 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIRA_2: Overcoming Bottlenecks in AI Research Agents
Mar 27, 2026Existing research has identified three structural performance bottlenecks in AI research agents: (1) synchronous single-GPU execution constrains sample throughput, limiting the benefit of search; (2) a generalization gap where validation-based selection causes performance to degrade over extended search horizons; and (3) the limited capability of fixed, single-turn LLM operators imposes a ceiling on search performance. We introduce AIRA$_2$, which addresses these bottlenecks through three architectural choices: an asynchronous multi-GPU worker pool that increases experiment throughput linearly; a Hidden Consistent Evaluation protocol that delivers a reliable evaluation signal; and ReAct agents that dynamically scope their actions and debug interactively. On MLE-bench-30, AIRA$_2$ achieves a mean Percentile Rank of 71.8% at 24 hours - surpassing the previous best of 69.9% - and steadily improves to 76.0% at 72 hours. Ablation studies reveal that each component is necessary and that the "overfitting" reported in prior work was driven by evaluation noise rather than true data memorization.
APRES: An Agentic Paper Revision and Evaluation System
Mar 03, 2026Scientific discoveries must be communicated clearly to realize their full potential. Without effective communication, even the most groundbreaking findings risk being overlooked or misunderstood. The primary way scientists communicate their work and receive feedback from the community is through peer review. However, the current system often provides inconsistent feedback between reviewers, ultimately hindering the improvement of a manuscript and limiting its potential impact. In this paper, we introduce a novel method APRES powered by Large Language Models (LLMs) to update a scientific papers text based on an evaluation rubric. Our automated method discovers a rubric that is highly predictive of future citation counts, and integrate it with APRES in an automated system that revises papers to enhance their quality and impact. Crucially, this objective should be met without altering the core scientific content. We demonstrate the success of APRES, which improves future citation prediction by 19.6% in mean averaged error over the next best baseline, and show that our paper revision process yields papers that are preferred over the originals by human expert evaluators 79% of the time. Our findings provide strong empirical support for using LLMs as a tool to help authors stress-test their manuscripts before submission. Ultimately, our work seeks to augment, not replace, the essential role of human expert reviewers, for it should be humans who discern which discoveries truly matter, guiding science toward advancing knowledge and enriching lives.
AIRS-Bench: a Suite of Tasks for Frontier AI Research Science Agents
Feb 09, 2026LLM agents hold significant promise for advancing scientific research. To accelerate this progress, we introduce AIRS-Bench (the AI Research Science Benchmark), a suite of 20 tasks sourced from state-of-the-art machine learning papers. These tasks span diverse domains, including language modeling, mathematics, bioinformatics, and time series forecasting. AIRS-Bench tasks assess agentic capabilities over the full research lifecycle -- including idea generation, experiment analysis and iterative refinement -- without providing baseline code. The AIRS-Bench task format is versatile, enabling easy integration of new tasks and rigorous comparison across different agentic frameworks. We establish baselines using frontier models paired with both sequential and parallel scaffolds. Our results show that agents exceed human SOTA in four tasks but fail to match it in sixteen others. Even when agents surpass human benchmarks, they do not reach the theoretical performance ceiling for the underlying tasks. These findings indicate that AIRS-Bench is far from saturated and offers substantial room for improvement. We open-source the AIRS-Bench task definitions and evaluation code to catalyze further development in autonomous scientific research.
A Scalable Measure of Loss Landscape Curvature for Analyzing the Training Dynamics of LLMs
Jan 23, 2026Understanding the curvature evolution of the loss landscape is fundamental to analyzing the training dynamics of neural networks. The most commonly studied measure, Hessian sharpness ($λ_{\max}^H$) -- the largest eigenvalue of the loss Hessian -- determines local training stability and interacts with the learning rate throughout training. Despite its significance in analyzing training dynamics, direct measurement of Hessian sharpness remains prohibitive for Large Language Models (LLMs) due to high computational cost. We analyze $\textit{critical sharpness}$ ($λ_c$), a computationally efficient measure requiring fewer than $10$ forward passes given the update direction $Δ\mathbfθ$. Critically, this measure captures well-documented Hessian sharpness phenomena, including progressive sharpening and Edge of Stability. Using this measure, we provide the first demonstration of these sharpness phenomena at scale, up to $7$B parameters, spanning both pre-training and mid-training of OLMo-2 models. We further introduce $\textit{relative critical sharpness}$ ($λ_c^{1\to 2}$), which quantifies the curvature of one loss landscape while optimizing another, to analyze the transition from pre-training to fine-tuning and guide data mixing strategies. Critical sharpness provides practitioners with a practical tool for diagnosing curvature dynamics and informing data composition choices at scale. More broadly, our work shows that scalable curvature measures can provide actionable insights for large-scale training.
