 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Behaviour Spaces
Apr 27, 2026Recent work in hierarchical reinforcement learning has shown success in scaling to billions of timesteps when learning over a set of predefined option reward functions. We show that, instead of using a single reward function per option, the reward functions can be effectively used to induce a space of behaviours, by letting the controller specify linear combinations over reward functions, allowing a more expressive set of policies to be represented. We call this method Hierarchical Behaviour Spaces (HBS). We evaluate HBS on the NetHack Learning Environment, demonstrating strong performance. We conduct a series of experiments and determine that, perhaps going against conventional wisdom, the benefits of hierarchy in our method come from increased exploration rather than long term reasoning.
The Surprising Difficulty of Search in Model-Based Reinforcement Learning
Jan 29, 2026This paper investigates search in model-based reinforcement learning (RL). Conventional wisdom holds that long-term predictions and compounding errors are the primary obstacles for model-based RL. We challenge this view, showing that search is not a plug-and-play replacement for a learned policy. Surprisingly, we find that search can harm performance even when the model is highly accurate. Instead, we show that mitigating distribution shift matters more than improving model or value function accuracy. Building on this insight, we identify key techniques for enabling effective search, achieving state-of-the-art performance across multiple popular benchmark domains.
Locate 3D: Real-World Object Localization via Self-Supervised Learning in 3D
Apr 19, 2025We present LOCATE 3D, a model for localizing objects in 3D scenes from referring expressions like "the small coffee table between the sofa and the lamp." LOCATE 3D sets a new state-of-the-art on standard referential grounding benchmarks and showcases robust generalization capabilities. Notably, LOCATE 3D operates directly on sensor observation streams (posed RGB-D frames), enabling real-world deployment on robots and AR devices. Key to our approach is 3D-JEPA, a novel self-supervised learning (SSL) algorithm applicable to sensor point clouds. It takes as input a 3D pointcloud featurized using 2D foundation models (CLIP, DINO). Subsequently, masked prediction in latent space is employed as a pretext task to aid the self-supervised learning of contextualized pointcloud features. Once trained, the 3D-JEPA encoder is finetuned alongside a language-conditioned decoder to jointly predict 3D masks and bounding boxes. Additionally, we introduce LOCATE 3D DATASET, a new dataset for 3D referential grounding, spanning multiple capture setups with over 130K annotations. This enables a systematic study of generalization capabilities as well as a stronger model.
Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass
Jan 23, 2025Multi-view 3D reconstruction remains a core challenge in computer vision, particularly in applications requiring accurate and scalable representations across diverse perspectives. Current leading methods such as DUSt3R employ a fundamentally pairwise approach, processing images in pairs and necessitating costly global alignment procedures to reconstruct from multiple views. In this work, we propose Fast 3D Reconstruction (Fast3R), a novel multi-view generalization to DUSt3R that achieves efficient and scalable 3D reconstruction by processing many views in parallel. Fast3R's Transformer-based architecture forwards N images in a single forward pass, bypassing the need for iterative alignment. Through extensive experiments on camera pose estimation and 3D reconstruction, Fast3R demonstrates state-of-the-art performance, with significant improvements in inference speed and reduced error accumulation. These results establish Fast3R as a robust alternative for multi-view applications, offering enhanced scalability without compromising reconstruction accuracy.
MaestroMotif: Skill Design from Artificial Intelligence Feedback
Dec 11, 2024
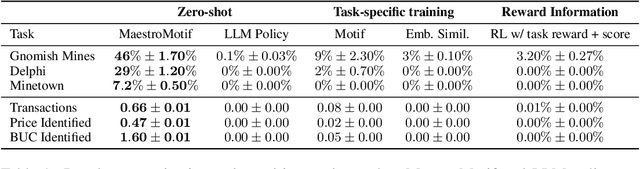

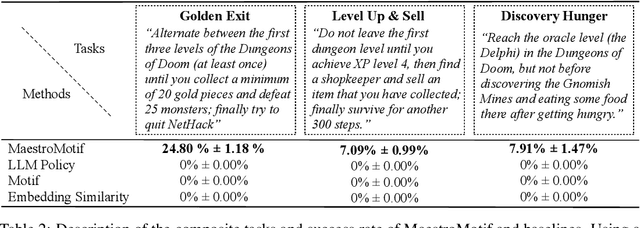
Describing skills in natural language has the potential to provide an accessible way to inject human knowledge about decision-making into an AI system. We present MaestroMotif, a method for AI-assisted skill design, which yields high-performing and adaptable agents. MaestroMotif leverages the capabilities of Large Language Models (LLMs) to effectively create and reuse skills. It first uses an LLM's feedback to automatically design rewards corresponding to each skill, starting from their natural language description. Then, it employs an LLM's code generation abilities, together with reinforcement learning, for training the skills and combining them to implement complex behaviors specified in language. We evaluate MaestroMotif using a suite of complex tasks in the NetHack Learning Environment (NLE), demonstrating that it surpasses existing approaches in both performance and usability.
