 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect of Document Packing on the Latent Multi-Hop Reasoning Capabilities of Large Language Models
Dec 16, 2025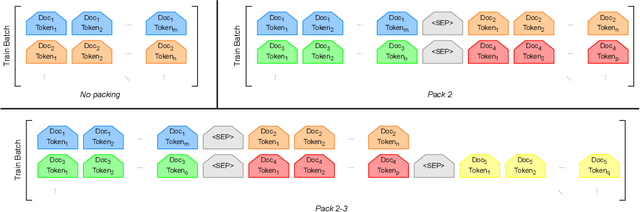
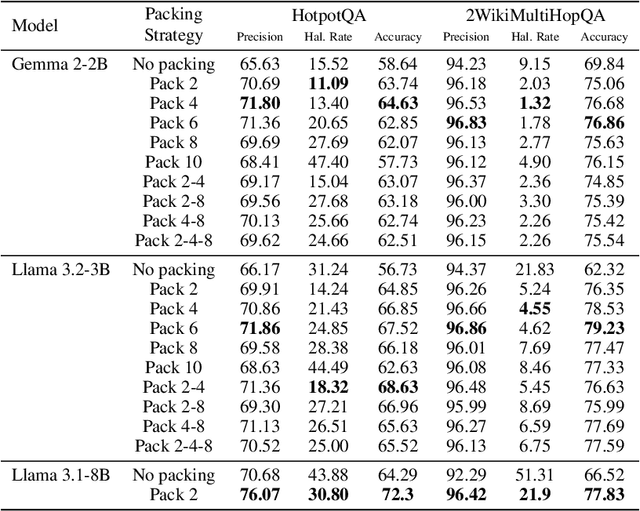


The standard practice for training large language models involves packing multiple documents together to optimize computational efficiency. However, the impact of this process on the models' capabilities remains largely unexplored. To address this gap, we investigate how different document-packing strategies influence the latent multi-hop reasoning abilities of LLMs. Our findings indicate that packing can improve model performance compared to training on individual documents, at the expense of more compute. To further understand the underlying mechanisms, we conduct an ablation study, identifying key factors that explain the advantages of packing. Ultimately, our research deepens the understanding of LLM training dynamics and provides practical insights for optimizing model development.
Scaling and Distilling Transformer Models for sEMG
Jul 29, 2025Surface electromyography (sEMG) signals offer a promising avenue for developing innovative human-computer interfaces by providing insights into muscular activity. However, the limited volume of training data and computational constraints during deployment have restricted the investigation of scaling up the model size for solving sEMG tasks. In this paper, we demonstrate that vanilla transformer models can be effectively scaled up on sEMG data and yield improved cross-user performance up to 110M parameters, surpassing the model size regime investigated in other sEMG research (usually <10M parameters). We show that >100M-parameter models can be effectively distilled into models 50x smaller with minimal loss of performance (<1.5% absolute). This results in efficient and expressive models suitable for complex real-time sEMG tasks in real-world environments.
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Jul 03, 2025AI research agents are demonstrating great potential to accelerate scientific progress by automating the design, implementation, and training of machine learning models. We focus on methods for improving agents' performance on MLE-bench, a challenging benchmark where agents compete in Kaggle competitions to solve real-world machine learning problems. We formalize AI research agents as search policies that navigate a space of candidate solutions, iteratively modifying them using operators. By designing and systematically varying different operator sets and search policies (Greedy, MCTS, Evolutionary), we show that their interplay is critical for achieving high performance. Our best pairing of search strategy and operator set achieves a state-of-the-art result on MLE-bench lite, increasing the success rate of achieving a Kaggle medal from 39.6% to 47.7%. Our investigation underscores the importance of jointly considering the search strategy, operator design, and evaluation methodology in advancing automated machine learning.
Do Large Language Models Know How Much They Know?
