 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Reward-Free Offline Data: A Case for Planning with Latent Dynamics Models
Feb 20, 2025



A long-standing goal in AI is to build agents that can solve a variety of tasks across different environments, including previously unseen ones. Two dominant approaches tackle this challenge: (i) reinforcement learning (RL), which learns policies through trial and error, and (ii) optimal control, which plans actions using a learned or known dynamics model. However, their relative strengths and weaknesses remain underexplored in the setting where agents must learn from offline trajectories without reward annotations. In this work, we systematically analyze the performance of different RL and control-based methods under datasets of varying quality. On the RL side, we consider goal-conditioned and zero-shot approaches. On the control side, we train a latent dynamics model using the Joint Embedding Predictive Architecture (JEPA) and use it for planning. We study how dataset properties-such as data diversity, trajectory quality, and environment variability-affect the performance of these approaches. Our results show that model-free RL excels when abundant, high-quality data is available, while model-based planning excels in generalization to novel environment layouts, trajectory stitching, and data-efficiency. Notably, planning with a latent dynamics model emerges as a promising approach for zero-shot generalization from suboptimal data.
$\mathbb{X}$-Sample Contrastive Loss: Improving Contrastive Learning with Sample Similarity Graphs
Jul 25, 2024



Learning good representations involves capturing the diverse ways in which data samples relate. Contrastive loss - an objective matching related samples - underlies methods from self-supervised to multimodal learning. Contrastive losses, however, can be viewed more broadly as modifying a similarity graph to indicate how samples should relate in the embedding space. This view reveals a shortcoming in contrastive learning: the similarity graph is binary, as only one sample is the related positive sample. Crucially, similarities \textit{across} samples are ignored. Based on this observation, we revise the standard contrastive loss to explicitly encode how a sample relates to others. We experiment with this new objective, called $\mathbb{X}$-Sample Contrastive, to train vision models based on similarities in class or text caption descriptions. Our study spans three scales: ImageNet-1k with 1 million, CC3M with 3 million, and CC12M with 12 million samples. The representations learned via our objective outperform both contrastive self-supervised and vision-language models trained on the same data across a range of tasks. When training on CC12M, we outperform CLIP by $0.6\%$ on both ImageNet and ImageNet Real. Our objective appears to work particularly well in lower-data regimes, with gains over CLIP of $16.8\%$ on ImageNet and $18.1\%$ on ImageNet Real when training with CC3M. Finally, our objective seems to encourage the model to learn representations that separate objects from their attributes and backgrounds, with gains of $3.3$-$5.6$\% over CLIP on ImageNet9. We hope the proposed solution takes a small step towards developing richer learning objectives for understanding sample relations in foundation models.
Hierarchical World Models as Visual Whole-Body Humanoid Controllers
May 28, 2024
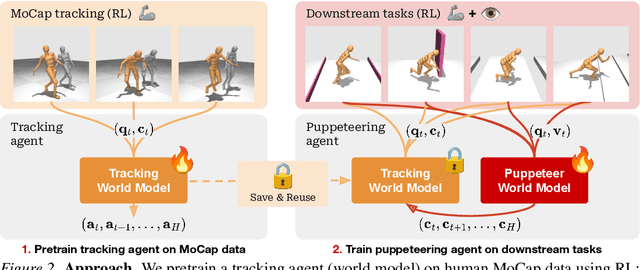

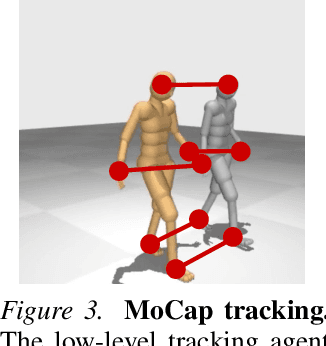
Whole-body control for humanoids is challenging due to the high-dimensional nature of the problem, coupled with the inherent instability of a bipedal morphology. Learning from visual observations further exacerbates this difficulty. In this work, we explore highly data-driven approaches to visual whole-body humanoid control based on reinforcement learning, without any simplifying assumptions, reward design, or skill primitives. Specifically, we propose a hierarchical world model in which a high-level agent generates commands based on visual observations for a low-level agent to execute, both of which are trained with rewards. Our approach produces highly performant control policies in 8 tasks with a simulated 56-DoF humanoid, while synthesizing motions that are broadly preferred by humans. Code and videos: https://nicklashansen.com/rlpuppeteer
Gradient-based Planning with World Models
Dec 28, 2023The enduring challenge in the field of artificial intelligence has been the control of systems to achieve desired behaviours. While for systems governed by straightforward dynamics equations, methods like Linear Quadratic Regulation (LQR) have historically proven highly effective, most real-world tasks, which require a general problem-solver, demand world models with dynamics that cannot be easily described by simple equations. Consequently, these models must be learned from data using neural networks. Most model predictive control (MPC) algorithms designed for visual world models have traditionally explored gradient-free population-based optimisation methods, such as Cross Entropy and Model Predictive Path Integral (MPPI) for planning. However, we present an exploration of a gradient-based alternative that fully leverages the differentiability of the world model. In our study, we conduct a comparative analysis between our method and other MPC-based alternatives, as well as policy-based algorithms. In a sample-efficient setting, our method achieves on par or superior performance compared to the alternative approaches in most tasks. Additionally, we introduce a hybrid model that combines policy networks and gradient-based MPC, which outperforms pure policy based methods thereby holding promise for Gradient-based planning with world models in complex real-world tasks.
A Cookbook of Self-Supervised Learning
Apr 24, 2023



