 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Spike, the Sparse and the Sink: Anatomy of Massive Activations and Attention Sinks
Mar 05, 2026We study two recurring phenomena in Transformer language models: massive activations, in which a small number of tokens exhibit extreme outliers in a few channels, and attention sinks, in which certain tokens attract disproportionate attention mass regardless of semantic relevance. Prior work observes that these phenomena frequently co-occur and often involve the same tokens, but their functional roles and causal relationship remain unclear. Through systematic experiments, we show that the co-occurrence is largely an architectural artifact of modern Transformer design, and that the two phenomena serve related but distinct functions. Massive activations operate globally: they induce near-constant hidden representations that persist across layers, effectively functioning as implicit parameters of the model. Attention sinks operate locally: they modulate attention outputs across heads and bias individual heads toward short-range dependencies. We identify the pre-norm configuration as the key choice that enables the co-occurrence, and show that ablating it causes the two phenomena to decouple.
TiCo: Transformation Invariance and Covariance Contrast for Self-Supervised Visual Representation Learning
Jun 23, 2022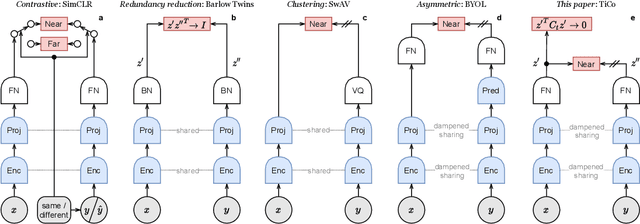
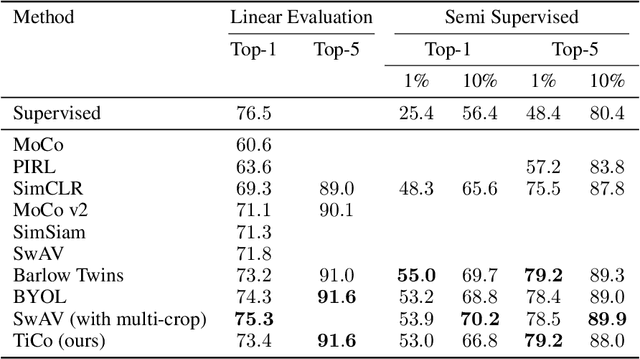
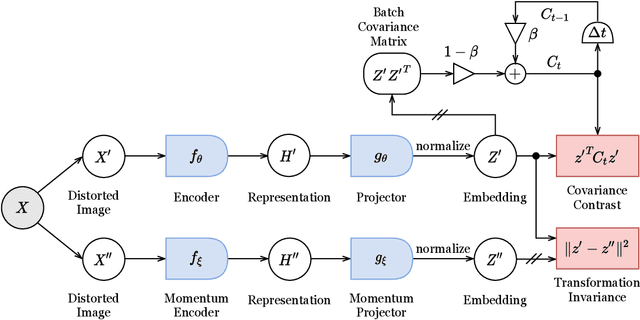
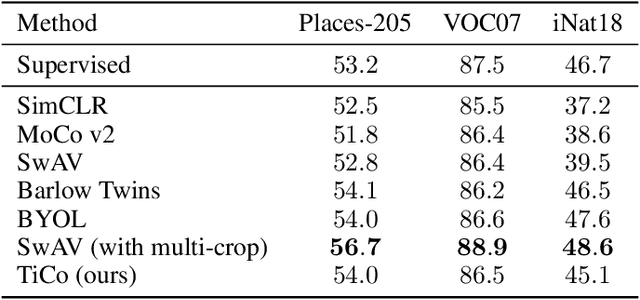
We present Transformation Invariance and Covariance Contrast (TiCo) for self-supervised visual representation learning. Similar to other recent self-supervised learning methods, our method is based on maximizing the agreement among embeddings of different distorted versions of the same image, which pushes the encoder to produce transformation invariant representations. To avoid the trivial solution where the encoder generates constant vectors, we regularize the covariance matrix of the embeddings from different images by penalizing low rank solutions. By jointly minimizing the transformation invariance loss and covariance contrast loss, we get an encoder that is able to produce useful representations for downstream tasks. We analyze our method and show that it can be viewed as a variant of MoCo with an implicit memory bank of unlimited size at no extra memory cost. This makes our method perform better than alternative methods when using small batch sizes. TiCo can also be seen as a modification of Barlow Twins. By connecting the contrastive and redundancy-reduction methods together, TiCo gives us new insights into how joint embedding methods work.
