 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatBench: Discriminative, Faithful, and Efficient VLM Evaluations
Jan 05, 2026Empirical evaluation serves as the primary compass guiding research progress in foundation models. Despite a large body of work focused on training frontier vision-language models (VLMs), approaches to their evaluation remain nascent. To guide their maturation, we propose three desiderata that evaluations should satisfy: (1) faithfulness to the modality and application, (2) discriminability between models of varying quality, and (3) efficiency in compute. Through this lens, we identify critical failure modes that violate faithfulness and discriminability, misrepresenting model capabilities: (i) multiple-choice formats reward guessing, poorly reflect downstream use cases, and saturate early as models improve; (ii) blindly solvable questions, which can be answered without images, constitute up to 70% of some evaluations; and (iii) mislabeled or ambiguous samples compromise up to 42% of examples in certain datasets. Regarding efficiency, the computational burden of evaluating frontier models has become prohibitive: by some accounts, nearly 20% of development compute is devoted to evaluation alone. Rather than discarding existing benchmarks, we curate them via transformation and filtering to maximize fidelity and discriminability. We find that converting multiple-choice questions to generative tasks reveals sharp capability drops of up to 35%. In addition, filtering blindly solvable and mislabeled samples improves discriminative power while simultaneously reducing computational cost. We release DatBench-Full, a cleaned evaluation suite of 33 datasets spanning nine VLM capabilities, and DatBench, a discriminative subset that achieves 13x average speedup (up to 50x) while closely matching the discriminative power of the original datasets. Our work outlines a path toward evaluation practices that are both rigorous and sustainable as VLMs continue to scale.
Luxical: High-Speed Lexical-Dense Text Embeddings
Dec 11, 2025Frontier language model quality increasingly hinges on our ability to organize web-scale text corpora for training. Today's dominant tools trade off speed and flexibility: lexical classifiers (e.g., FastText) are fast but limited to producing classification output scores, while the vector-valued outputs of transformer text embedding models flexibly support numerous workflows (e.g., clustering, classification, and retrieval) but are computationally expensive to produce. We introduce Luxical, a library for high-speed "lexical-dense" text embeddings that aims to recover the best properties of both approaches for web-scale text organization. Luxical combines sparse TF--IDF features, a small ReLU network, and a knowledge distillation training regimen to approximate large transformer embedding models at a fraction of their operational cost. In this technical report, we describe the Luxical architecture and training objective and evaluate a concrete Luxical model in two disparate applications: a targeted webcrawl document retrieval test and an end-to-end language model data curation task grounded in text classification. In these tasks we demonstrate speedups ranging from 3x to 100x over varying-sized neural baselines, and comparable to FastText model inference during the data curation task. On these evaluations, the tested Luxical model illustrates favorable compute/quality trade-offs for large-scale text organization, matching the quality of neural baselines. Luxical is available as open-source software at https://github.com/datologyai/luxical.
SIEVE: Multimodal Dataset Pruning Using Image Captioning Models
Oct 03, 2023
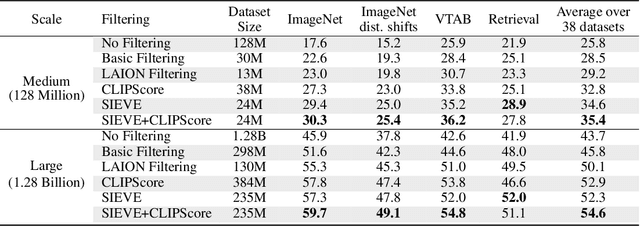
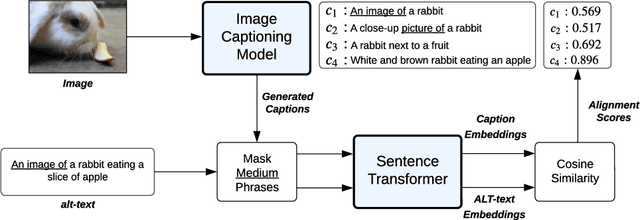
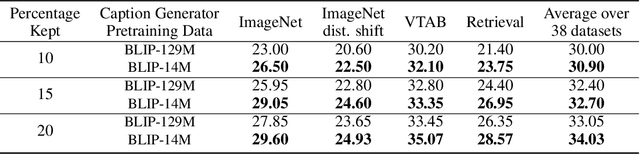
Vision-Language Models (VLMs) are pretrained on large, diverse, and noisy web-crawled datasets. This underscores the critical need for dataset pruning, as the quality of these datasets is strongly correlated with the performance of VLMs on downstream tasks. Using CLIPScore from a pretrained model to only train models using highly-aligned samples is one of the most successful methods for pruning.We argue that this approach suffers from multiple limitations including: 1) false positives due to spurious correlations captured by the pretrained CLIP model, 2) false negatives due to poor discrimination between hard and bad samples, and 3) biased ranking towards samples similar to the pretrained CLIP dataset. We propose a pruning method, SIEVE, that employs synthetic captions generated by image-captioning models pretrained on small, diverse, and well-aligned image-text pairs to evaluate the alignment of noisy image-text pairs. To bridge the gap between the limited diversity of generated captions and the high diversity of alternative text (alt-text), we estimate the semantic textual similarity in the embedding space of a language model pretrained on billions of sentences. Using DataComp, a multimodal dataset filtering benchmark, we achieve state-of-the-art performance on the large scale pool, and competitive results on the medium scale pool, surpassing CLIPScore-based filtering by 1.7% and 2.6% on average, on 38 downstream tasks.
