 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Likelihood Variational Gaussian Processes
Mar 06, 2025Gaussian processes (GPs) are powerful models for human-in-the-loop experiments due to their flexibility and well-calibrated uncertainty. However, GPs modeling human responses typically ignore auxiliary information, including a priori domain expertise and non-task performance information like user confidence ratings. We propose mixed likelihood variational GPs to leverage auxiliary information, which combine multiple likelihoods in a single evidence lower bound to model multiple types of data. We demonstrate the benefits of mixing likelihoods in three real-world experiments with human participants. First, we use mixed likelihood training to impose prior knowledge constraints in GP classifiers, which accelerates active learning in a visual perception task where users are asked to identify geometric errors resulting from camera position errors in virtual reality. Second, we show that leveraging Likert scale confidence ratings by mixed likelihood training improves model fitting for haptic perception of surface roughness. Lastly, we show that Likert scale confidence ratings improve human preference learning in robot gait optimization. The modeling performance improvements found using our framework across this diverse set of applications illustrates the benefits of incorporating auxiliary information into active learning and preference learning by using mixed likelihoods to jointly model multiple inputs.
Active Learning for Derivative-Based Global Sensitivity Analysis with Gaussian Processes
Jul 13, 2024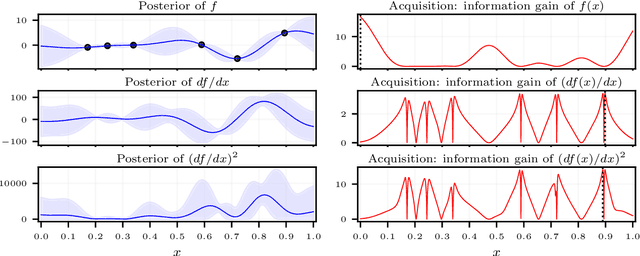
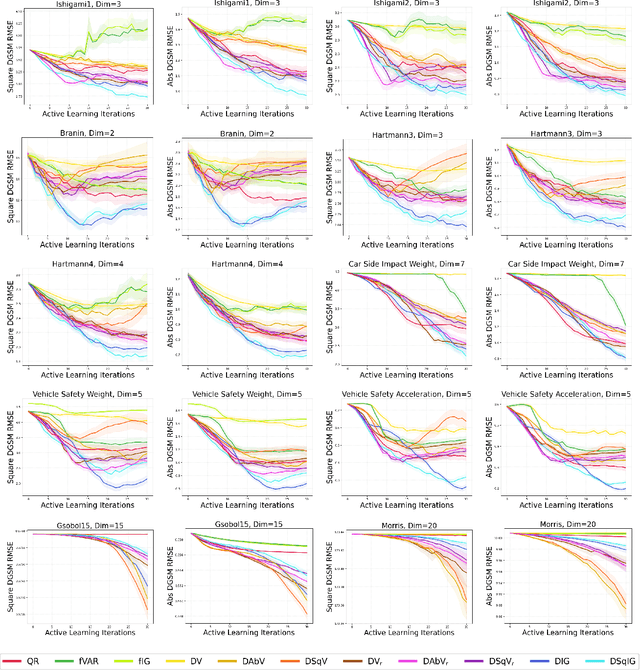
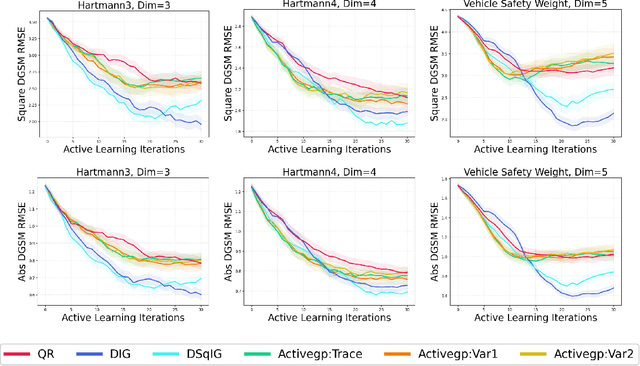
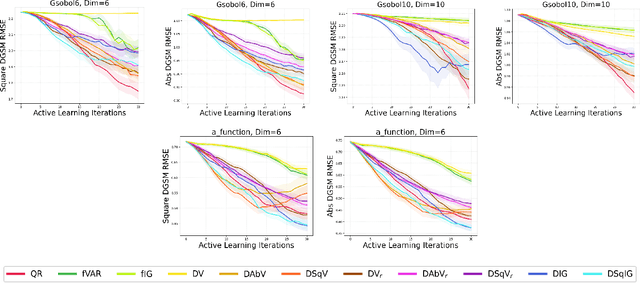
We consider the problem of active learning for global sensitivity analysis of expensive black-box functions. Our aim is to efficiently learn the importance of different input variables, e.g., in vehicle safety experimentation, we study the impact of the thickness of various components on safety objectives. Since function evaluations are expensive, we use active learning to prioritize experimental resources where they yield the most value. We propose novel active learning acquisition functions that directly target key quantities of derivative-based global sensitivity measures (DGSMs) under Gaussian process surrogate models. We showcase the first application of active learning directly to DGSMs, and develop tractable uncertainty reduction and information gain acquisition functions for these measures. Through comprehensive evaluation on synthetic and real-world problems, our study demonstrates how these active learning acquisition strategies substantially enhance the sample efficiency of DGSM estimation, particularly with limited evaluation budgets. Our work paves the way for more efficient and accurate sensitivity analysis in various scientific and engineering applications.