Separating the World and Ego Models for Self-Driving
Apr 14, 2022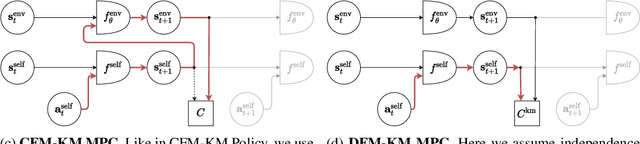

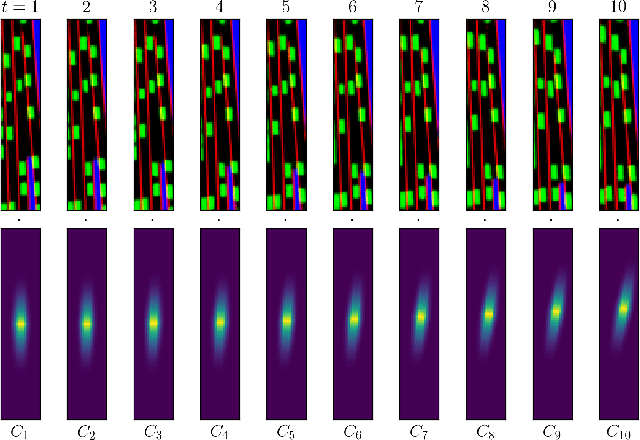
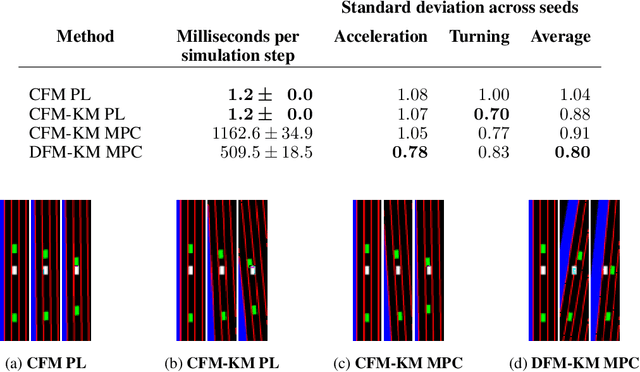
Training self-driving systems to be robust to the long-tail of driving scenarios is a critical problem. Model-based approaches leverage simulation to emulate a wide range of scenarios without putting users at risk in the real world. One promising path to faithful simulation is to train a forward model of the world to predict the future states of both the environment and the ego-vehicle given past states and a sequence of actions. In this paper, we argue that it is beneficial to model the state of the ego-vehicle, which often has simple, predictable and deterministic behavior, separately from the rest of the environment, which is much more complex and highly multimodal. We propose to model the ego-vehicle using a simple and differentiable kinematic model, while training a stochastic convolutional forward model on raster representations of the state to predict the behavior of the rest of the environment. We explore several configurations of such decoupled models, and evaluate their performance both with Model Predictive Control (MPC) and direct policy learning. We test our methods on the task of highway driving and demonstrate lower crash rates and better stability. The code is available at https://github.com/vladisai/pytorch-PPUU/tree/ICLR2022.