Objectives Matter: Understanding the Impact of Self-Supervised Objectives on Vision Transformer Representations
Apr 25, 2023Joint-embedding based learning (e.g., SimCLR, MoCo, DINO) and reconstruction-based learning (e.g., BEiT, SimMIM, MAE) are the two leading paradigms for self-supervised learning of vision transformers, but they differ substantially in their transfer performance. Here, we aim to explain these differences by analyzing the impact of these objectives on the structure and transferability of the learned representations. Our analysis reveals that reconstruction-based learning features are significantly dissimilar to joint-embedding based learning features and that models trained with similar objectives learn similar features even across architectures. These differences arise early in the network and are primarily driven by attention and normalization layers. We find that joint-embedding features yield better linear probe transfer for classification because the different objectives drive different distributions of information and invariances in the learned representation. These differences explain opposite trends in transfer performance for downstream tasks that require spatial specificity in features. Finally, we address how fine-tuning changes reconstructive representations to enable better transfer, showing that fine-tuning re-organizes the information to be more similar to pre-trained joint embedding models.
Stable and low-precision training for large-scale vision-language models
Apr 25, 2023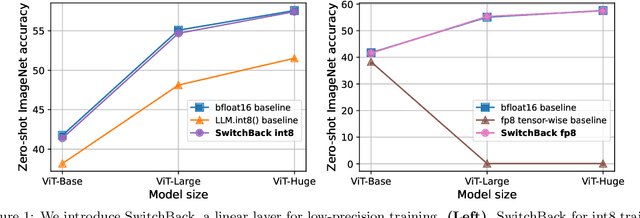
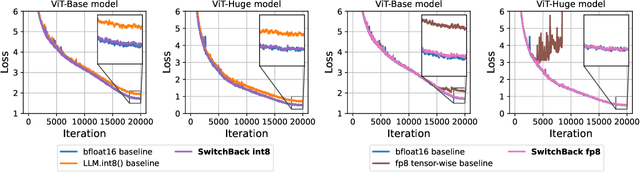
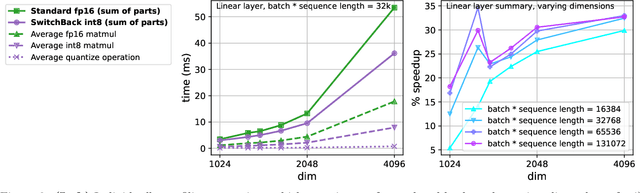
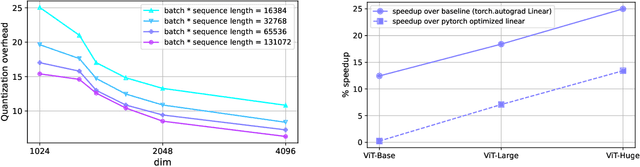
We introduce new methods for 1) accelerating and 2) stabilizing training for large language-vision models. 1) Towards accelerating training, we introduce SwitchBack, a linear layer for int8 quantized training which provides a speed-up of 13-25% while matching the performance of bfloat16 training within 0.1 percentage points for the 1B parameter CLIP ViT-Huge -- the largest int8 training to date. Our main focus is int8 as GPU support for float8 is rare, though we also analyze float8 training through simulation. While SwitchBack proves effective for float8, we show that standard techniques are also successful if the network is trained and initialized so that large feature magnitudes are discouraged, which we accomplish via layer-scale initialized with zeros. 2) Towards stable training, we analyze loss spikes and find they consistently occur 1-8 iterations after the squared gradients become under-estimated by their AdamW second moment estimator. As a result, we recommend an AdamW-Adafactor hybrid, which we refer to as StableAdamW because it avoids loss spikes when training a CLIP ViT-Huge model and outperforms gradient clipping.