What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity
Nov 19, 2025AI research agents offer the promise to accelerate scientific progress by automating the design, implementation, and training of machine learning models. However, the field is still in its infancy, and the key factors driving the success or failure of agent trajectories are not fully understood. We examine the role that ideation diversity plays in agent performance. First, we analyse agent trajectories on MLE-bench, a well-known benchmark to evaluate AI research agents, across different models and agent scaffolds. Our analysis reveals that different models and agent scaffolds yield varying degrees of ideation diversity, and that higher-performing agents tend to have increased ideation diversity. Further, we run a controlled experiment where we modify the degree of ideation diversity, demonstrating that higher ideation diversity results in stronger performance. Finally, we strengthen our results by examining additional evaluation metrics beyond the standard medal-based scoring of MLE-bench, showing that our findings still hold across other agent performance metrics.
Scaling and Distilling Transformer Models for sEMG
Jul 29, 2025Surface electromyography (sEMG) signals offer a promising avenue for developing innovative human-computer interfaces by providing insights into muscular activity. However, the limited volume of training data and computational constraints during deployment have restricted the investigation of scaling up the model size for solving sEMG tasks. In this paper, we demonstrate that vanilla transformer models can be effectively scaled up on sEMG data and yield improved cross-user performance up to 110M parameters, surpassing the model size regime investigated in other sEMG research (usually <10M parameters). We show that >100M-parameter models can be effectively distilled into models 50x smaller with minimal loss of performance (<1.5% absolute). This results in efficient and expressive models suitable for complex real-time sEMG tasks in real-world environments.
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Jul 03, 2025AI research agents are demonstrating great potential to accelerate scientific progress by automating the design, implementation, and training of machine learning models. We focus on methods for improving agents' performance on MLE-bench, a challenging benchmark where agents compete in Kaggle competitions to solve real-world machine learning problems. We formalize AI research agents as search policies that navigate a space of candidate solutions, iteratively modifying them using operators. By designing and systematically varying different operator sets and search policies (Greedy, MCTS, Evolutionary), we show that their interplay is critical for achieving high performance. Our best pairing of search strategy and operator set achieves a state-of-the-art result on MLE-bench lite, increasing the success rate of achieving a Kaggle medal from 39.6% to 47.7%. Our investigation underscores the importance of jointly considering the search strategy, operator design, and evaluation methodology in advancing automated machine learning.
Response Time Improves Choice Prediction and Function Estimation for Gaussian Process Models of Perception and Preferences
Jun 09, 2023



Models for human choice prediction in preference learning and psychophysics often consider only binary response data, requiring many samples to accurately learn preferences or perceptual detection thresholds. The response time (RT) to make each choice captures additional information about the decision process, however existing models incorporating RTs for choice prediction do so in fully parametric settings or over discrete stimulus sets. This is in part because the de-facto standard model for choice RTs, the diffusion decision model (DDM), does not admit tractable, differentiable inference. The DDM thus cannot be easily integrated with flexible models for continuous, multivariate function approximation, particularly Gaussian process (GP) models. We propose a novel differentiable approximation to the DDM likelihood using a family of known, skewed three-parameter distributions. We then use this new likelihood to incorporate RTs into GP models for binary choices. Our RT-choice GPs enable both better latent value estimation and held-out choice prediction relative to baselines, which we demonstrate on three real-world multivariate datasets covering both human psychophysics and preference learning applications.
Look-Ahead Acquisition Functions for Bernoulli Level Set Estimation
Mar 18, 2022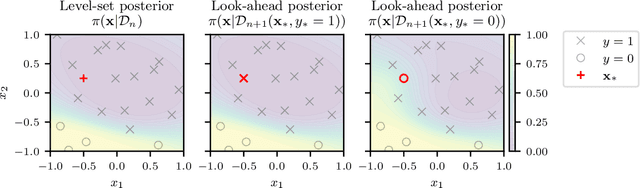
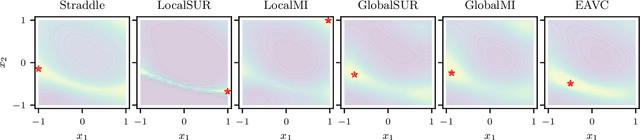
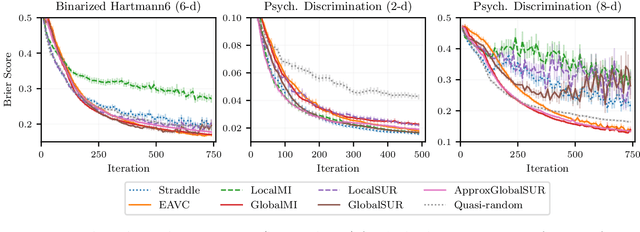

Level set estimation (LSE) is the problem of identifying regions where an unknown function takes values above or below a specified threshold. Active sampling strategies for efficient LSE have primarily been studied in continuous-valued functions. Motivated by applications in human psychophysics where common experimental designs produce binary responses, we study LSE active sampling with Bernoulli outcomes. With Gaussian process classification surrogate models, the look-ahead model posteriors used by state-of-the-art continuous-output methods are intractable. However, we derive analytic expressions for look-ahead posteriors of sublevel set membership, and show how these lead to analytic expressions for a class of look-ahead LSE acquisition functions, including information-based methods. Benchmark experiments show the importance of considering the global look-ahead impact on the entire posterior. We demonstrate a clear benefit to using this new class of acquisition functions on benchmark problems, and on a challenging real-world task of estimating a high-dimensional contrast sensitivity function.