Model-Predictive Policy Learning with Uncertainty Regularization for Driving in Dense Traffic
Jan 08, 2019
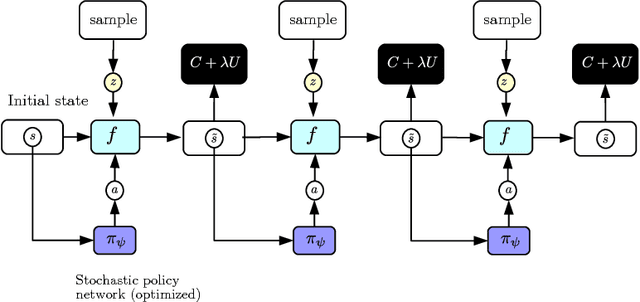
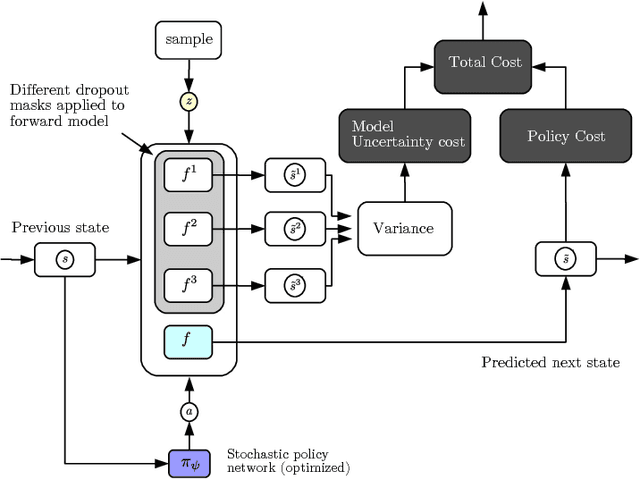

Learning a policy using only observational data is challenging because the distribution of states it induces at execution time may differ from the distribution observed during training. We propose to train a policy by unrolling a learned model of the environment dynamics over multiple time steps while explicitly penalizing two costs: the original cost the policy seeks to optimize, and an uncertainty cost which represents its divergence from the states it is trained on. We measure this second cost by using the uncertainty of the dynamics model about its own predictions, using recent ideas from uncertainty estimation for deep networks. We evaluate our approach using a large-scale observational dataset of driving behavior recorded from traffic cameras, and show that we are able to learn effective driving policies from purely observational data, with no environment interaction.
CortexNet: a Generic Network Family for Robust Visual Temporal Representations
Jun 14, 2017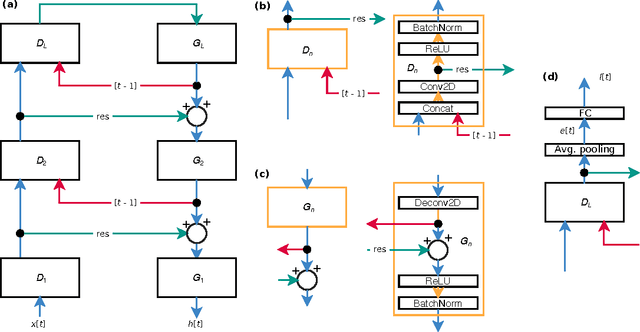
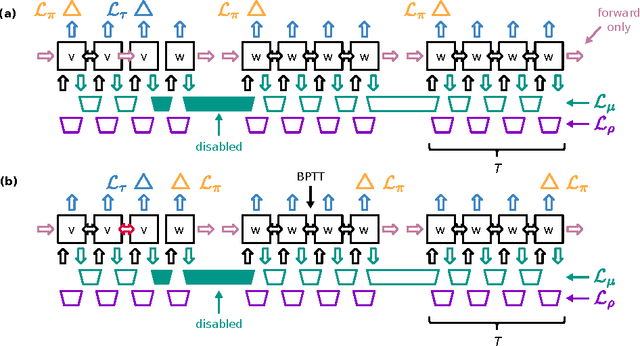
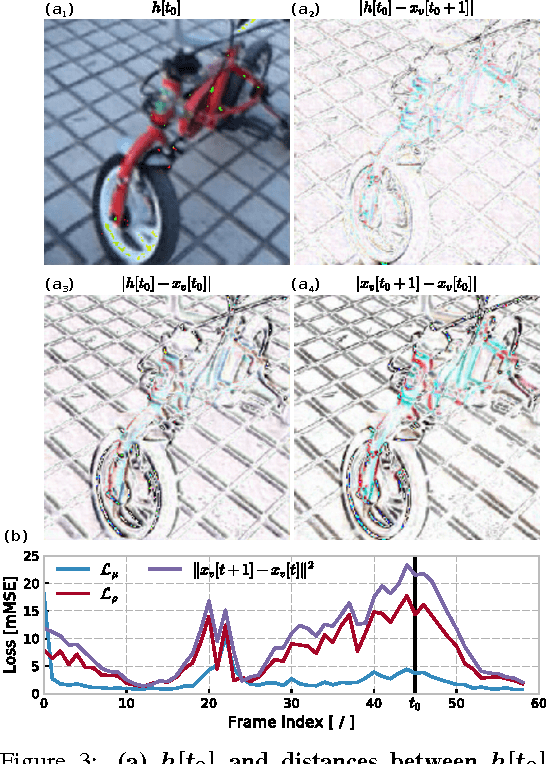
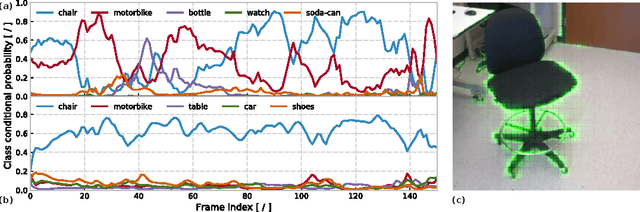
In the past five years we have observed the rise of incredibly well performing feed-forward neural networks trained supervisedly for vision related tasks. These models have achieved super-human performance on object recognition, localisation, and detection in still images. However, there is a need to identify the best strategy to employ these networks with temporal visual inputs and obtain a robust and stable representation of video data. Inspired by the human visual system, we propose a deep neural network family, CortexNet, which features not only bottom-up feed-forward connections, but also it models the abundant top-down feedback and lateral connections, which are present in our visual cortex. We introduce two training schemes - the unsupervised MatchNet and weakly supervised TempoNet modes - where a network learns how to correctly anticipate a subsequent frame in a video clip or the identity of its predominant subject, by learning egomotion clues and how to automatically track several objects in the current scene. Find the project website at https://engineering.purdue.edu/elab/CortexNet/.