Response Time Improves Choice Prediction and Function Estimation for Gaussian Process Models of Perception and Preferences
Jun 09, 2023



Models for human choice prediction in preference learning and psychophysics often consider only binary response data, requiring many samples to accurately learn preferences or perceptual detection thresholds. The response time (RT) to make each choice captures additional information about the decision process, however existing models incorporating RTs for choice prediction do so in fully parametric settings or over discrete stimulus sets. This is in part because the de-facto standard model for choice RTs, the diffusion decision model (DDM), does not admit tractable, differentiable inference. The DDM thus cannot be easily integrated with flexible models for continuous, multivariate function approximation, particularly Gaussian process (GP) models. We propose a novel differentiable approximation to the DDM likelihood using a family of known, skewed three-parameter distributions. We then use this new likelihood to incorporate RTs into GP models for binary choices. Our RT-choice GPs enable both better latent value estimation and held-out choice prediction relative to baselines, which we demonstrate on three real-world multivariate datasets covering both human psychophysics and preference learning applications.
Look-Ahead Acquisition Functions for Bernoulli Level Set Estimation
Mar 18, 2022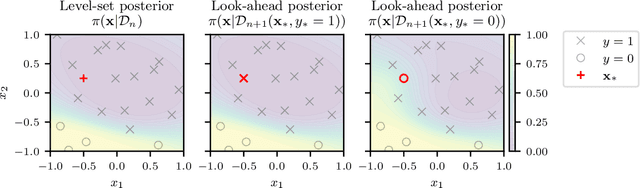
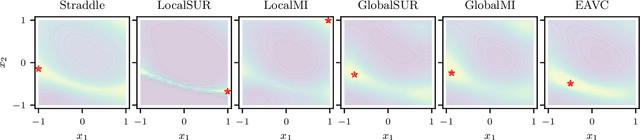

Level set estimation (LSE) is the problem of identifying regions where an unknown function takes values above or below a specified threshold. Active sampling strategies for efficient LSE have primarily been studied in continuous-valued functions. Motivated by applications in human psychophysics where common experimental designs produce binary responses, we study LSE active sampling with Bernoulli outcomes. With Gaussian process classification surrogate models, the look-ahead model posteriors used by state-of-the-art continuous-output methods are intractable. However, we derive analytic expressions for look-ahead posteriors of sublevel set membership, and show how these lead to analytic expressions for a class of look-ahead LSE acquisition functions, including information-based methods. Benchmark experiments show the importance of considering the global look-ahead impact on the entire posterior. We demonstrate a clear benefit to using this new class of acquisition functions on benchmark problems, and on a challenging real-world task of estimating a high-dimensional contrast sensitivity function.