Incorporating structured assumptions with probabilistic graphical models in fMRI data analysis
May 29, 2020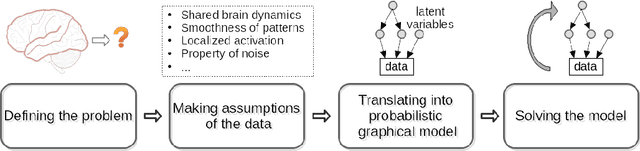
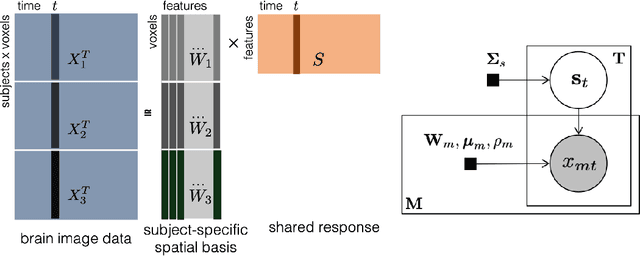
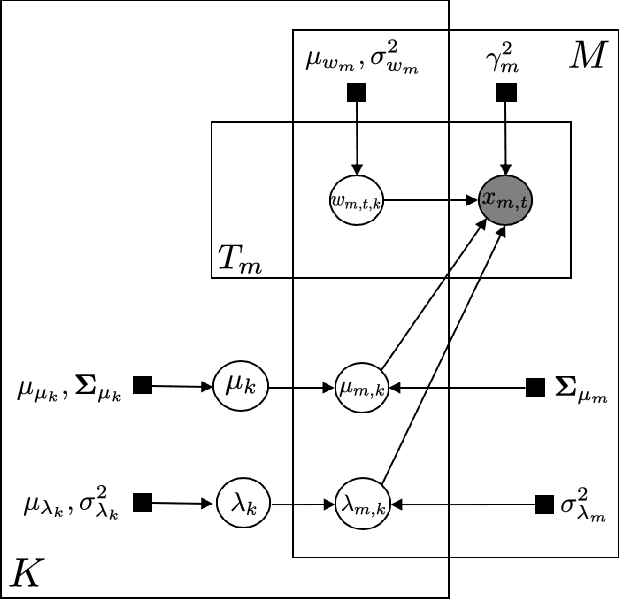
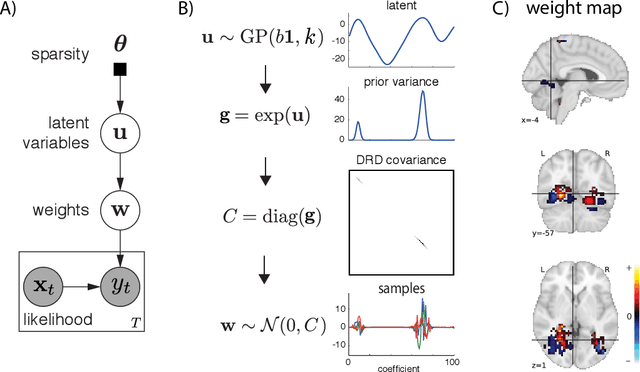
With the wide adoption of functional magnetic resonance imaging (fMRI) by cognitive neuroscience researchers, large volumes of brain imaging data have been accumulated in recent years. Aggregating these data to derive scientific insights often faces the challenge that fMRI data are high-dimensional, heterogeneous across people, and noisy. These challenges demand the development of computational tools that are tailored both for the neuroscience questions and for the properties of the data. We review a few recently developed algorithms in various domains of fMRI research: fMRI in naturalistic tasks, analyzing full-brain functional connectivity, pattern classification, inferring representational similarity and modeling structured residuals. These algorithms all tackle the challenges in fMRI similarly: they start by making clear statements of assumptions about neural data and existing domain knowledge, incorporating those assumptions and domain knowledge into probabilistic graphical models, and using those models to estimate properties of interest or latent structures in the data. Such approaches can avoid erroneous findings, reduce the impact of noise, better utilize known properties of the data, and better aggregate data across groups of subjects. With these successful cases, we advocate wider adoption of explicit model construction in cognitive neuroscience. Although we focus on fMRI, the principle illustrated here is generally applicable to brain data of other modalities.
* update with the version accepted by Neuropsychologia