An Analysis of Deep Neural Network Models for Practical Applications
Apr 14, 2017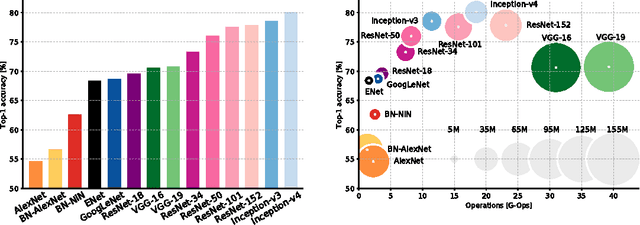
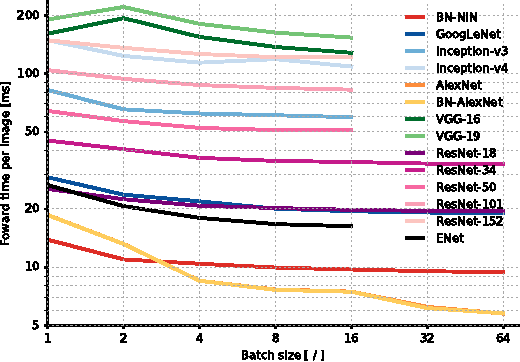
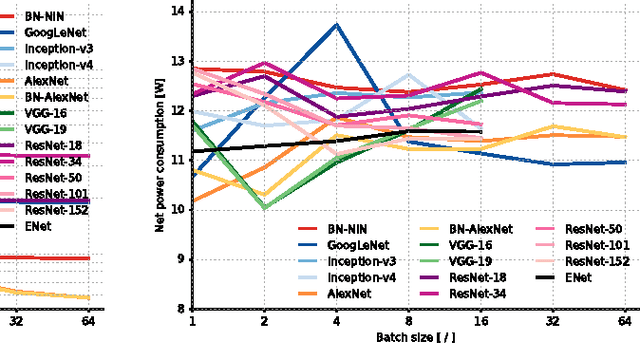
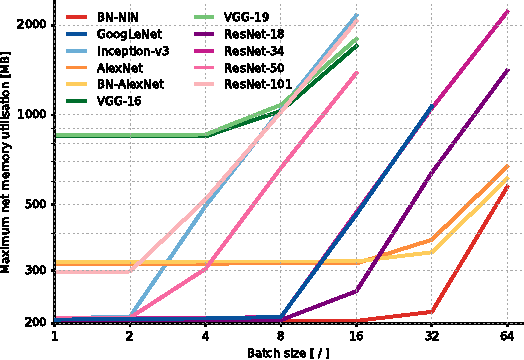
Since the emergence of Deep Neural Networks (DNNs) as a prominent technique in the field of computer vision, the ImageNet classification challenge has played a major role in advancing the state-of-the-art. While accuracy figures have steadily increased, the resource utilisation of winning models has not been properly taken into account. In this work, we present a comprehensive analysis of important metrics in practical applications: accuracy, memory footprint, parameters, operations count, inference time and power consumption. Key findings are: (1) power consumption is independent of batch size and architecture; (2) accuracy and inference time are in a hyperbolic relationship; (3) energy constraint is an upper bound on the maximum achievable accuracy and model complexity; (4) the number of operations is a reliable estimate of the inference time. We believe our analysis provides a compelling set of information that helps design and engineer efficient DNNs.