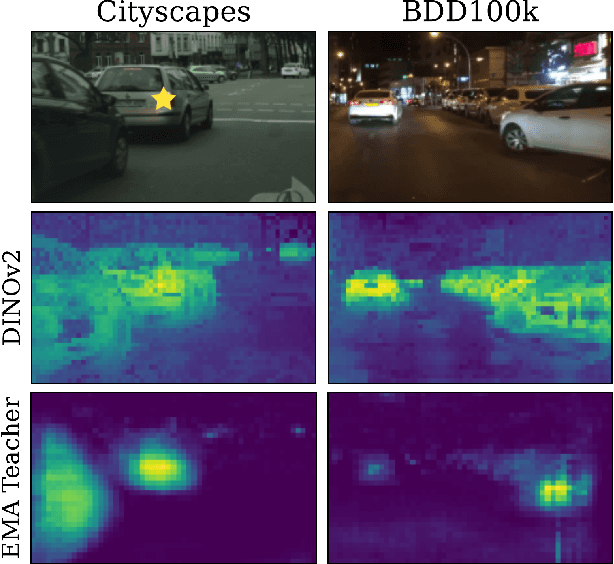
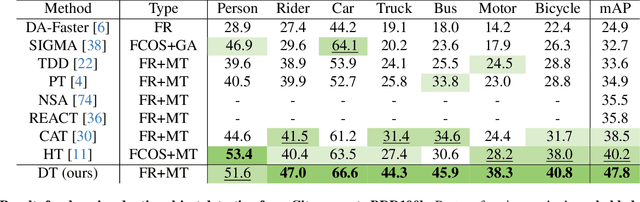
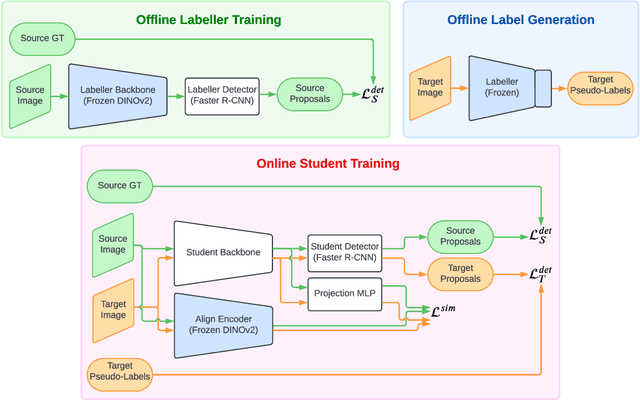

The current state-of-the-art methods in domain adaptive object detection (DAOD) use Mean Teacher self-labelling, where a teacher model, directly derived as an exponential moving average of the student model, is used to generate labels on the target domain which are then used to improve both models in a positive loop. This couples learning and generating labels on the target domain, and other recent works also leverage the generated labels to add additional domain alignment losses. We believe this coupling is brittle and excessively constrained: there is no guarantee that a student trained only on source data can generate accurate target domain labels and initiate the positive feedback loop, and much better target domain labels can likely be generated by using a large pretrained network that has been exposed to much more data. Vision foundational models are exactly such models, and they have shown impressive task generalization capabilities even when frozen. We want to leverage these models for DAOD and introduce DINO Teacher, which consists of two components. First, we train a new labeller on source data only using a large frozen DINOv2 backbone and show it generates more accurate labels than Mean Teacher. Next, we align the student's source and target image patch features with those from a DINO encoder, driving source and target representations closer to the generalizable DINO representation. We obtain state-of-the-art performance on multiple DAOD datasets. Code available at https://github.com/TRAILab/DINO_Teacher
Image-to-Lidar Relational Distillation for Autonomous Driving Data
Sep 01, 2024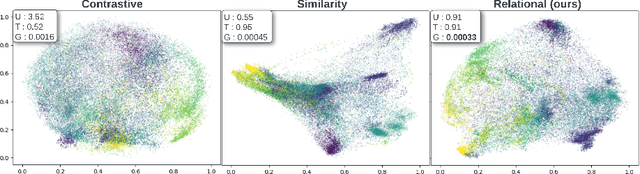

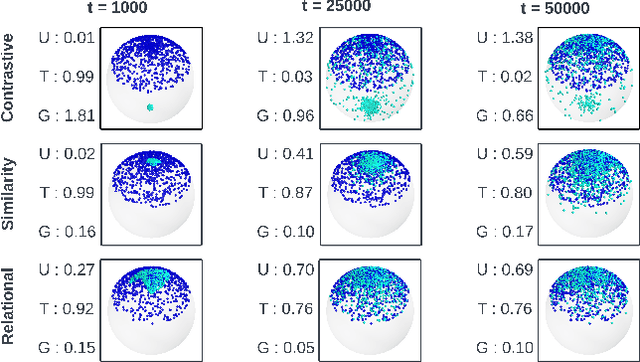
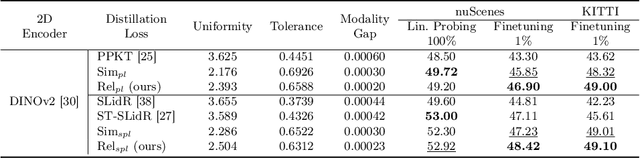
Pre-trained on extensive and diverse multi-modal datasets, 2D foundation models excel at addressing 2D tasks with little or no downstream supervision, owing to their robust representations. The emergence of 2D-to-3D distillation frameworks has extended these capabilities to 3D models. However, distilling 3D representations for autonomous driving datasets presents challenges like self-similarity, class imbalance, and point cloud sparsity, hindering the effectiveness of contrastive distillation, especially in zero-shot learning contexts. Whereas other methodologies, such as similarity-based distillation, enhance zero-shot