Feb 26, 2025Large Language Models (LLMs) have emerged as highly capable systems and are increasingly being integrated into various uses. However, the rapid pace of their deployment has outpaced a comprehensive understanding of their internal mechanisms and a delineation of their capabilities and limitations. A desired attribute of an intelligent system is its ability to recognize the scope of its own knowledge. To investigate whether LLMs embody this characteristic, we develop a benchmark designed to challenge these models to enumerate all information they possess on specific topics. This benchmark evaluates whether the models recall excessive, insufficient, or the precise amount of information, thereby indicating their awareness of their own knowledge. Our findings reveal that all tested LLMs, given sufficient scale, demonstrate an understanding of how much they know about specific topics. While different architectures exhibit varying rates of this capability's emergence, the results suggest that awareness of knowledge may be a generalizable attribute of LLMs. Further research is needed to confirm this potential and fully elucidate the underlying mechanisms.
MaestroMotif: Skill Design from Artificial Intelligence Feedback
Dec 11, 2024
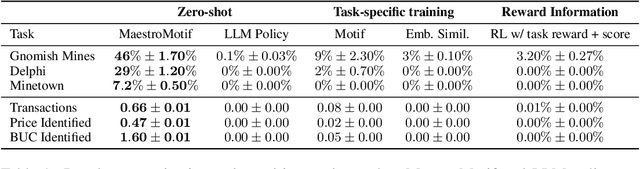

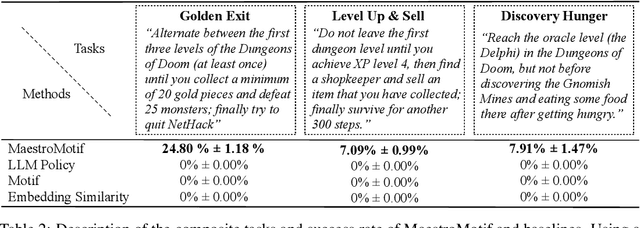
Describing skills in natural language has the potential to provide an accessible way to inject human knowledge about decision-making into an AI system. We present MaestroMotif, a method for AI-assisted skill design, which yields high-performing and adaptable agents. MaestroMotif leverages the capabilities of Large Language Models (LLMs) to effectively create and reuse skills. It first uses an LLM's feedback to automatically design rewards corresponding to each skill, starting from their natural language description. Then, it employs an LLM's code generation abilities, together with reinforcement learning, for training the skills and combining them to implement complex behaviors specified in language. We evaluate MaestroMotif using a suite of complex tasks in the NetHack Learning Environment (NLE), demonstrating that it surpasses existing approaches in both performance and usability.
EpiK-Eval: Evaluation for Language Models as Epistemic Models
Oct 23, 2023In the age of artificial intelligence, the role of large language models (LLMs) is becoming increasingly central. Despite their growing prevalence, their capacity to consolidate knowledge from different training documents - a crucial ability in numerous applications - remains unexplored. This paper presents the first study examining the capability of LLMs to effectively combine such information within their parameter space. We introduce EpiK-Eval, a novel question-answering benchmark tailored to evaluate LLMs' proficiency in formulating a coherent and consistent knowledge representation from segmented narratives. Evaluations across various LLMs reveal significant weaknesses in this domain. We contend that these shortcomings stem from the intrinsic nature of prevailing training objectives. Consequently, we advocate for refining the approach towards knowledge consolidation, as it harbors the potential to dramatically improve their overall effectiveness and performance. The findings from this study offer insights for developing more robust and reliable LLMs. Our code and benchmark are available at https://github.com/chandar-lab/EpiK-Eval
Motif: Intrinsic Motivation from Artificial Intelligence Feedback
Sep 29, 2023



Exploring rich environments and evaluating one's actions without prior knowledge is immensely challenging. In this paper, we propose Motif, a general method to interface such prior knowledge from a Large Language Model (LLM) with an agent. Motif is based on the idea of grounding LLMs for decision-making without requiring them to interact with the environment: it elicits preferences from an LLM over pairs of captions to construct an intrinsic reward, which is then used to train agents with reinforcement learning. We evaluate Motif's performance and behavior on the challenging, open-ended and procedurally-generated NetHack game. Surprisingly, by only learning to maximize its intrinsic reward, Motif achieves a higher game score than an algorithm directly trained to maximize the score itself. When combining Motif's intrinsic reward with the environment reward, our method significantly outperforms existing approaches and makes progress on tasks where no advancements have ever been made without demonstrations. Finally, we show that Motif mostly generates intuitive human-aligned behaviors which can be steered easily through prompt modifications, while scaling well with the LLM size and the amount of information given in the prompt.