Sparse Bayesian Optimization
Mar 03, 2022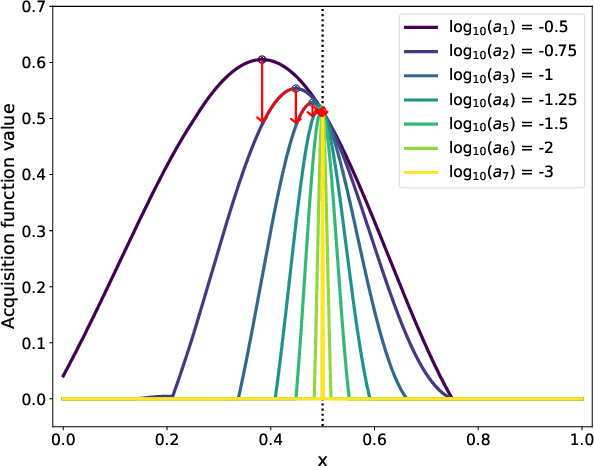
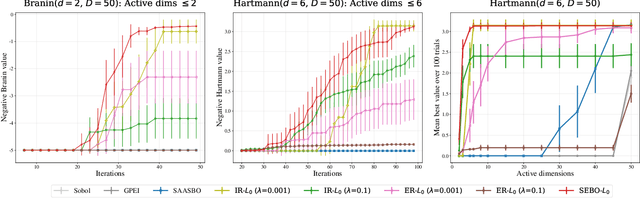
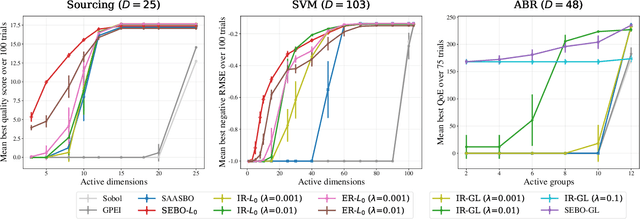
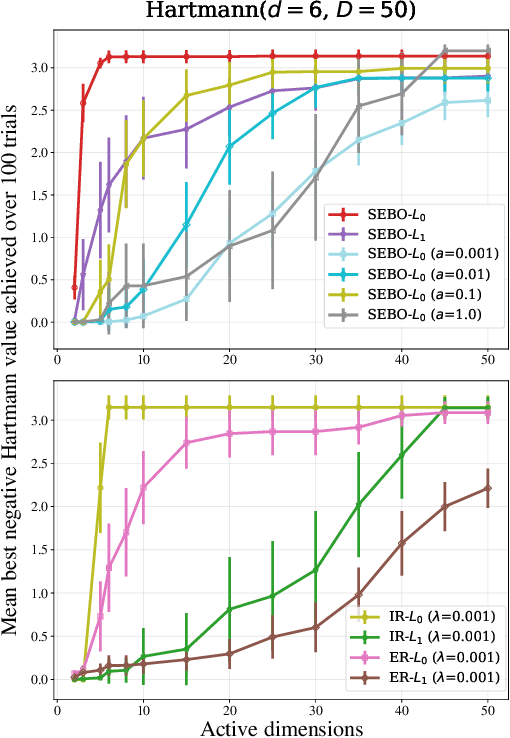
Bayesian optimization (BO) is a powerful approach to sample-efficient optimization of black-box objective functions. However, the application of BO to areas such as recommendation systems often requires taking the interpretability and simplicity of the configurations into consideration, a setting that has not been previously studied in the BO literature. To make BO applicable in this setting, we present several regularization-based approaches that allow us to discover sparse and more interpretable configurations. We propose a novel differentiable relaxation based on homotopy continuation that makes it possible to target sparsity by working directly with $L_0$ regularization. We identify failure modes for regularized BO and develop a hyperparameter-free method, sparsity exploring Bayesian optimization (SEBO) that seeks to simultaneously maximize a target objective and sparsity. SEBO and methods based on fixed regularization are evaluated on synthetic and real-world problems, and we show that we are able to efficiently optimize for sparsity.
Re-Examining Linear Embeddings for High-Dimensional Bayesian Optimization
Jan 31, 2020



Bayesian optimization (BO) is a popular approach to optimize expensive-to-evaluate black-box functions. A significant challenge in BO is to scale to high-dimensional parameter spaces while retaining sample efficiency. A solution considered in existing literature is to embed the high-dimensional space in a lower-dimensional manifold, often via a random linear embedding. In this paper, we identify several crucial issues and misconceptions about the use of linear embeddings for BO. We study the properties of linear embeddings from the literature and show that some of the design choices in current approaches adversely impact their performance. We show empirically that properly addressing these issues significantly improves the efficacy of linear embeddings for BO on a range of problems, including learning a gait policy for robot locomotion.