A Cookbook of Self-Supervised Learning
Apr 24, 2023



Self-supervised learning, dubbed the dark matter of intelligence, is a promising path to advance machine learning. Yet, much like cooking, training SSL methods is a delicate art with a high barrier to entry. While many components are familiar, successfully training a SSL method involves a dizzying set of choices from the pretext tasks to training hyper-parameters. Our goal is to lower the barrier to entry into SSL research by laying the foundations and latest SSL recipes in the style of a cookbook. We hope to empower the curious researcher to navigate the terrain of methods, understand the role of the various knobs, and gain the know-how required to explore how delicious SSL can be.
Robust Self-Supervised Learning with Lie Groups
Oct 24, 2022Deep learning has led to remarkable advances in computer vision. Even so, today's best models are brittle when presented with variations that differ even slightly from those seen during training. Minor shifts in the pose, color, or illumination of an object can lead to catastrophic misclassifications. State-of-the art models struggle to understand how a set of variations can affect different objects. We propose a framework for instilling a notion of how objects vary in more realistic settings. Our approach applies the formalism of Lie groups to capture continuous transformations to improve models' robustness to distributional shifts. We apply our framework on top of state-of-the-art self-supervised learning (SSL) models, finding that explicitly modeling transformations with Lie groups leads to substantial performance gains of greater than 10% for MAE on both known instances seen in typical poses now presented in new poses, and on unknown instances in any pose. We also apply our approach to ImageNet, finding that the Lie operator improves performance by almost 4%. These results demonstrate the promise of learning transformations to improve model robustness.
The Robustness Limits of SoTA Vision Models to Natural Variation
Oct 24, 2022Recent state-of-the-art vision models introduced new architectures, learning paradigms, and larger pretraining data, leading to impressive performance on tasks such as classification. While previous generations of vision models were shown to lack robustness to factors such as pose, it's unclear the extent to which this next generation of models are more robust. To study this question, we develop a dataset of more than 7 million images with controlled changes in pose, position, background, lighting, and size. We study not only how robust recent state-of-the-art models are, but also the extent to which models can generalize variation in factors when they're present during training. We consider a catalog of recent vision models, including vision transformers (ViT), self-supervised models such as masked autoencoders (MAE), and models trained on larger datasets such as CLIP. We find out-of-the-box, even today's best models are not robust to common changes in pose, size, and background. When some samples varied during training, we found models required a significant portion of diversity to generalize -- though eventually robustness did improve. When diversity is only seen for some classes however, we found models did not generalize to other classes, unless the classes were very similar to those seen varying during training. We hope our work will shed further light on the blind spots of SoTA models and spur the development of more robust vision models.
Trade-offs of Local SGD at Scale: An Empirical Study
Oct 15, 2021
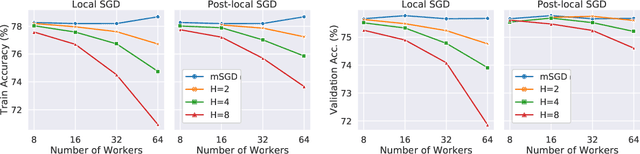
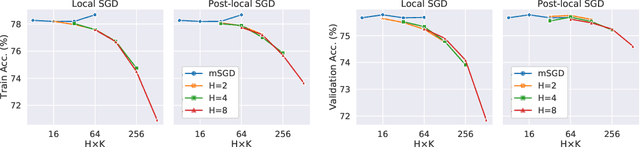
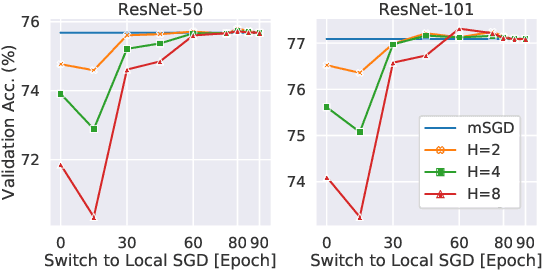
As datasets and models become increasingly large, distributed training has become a necessary component to allow deep neural networks to train in reasonable amounts of time. However, distributed training can have substantial communication overhead that hinders its scalability. One strategy for reducing this overhead is to perform multiple unsynchronized SGD steps independently on each worker between synchronization steps, a technique known as local SGD. We conduct a comprehensive empirical study of local SGD and related methods on a large-scale image classification task. We find that performing local SGD comes at a price: lower communication costs (and thereby faster training) are accompanied by lower accuracy. This finding is in contrast from the smaller-scale experiments in prior work, suggesting that local SGD encounters challenges at scale. We further show that incorporating the slow momentum framework of Wang et al. (2020) consistently improves accuracy without requiring additional communication, hinting at future directions for potentially escaping this trade-off.