performance, they tend to yield less discriminative representations, diminishing few-shot performance. We investigate the gap in structure between the 2D and the 3D representations that result from state-of-the-art distillation frameworks and reveal a significant mismatch between the two. Additionally, we demonstrate that the observed structural gap is negatively correlated with the efficacy of the distilled representations on zero-shot and few-shot 3D semantic segmentation. To bridge this gap, we propose a relational distillation framework enforcing intra-modal and cross-modal constraints, resulting in distilled 3D representations that closely capture the structure of the 2D representation. This alignment significantly enhances 3D representation performance over those learned through contrastive distillation in zero-shot segmentation tasks. Furthermore, our relational loss consistently improves the quality of 3D representations in both in-distribution and out-of-distribution few-shot segmentation tasks, outperforming approaches that rely on the similarity loss.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding
Apr 29, 2024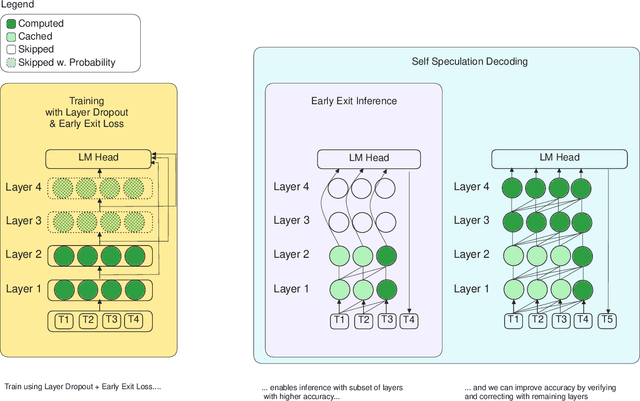
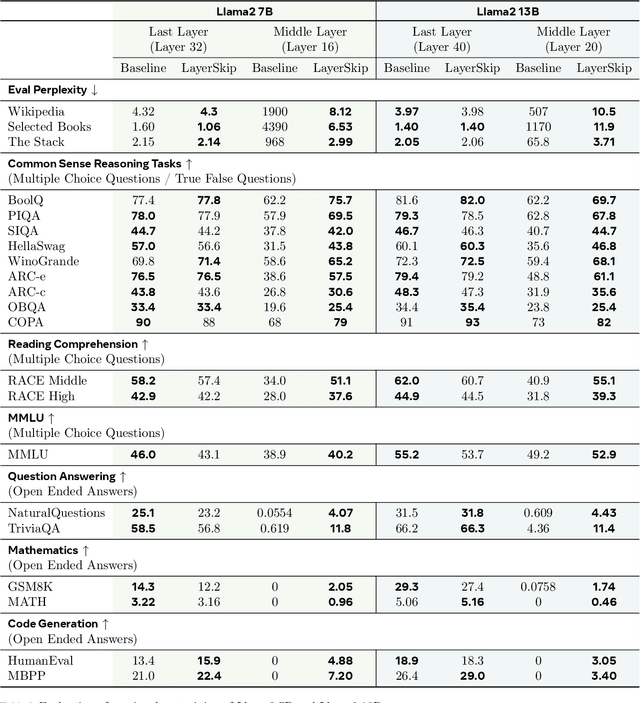
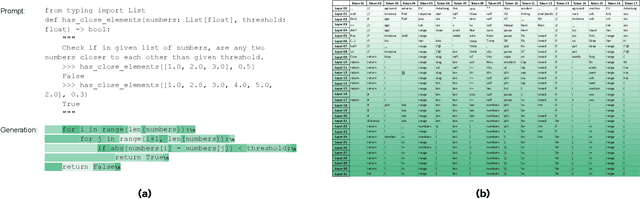
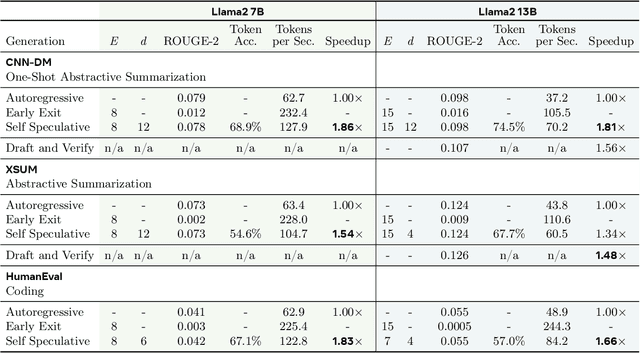
We present LayerSkip, an end-to-end solution to speed-up inference of large language models (LLMs). First, during training we apply layer dropout, with low dropout rates for earlier layers and higher dropout rates for later layers, and an early exit loss where all transformer layers share the same exit. Second, during inference, we show that this training recipe increases the accuracy of early exit at earlier layers, without adding any auxiliary layers or modules to the model. Third, we present a novel self-speculative decoding solution where we exit at early layers and verify and correct with remaining layers of the model. Our proposed self-speculative decoding approach has less memory footprint than other speculative decoding approaches and benefits from shared compute and activations of the draft and verification stages. We run experiments on different Llama model sizes on different types of training: pretraining from scratch, continual pretraining, finetuning on specific data domain, and finetuning on specific task. We implement our inference solution and show speedups of up to 2.16x on summarization for CNN/DM documents, 1.82x on coding, and 2.0x on TOPv2 semantic parsing task.