BoTorch: Programmable Bayesian Optimization in PyTorch
Oct 14, 2019

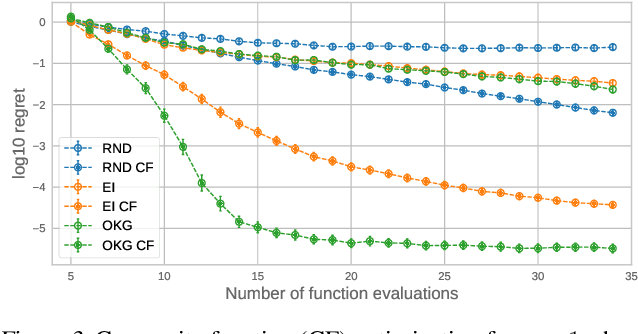
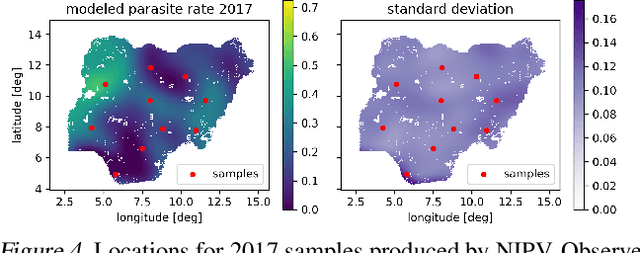
Bayesian optimization provides sample-efficient global optimization for a broad range of applications, including automatic machine learning, molecular chemistry, and experimental design. We introduce BoTorch, a modern programming framework for Bayesian optimization. Enabled by Monte-Carlo (MC) acquisition functions and auto-differentiation, BoTorch's modular design facilitates flexible specification and optimization of probabilistic models written in PyTorch, radically simplifying implementation of novel acquisition functions. Our MC approach is made practical by a distinctive algorithmic foundation that leverages fast predictive distributions and hardware acceleration. In experiments, we demonstrate the improved sample efficiency of BoTorch relative to other popular libraries. BoTorch is open source and available at https://github.com/pytorch/botorch.
Bayesian Optimization for Policy Search via Online-Offline Experimentation
Apr 29, 2019
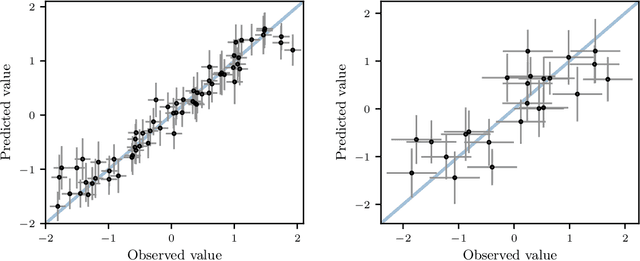

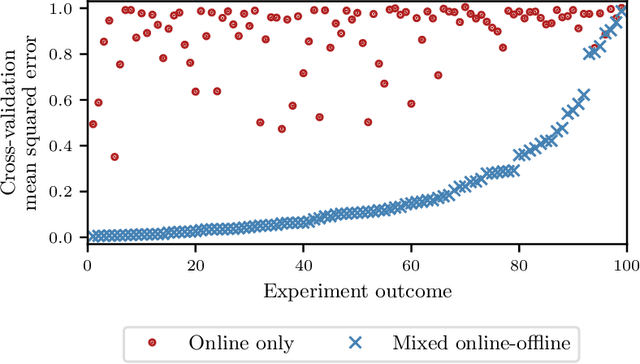
Online field experiments are the gold-standard way of evaluating changes to real-world interactive machine learning systems. Yet our ability to explore complex, multi-dimensional policy spaces - such as those found in recommendation and ranking problems - is often constrained by the limited number of experiments that can be run simultaneously. To alleviate these constraints, we augment online experiments with an offline simulator and apply multi-task Bayesian optimization to tune live machine learning systems. We describe practical issues that arise in these types of applications, including biases that arise from using a simulator and assumptions for the multi-task kernel. We measure empirical learning curves which show substantial gains from including data from biased offline experiments, and show how these learning curves are consistent with theoretical results for multi-task Gaussian process generalization. We find that improved kernel inference is a significant driver of multi-task generalization. Finally, we show several examples of Bayesian optimization efficiently tuning a live machine learning system by combining offline and online experiments.