Self-supervised learning, dubbed the dark matter of intelligence, is a promising path to advance machine learning. Yet, much like cooking, training SSL methods is a delicate art with a high barrier to entry. While many components are familiar, successfully training a SSL method involves a dizzying set of choices from the pretext tasks to training hyper-parameters. Our goal is to lower the barrier to entry into SSL research by laying the foundations and latest SSL recipes in the style of a cookbook. We hope to empower the curious researcher to navigate the terrain of methods, understand the role of the various knobs, and gain the know-how required to explore how delicious SSL can be.
Joint Embedding Predictive Architectures Focus on Slow Features
Nov 20, 2022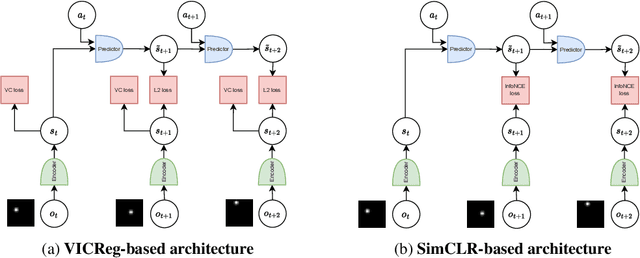
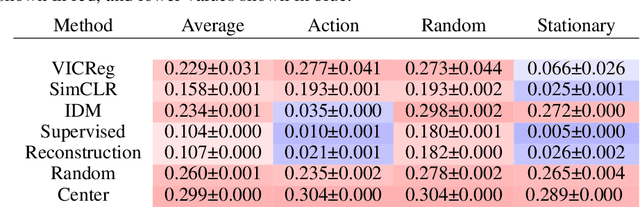

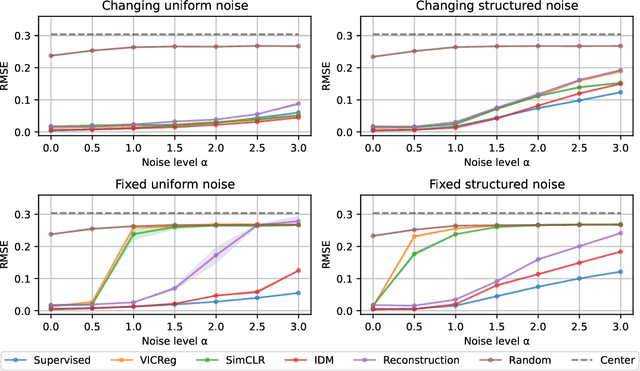
Many common methods for learning a world model for pixel-based environments use generative architectures trained with pixel-level reconstruction objectives. Recently proposed Joint Embedding Predictive Architectures (JEPA) offer a reconstruction-free alternative. In this work, we analyze performance of JEPA trained with VICReg and SimCLR objectives in the fully offline setting without access to rewards, and compare the results to the performance of the generative architecture. We test the methods in a simple environment with a moving dot with various background distractors, and probe learned representations for the dot's location. We find that JEPA methods perform on par or better than reconstruction when distractor noise changes every time step, but fail when the noise is fixed. Furthermore, we provide a theoretical explanation for the poor performance of JEPA-based methods with fixed noise, highlighting an important limitation.
Light-weight probing of unsupervised representations for Reinforcement Learning
Aug 25, 2022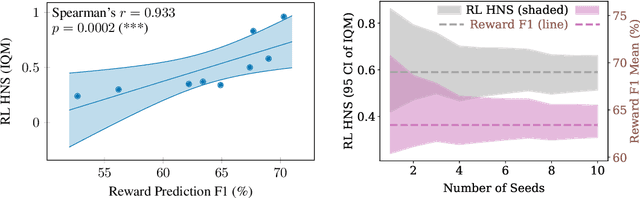
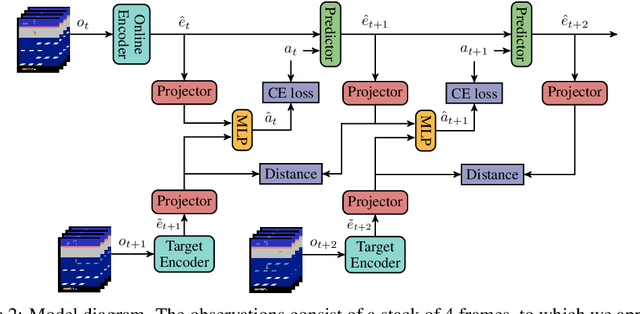
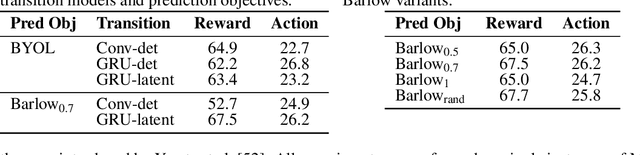