Online Intrinsic Rewards for Decision Making Agents from Large Language Model Feedback
Oct 30, 2024Automatically synthesizing dense rewards from natural language descriptions is a promising paradigm in reinforcement learning (RL), with applications to sparse reward problems, open-ended exploration, and hierarchical skill design. Recent works have made promising steps by exploiting the prior knowledge of large language models (LLMs). However, these approaches suffer from important limitations: they are either not scalable to problems requiring billions of environment samples; or are limited to reward functions expressible by compact code, which may require source code and have difficulty capturing nuanced semantics; or require a diverse offline dataset, which may not exist or be impossible to collect. In this work, we address these limitations through a combination of algorithmic and systems-level contributions. We propose ONI, a distributed architecture that simultaneously learns an RL policy and an intrinsic reward function using LLM feedback. Our approach annotates the agent's collected experience via an asynchronous LLM server, which is then distilled into an intrinsic reward model. We explore a range of algorithmic choices for reward modeling with varying complexity, including hashing, classification, and ranking models. By studying their relative tradeoffs, we shed light on questions regarding intrinsic reward design for sparse reward problems. Our approach achieves state-of-the-art performance across a range of challenging, sparse reward tasks from the NetHack Learning Environment in a simple unified process, solely using the agent's gathered experience, without requiring external datasets nor source code. We make our code available at \url{URL} (coming soon).
Generalization to New Sequential Decision Making Tasks with In-Context Learning
Dec 06, 2023



Training autonomous agents that can learn new tasks from only a handful of demonstrations is a long-standing problem in machine learning. Recently, transformers have been shown to learn new language or vision tasks without any weight updates from only a few examples, also referred to as in-context learning. However, the sequential decision making setting poses additional challenges having a lower tolerance for errors since the environment's stochasticity or the agent's actions can lead to unseen, and sometimes unrecoverable, states. In this paper, we use an illustrative example to show that naively applying transformers to sequential decision making problems does not enable in-context learning of new tasks. We then demonstrate how training on sequences of trajectories with certain distributional properties leads to in-context learning of new sequential decision making tasks. We investigate different design choices and find that larger model and dataset sizes, as well as more task diversity, environment stochasticity, and trajectory burstiness, all result in better in-context learning of new out-of-distribution tasks. By training on large diverse offline datasets, our model is able to learn new MiniHack and Procgen tasks without any weight updates from just a handful of demonstrations.
Motif: Intrinsic Motivation from Artificial Intelligence Feedback
Sep 29, 2023



Exploring rich environments and evaluating one's actions without prior knowledge is immensely challenging. In this paper, we propose Motif, a general method to interface such prior knowledge from a Large Language Model (LLM) with an agent. Motif is based on the idea of grounding LLMs for decision-making without requiring them to interact with the environment: it elicits preferences from an LLM over pairs of captions to construct an intrinsic reward, which is then used to train agents with reinforcement learning. We evaluate Motif's performance and behavior on the challenging, open-ended and procedurally-generated NetHack game. Surprisingly, by only learning to maximize its intrinsic reward, Motif achieves a higher game score than an algorithm directly trained to maximize the score itself. When combining Motif's intrinsic reward with the environment reward, our method significantly outperforms existing approaches and makes progress on tasks where no advancements have ever been made without demonstrations. Finally, we show that Motif mostly generates intuitive human-aligned behaviors which can be steered easily through prompt modifications, while scaling well with the LLM size and the amount of information given in the prompt.