Constrained Bayesian Optimization with Noisy Experiments
Jun 26, 2018
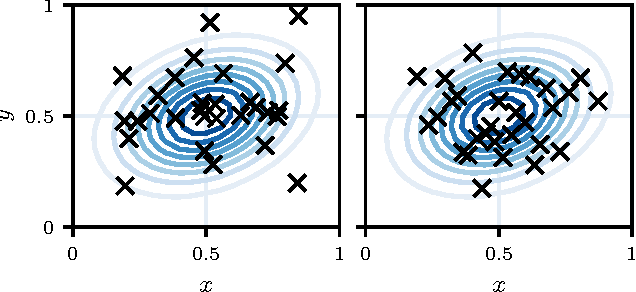
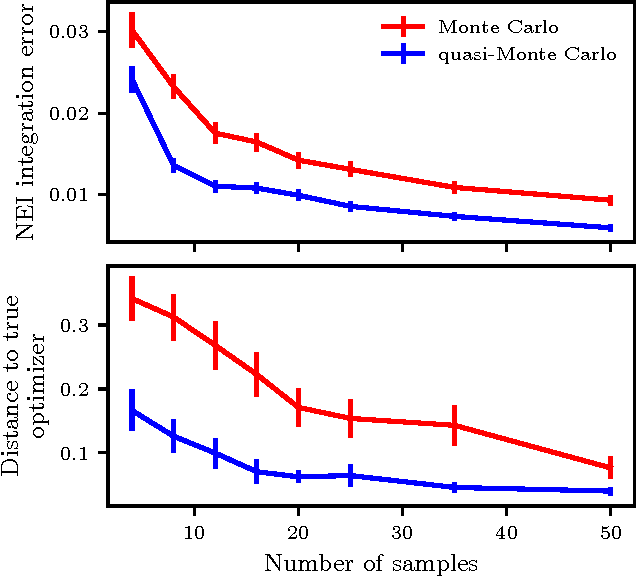
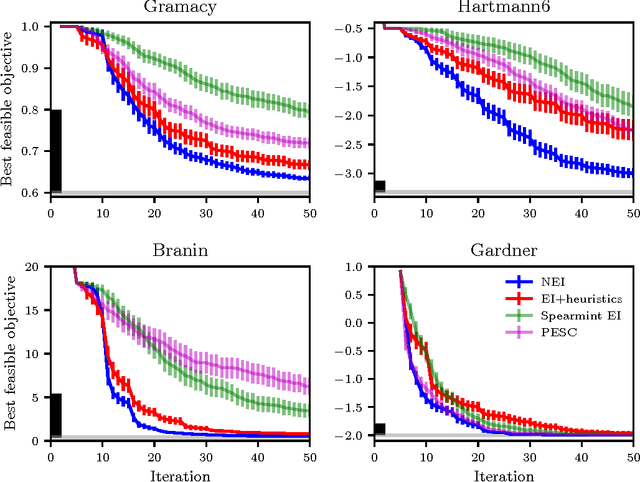
Randomized experiments are the gold standard for evaluating the effects of changes to real-world systems. Data in these tests may be difficult to collect and outcomes may have high variance, resulting in potentially large measurement error. Bayesian optimization is a promising technique for efficiently optimizing multiple continuous parameters, but existing approaches degrade in performance when the noise level is high, limiting its applicability to many randomized experiments. We derive an expression for expected improvement under greedy batch optimization with noisy observations and noisy constraints, and develop a quasi-Monte Carlo approximation that allows it to be efficiently optimized. Simulations with synthetic functions show that optimization performance on noisy, constrained problems outperforms existing methods. We further demonstrate the effectiveness of the method with two real-world experiments conducted at Facebook: optimizing a ranking system, and optimizing server compiler flags.
Scalable Meta-Learning for Bayesian Optimization
Feb 06, 2018



Bayesian optimization has become a standard technique for hyperparameter optimization, including data-intensive models such as deep neural networks that may take days or weeks to train. We consider the setting where previous optimization runs are available, and we wish to use their results to warm-start a new optimization run. We develop an ensemble model that can incorporate the results of past optimization runs, while avoiding the poor scaling that comes with putting all results into a single Gaussian process model. The ensemble combines models from past runs according to estimates of their generalization performance on the current optimization. Results from a large collection of hyperparameter optimization benchmark problems and from optimization of a production computer vision platform at Facebook show that the ensemble can substantially reduce the time it takes to obtain near-optimal configurations, and is useful for warm-starting expensive searches or running quick re-optimizations.