Unsupervised visual representation learning offers the opportunity to leverage large corpora of unlabeled trajectories to form useful visual representations, which can benefit the training of reinforcement learning (RL) algorithms. However, evaluating the fitness of such representations requires training RL algorithms which is computationally intensive and has high variance outcomes. To alleviate this issue, we design an evaluation protocol for unsupervised RL representations with lower variance and up to 600x lower computational cost. Inspired by the vision community, we propose two linear probing tasks: predicting the reward observed in a given state, and predicting the action of an expert in a given state. These two tasks are generally applicable to many RL domains, and we show through rigorous experimentation that they correlate strongly with the actual downstream control performance on the Atari100k Benchmark. This provides a better method for exploring the space of pretraining algorithms without the need of running RL evaluations for every setting. Leveraging this framework, we further improve existing self-supervised learning (SSL) recipes for RL, highlighting the importance of the forward model, the size of the visual backbone, and the precise formulation of the unsupervised objective.
Separating the World and Ego Models for Self-Driving
Apr 14, 2022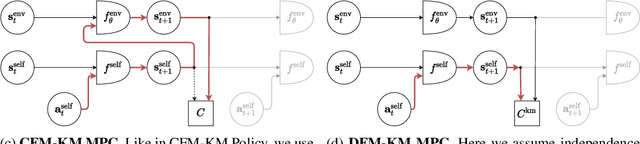

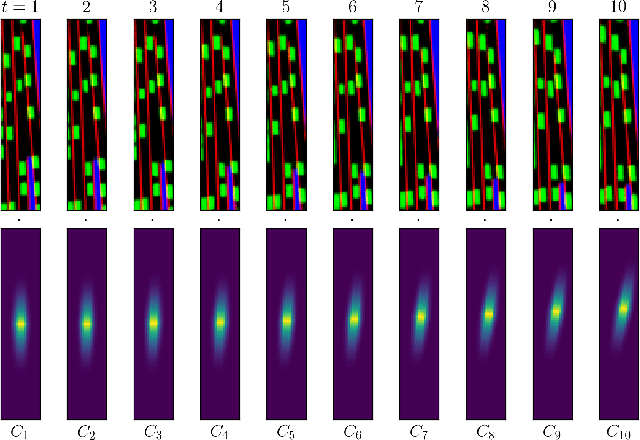
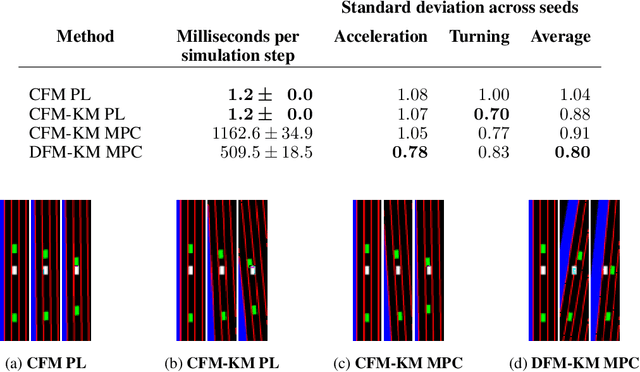
Training self-driving systems to be robust to the long-tail of driving scenarios is a critical problem. Model-based approaches leverage simulation to emulate a wide range of scenarios without putting users at risk in the real world. One promising path to faithful simulation is to train a forward model of the world to predict the future states of both the environment and the ego-vehicle given past states and a sequence of actions. In this paper, we argue that it is beneficial to model the state of the ego-vehicle, which often has simple, predictable and deterministic behavior, separately from the rest of the environment, which is much more complex and highly multimodal. We propose to model the ego-vehicle using a simple and differentiable kinematic model, while training a stochastic convolutional forward model on raster representations of the state to predict the behavior of the rest of the environment. We explore several configurations of such decoupled models, and evaluate their performance both with Model Predictive Control (MPC) and direct policy learning. We test our methods on the task of highway driving and demonstrate lower crash rates and better stability. The code is available at https://github.com/vladisai/pytorch-PPUU/tree/ICLR2022.