Transformed CNNs: recasting pre-trained convolutional layers with self-attention
Jun 10, 2021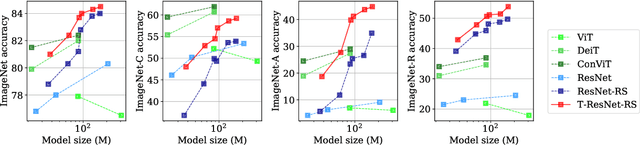
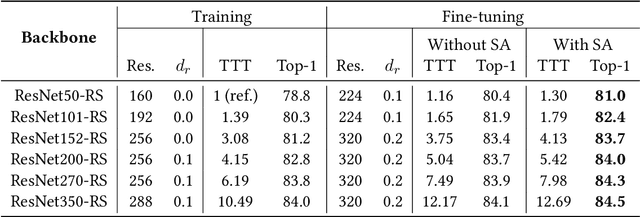
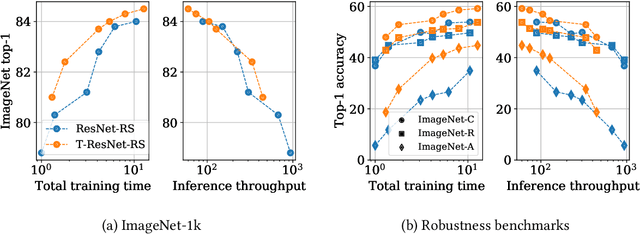
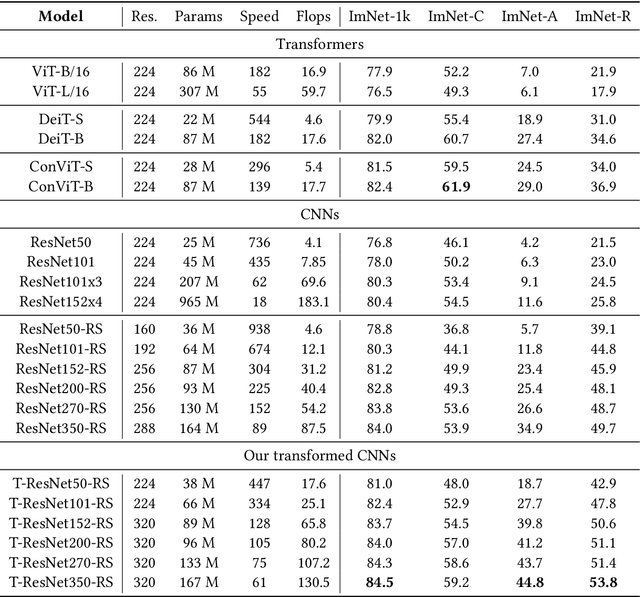
Vision Transformers (ViT) have recently emerged as a powerful alternative to convolutional networks (CNNs). Although hybrid models attempt to bridge the gap between these two architectures, the self-attention layers they rely on induce a strong computational bottleneck, especially at large spatial resolutions. In this work, we explore the idea of reducing the time spent training these layers by initializing them as convolutional layers. This enables us to transition smoothly from any pre-trained CNN to its functionally identical hybrid model, called Transformed CNN (T-CNN). With only 50 epochs of fine-tuning, the resulting T-CNNs demonstrate significant performance gains over the CNN (+2.2% top-1 on ImageNet-1k for a ResNet50-RS) as well as substantially improved robustness (+11% top-1 on ImageNet-C). We analyze the representations learnt by the T-CNN, providing deeper insights into the fruitful interplay between convolutions and self-attention. Finally, we experiment initializing the T-CNN from a partially trained CNN, and find that it reaches better performance than the corresponding hybrid model trained from scratch, while reducing training time.