A Study of Global and Episodic Bonuses for Exploration in Contextual MDPs
Jun 05, 2023Exploration in environments which differ across episodes has received increasing attention in recent years. Current methods use some combination of global novelty bonuses, computed using the agent's entire training experience, and \textit{episodic novelty bonuses}, computed using only experience from the current episode. However, the use of these two types of bonuses has been ad-hoc and poorly understood. In this work, we shed light on the behavior of these two types of bonuses through controlled experiments on easily interpretable tasks as well as challenging pixel-based settings. We find that the two types of bonuses succeed in different settings, with episodic bonuses being most effective when there is little shared structure across episodes and global bonuses being effective when more structure is shared. We develop a conceptual framework which makes this notion of shared structure precise by considering the variance of the value function across contexts, and which provides a unifying explanation of our empirical results. We furthermore find that combining the two bonuses can lead to more robust performance across different degrees of shared structure, and investigate different algorithmic choices for defining and combining global and episodic bonuses based on function approximation. This results in an algorithm which sets a new state of the art across 16 tasks from the MiniHack suite used in prior work, and also performs robustly on Habitat and Montezuma's Revenge.
Semi-Supervised Offline Reinforcement Learning with Action-Free Trajectories
Oct 12, 2022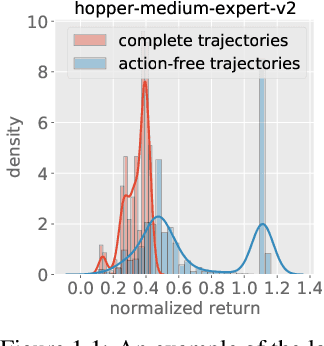
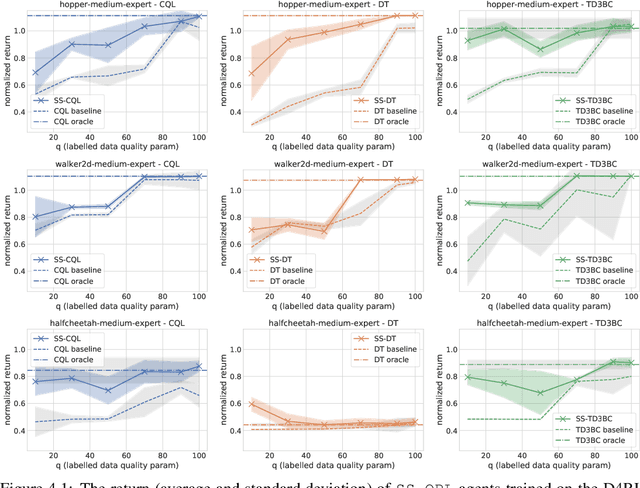
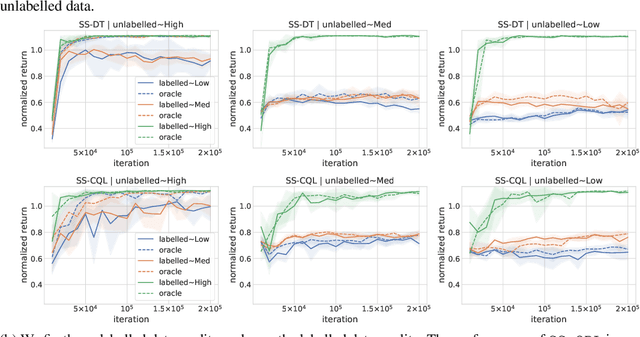
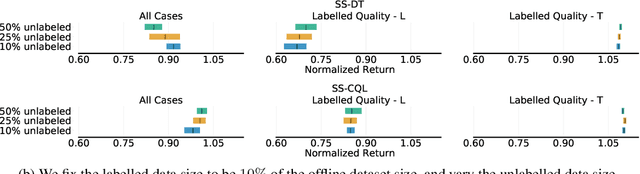
Natural agents can effectively learn from multiple data sources that differ in size, quality, and types of measurements. We study this heterogeneity in the context of offline reinforcement learning (RL) by introducing a new, practically motivated semi-supervised setting. Here, an agent has access to two sets of trajectories: labelled trajectories containing state, action, reward triplets at every timestep, along with unlabelled trajectories that contain only state and reward information. For this setting, we develop a simple meta-algorithmic pipeline that learns an inverse-dynamics model on the labelled data to obtain proxy-labels for the unlabelled data, followed by the use of any offline RL algorithm on the true and proxy-labelled trajectories. Empirically, we find this simple pipeline to be highly successful -- on several D4RL benchmarks \cite{fu2020d4rl}, certain offline RL algorithms can match the performance of variants trained on a fully labeled dataset even when we label only 10\% trajectories from the low return regime. Finally, we perform a large-scale controlled empirical study investigating the interplay of data-centric properties of the labelled and unlabelled datasets, with algorithmic design choices (e.g., inverse dynamics, offline RL algorithm) to identify general trends and best practices for training RL agents on semi-supervised offline datasets.