Decoding Data Quality via Synthetic Corruptions: Embedding-guided Pruning of Code Data
Dec 05, 2023Code datasets, often collected from diverse and uncontrolled sources such as GitHub, potentially suffer from quality issues, thereby affecting the performance and training efficiency of Large Language Models (LLMs) optimized for code generation. Previous studies demonstrated the benefit of using embedding spaces for data pruning, but they mainly focused on duplicate removal or increasing variety, and in other modalities, such as images. Our work focuses on using embeddings to identify and remove "low-quality" code data. First, we explore features of "low-quality" code in embedding space, through the use of synthetic corruptions. Armed with this knowledge, we devise novel pruning metrics that operate in embedding space to identify and remove low-quality entries in the Stack dataset. We demonstrate the benefits of this synthetic corruption informed pruning (SCIP) approach on the well-established HumanEval and MBPP benchmarks, outperforming existing embedding-based methods. Importantly, we achieve up to a 3% performance improvement over no pruning, thereby showing the promise of insights from synthetic corruptions for data pruning.
SIEVE: Multimodal Dataset Pruning Using Image Captioning Models
Oct 03, 2023
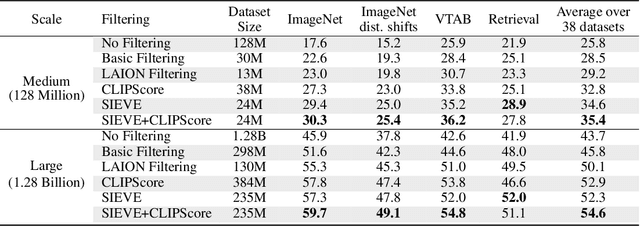
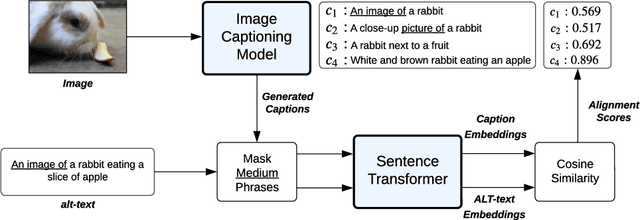
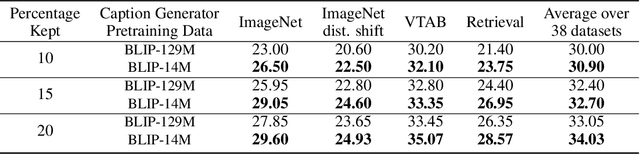
Vision-Language Models (VLMs) are pretrained on large, diverse, and noisy web-crawled datasets. This underscores the critical need for dataset pruning, as the quality of these datasets is strongly correlated with the performance of VLMs on downstream tasks. Using CLIPScore from a pretrained model to only train models using highly-aligned samples is one of the most successful methods for pruning.We argue that this approach suffers from multiple limitations including: 1) false positives due to spurious correlations captured by the pretrained CLIP model, 2) false negatives due to poor discrimination between hard and bad samples, and 3) biased ranking towards samples similar to the pretrained CLIP dataset. We propose a pruning method, SIEVE, that employs synthetic captions generated by image-captioning models pretrained on small, diverse, and well-aligned image-text pairs to evaluate the alignment of noisy image-text pairs. To bridge the gap between the limited diversity of generated captions and the high diversity of alternative text (alt-text), we estimate the semantic textual similarity in the embedding space of a language model pretrained on billions of sentences. Using DataComp, a multimodal dataset filtering benchmark, we achieve state-of-the-art performance on the large scale pool, and competitive results on the medium scale pool, surpassing CLIPScore-based filtering by 1.7% and 2.6% on average, on 38 downstream tasks.