 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity
Nov 19, 2025AI research agents offer the promise to accelerate scientific progress by automating the design, implementation, and training of machine learning models. However, the field is still in its infancy, and the key factors driving the success or failure of agent trajectories are not fully understood. We examine the role that ideation diversity plays in agent performance. First, we analyse agent trajectories on MLE-bench, a well-known benchmark to evaluate AI research agents, across different models and agent scaffolds. Our analysis reveals that different models and agent scaffolds yield varying degrees of ideation diversity, and that higher-performing agents tend to have increased ideation diversity. Further, we run a controlled experiment where we modify the degree of ideation diversity, demonstrating that higher ideation diversity results in stronger performance. Finally, we strengthen our results by examining additional evaluation metrics beyond the standard medal-based scoring of MLE-bench, showing that our findings still hold across other agent performance metrics.
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Jul 03, 2025AI research agents are demonstrating great potential to accelerate scientific progress by automating the design, implementation, and training of machine learning models. We focus on methods for improving agents' performance on MLE-bench, a challenging benchmark where agents compete in Kaggle competitions to solve real-world machine learning problems. We formalize AI research agents as search policies that navigate a space of candidate solutions, iteratively modifying them using operators. By designing and systematically varying different operator sets and search policies (Greedy, MCTS, Evolutionary), we show that their interplay is critical for achieving high performance. Our best pairing of search strategy and operator set achieves a state-of-the-art result on MLE-bench lite, increasing the success rate of achieving a Kaggle medal from 39.6% to 47.7%. Our investigation underscores the importance of jointly considering the search strategy, operator design, and evaluation methodology in advancing automated machine learning.
POPGym Arcade: Parallel Pixelated POMDPs
Mar 04, 2025We introduce POPGym Arcade, a benchmark consisting of 7 pixel-based environments each with three difficulties, utilizing a single observation and action space. Each environment offers both fully observable and partially observable variants, enabling counterfactual studies on partial observability. POPGym Arcade utilizes JIT compilation on hardware accelerators to achieve substantial speedups over CPU-bound environments. Moreover, this enables Podracer-style architectures to further increase hardware utilization and training speed. We evaluate memory models on our environments using a Podracer variant of Q learning, and examine the results. Finally, we generate memory saliency maps, uncovering how memories propagate through policies. Our library is available at https://github.com/bolt-research/popgym_arcade.
Beyond the Boundaries of Proximal Policy Optimization
Nov 01, 2024
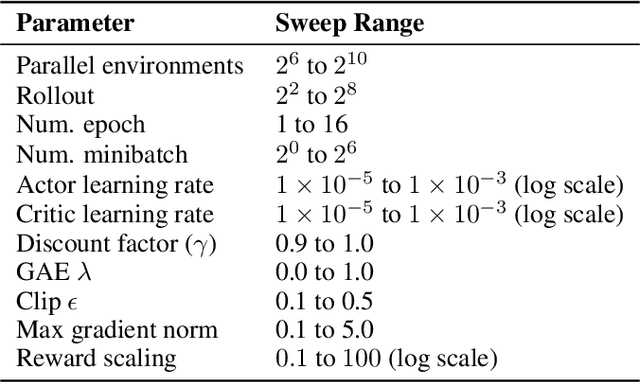
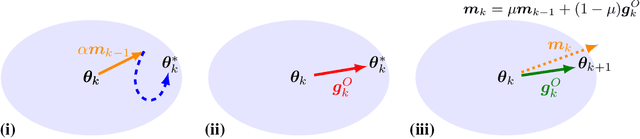

Proximal policy optimization (PPO) is a widely-used algorithm for on-policy reinforcement learning. This work offers an alternative perspective of PPO, in which it is decomposed into the inner-loop estimation of update vectors, and the outer-loop application of updates using gradient ascent with unity learning rate. Using this insight we propose outer proximal policy optimization (outer-PPO); a framework wherein these update vectors are applied using an arbitrary gradient-based optimizer. The decoupling of update estimation and update application enabled by outer-PPO highlights several implicit design choices in PPO that we challenge through empirical investigation. In particular we consider non-unity learning rates and momentum applied to the outer loop, and a momentum-bias applied to the inner estimation loop. Methods are evaluated against an aggressively tuned PPO baseline on Brax, Jumanji and MinAtar environments; non-unity learning rates and momentum both achieve statistically significant improvement on Brax and Jumanji, given the same hyperparameter tuning budget.
CoDreamer: Communication-Based Decentralised World Models
Jun 19, 2024Sample efficiency is a critical challenge in reinforcement learning. Model-based RL has emerged as a solution, but its application has largely been confined to single-agent scenarios. In this work, we introduce CoDreamer, an extension of the Dreamer algorithm for multi-agent environments. CoDreamer leverages Graph Neural Networks for a two-level communication system to tackle challenges such as partial observability and inter-agent cooperation. Communication is separately utilised within the learned world models and within the learned policies of each agent to enhance modelling and task-solving. We show that CoDreamer offers greater expressive power than a naive application of Dreamer, and we demonstrate its superiority over baseline methods across various multi-agent environments.
SMX: Sequential Monte Carlo Planning for Expert Iteration
Feb 12, 2024Developing agents that can leverage planning abilities during their decision and learning processes is critical to the advancement of Artificial Intelligence. Recent works have demonstrated the effectiveness of combining tree-based search methods and self-play learning mechanisms. Yet, these methods typically face scaling challenges due to the sequential nature of their search. While practical engineering solutions can partly overcome this, they still demand extensive computational resources, which hinders their applicability. In this paper, we introduce SMX, a model-based planning algorithm that utilises scalable Sequential Monte Carlo methods to create an effective self-learning mechanism. Grounded in the theoretical framework of control as inference, SMX benefits from robust theoretical underpinnings. Its sampling-based search approach makes it adaptable to environments with both discrete and continuous action spaces. Furthermore, SMX allows for high parallelisation and can run on hardware accelerators to optimise computing efficiency. SMX demonstrates a statistically significant improvement in performance compared to AlphaZero, as well as demonstrating its performance as an improvement operator for a model-free policy, matching or exceeding top model-free methods across both continuous and discrete environments.