TorchRL: A data-driven decision-making library for PyTorch
Jun 01, 2023Striking a balance between integration and modularity is crucial for a machine learning library to be versatile and user-friendly, especially in handling decision and control tasks that involve large development teams and complex, real-world data, and environments. To address this issue, we propose TorchRL, a generalistic control library for PyTorch that provides well-integrated, yet standalone components. With a versatile and robust primitive design, TorchRL facilitates streamlined algorithm development across the many branches of Reinforcement Learning (RL) and control. We introduce a new PyTorch primitive, TensorDict, as a flexible data carrier that empowers the integration of the library's components while preserving their modularity. Hence replay buffers, datasets, distributed data collectors, environments, transforms and objectives can be effortlessly used in isolation or combined. We provide a detailed description of the building blocks, supporting code examples and an extensive overview of the library across domains and tasks. Finally, we show comparative benchmarks to demonstrate its computational efficiency. TorchRL fosters long-term support and is publicly available on GitHub for greater reproducibility and collaboration within the research community. The code is opensourced on https://github.com/pytorch/rl.
Sequence Modeling is a Robust Contender for Offline Reinforcement Learning
May 26, 2023Offline reinforcement learning (RL) allows agents to learn effective, return-maximizing policies from a static dataset. Three major paradigms for offline RL are Q-Learning, Imitation Learning, and Sequence Modeling. A key open question is: which paradigm is preferred under what conditions? We study this question empirically by exploring the performance of representative algorithms -- Conservative Q-Learning (CQL), Behavior Cloning (BC), and Decision Transformer (DT) -- across the commonly used D4RL and Robomimic benchmarks. We design targeted experiments to understand their behavior concerning data suboptimality and task complexity. Our key findings are: (1) Sequence Modeling requires more data than Q-Learning to learn competitive policies but is more robust; (2) Sequence Modeling is a substantially better choice than both Q-Learning and Imitation Learning in sparse-reward and low-quality data settings; and (3) Sequence Modeling and Imitation Learning are preferable as task horizon increases, or when data is obtained from human demonstrators. Based on the overall strength of Sequence Modeling, we also investigate architectural choices and scaling trends for DT on Atari and D4RL and make design recommendations. We find that scaling the amount of data for DT by 5x gives a 2.5x average score improvement on Atari.
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Sep 30, 2022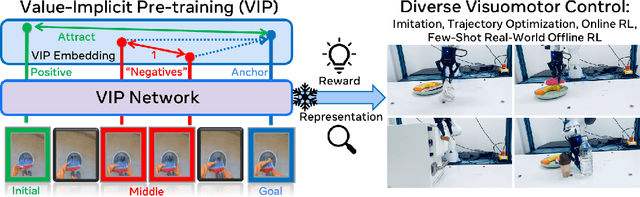


Reward and representation learning are two long-standing challenges for learning an expanding set of robot manipulation skills from sensory observations. Given the inherent cost and scarcity of in-domain, task-specific robot data, learning from large, diverse, offline human videos has emerged as a promising path towards acquiring a generally useful visual representation for control; however, how these human videos can be used for general-purpose reward learning remains an open question. We introduce $\textbf{V}$alue-$\textbf{I}$mplicit $\textbf{P}$re-training (VIP), a self-supervised pre-trained visual representation capable of generating dense and smooth reward functions for unseen robotic tasks. VIP casts representation learning from human videos as an offline goal-conditioned reinforcement learning problem and derives a self-supervised dual goal-conditioned value-function objective that does not depend on actions, enabling pre-training on unlabeled human videos. Theoretically, VIP can be understood as a novel implicit time contrastive objective that generates a temporally smooth embedding, enabling the value function to be implicitly defined via the embedding distance, which can then be used to construct the reward for any goal-image specified downstream task. Trained on large-scale Ego4D human videos and without any fine-tuning on in-domain, task-specific data, VIP's frozen representation can provide dense visual reward for an extensive set of simulated and $\textbf{real-robot}$ tasks, enabling diverse reward-based visual control methods and significantly outperforming all prior pre-trained representations. Notably, VIP can enable simple, $\textbf{few-shot}$ offline RL on a suite of real-world robot tasks with as few as 20 trajectories.