 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBONSAI: Bayesian Optimization with Natural Simplicity and Interpretability
Feb 06, 2026Bayesian optimization (BO) is a popular technique for sample-efficient optimization of black-box functions. In many applications, the parameters being tuned come with a carefully engineered default configuration, and practitioners only want to deviate from this default when necessary. Standard BO, however, does not aim to minimize deviation from the default and, in practice, often pushes weakly relevant parameters to the boundary of the search space. This makes it difficult to distinguish between important and spurious changes and increases the burden of vetting recommendations when the optimization objective omits relevant operational considerations. We introduce BONSAI, a default-aware BO policy that prunes low-impact deviations from a default configuration while explicitly controlling the loss in acquisition value. BONSAI is compatible with a variety of acquisition functions, including expected improvement and upper confidence bound (GP-UCB). We theoretically bound the regret incurred by BONSAI, showing that, under certain conditions, it enjoys the same no-regret property as vanilla GP-UCB. Across many real-world applications, we empirically find that BONSAI substantially reduces the number of non-default parameters in recommended configurations while maintaining competitive optimization performance, with little effect on wall time.
Bayesian Optimization of Function Networks with Partial Evaluations
Nov 03, 2023
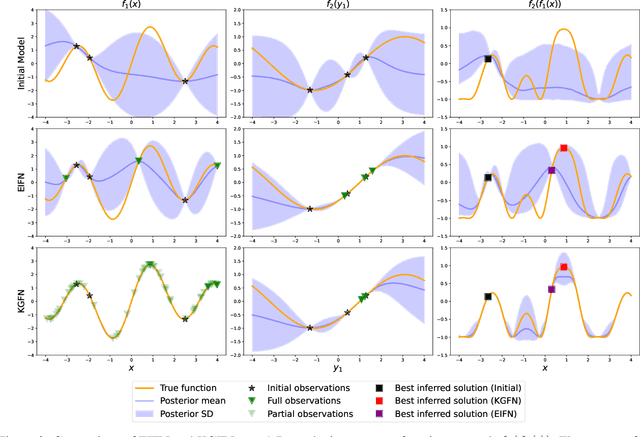

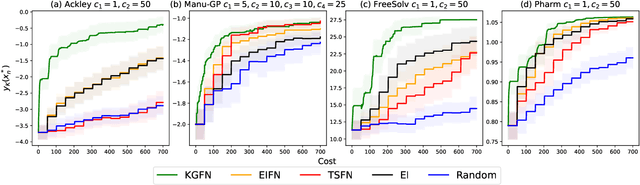
Bayesian optimization is a framework for optimizing functions that are costly or time-consuming to evaluate. Recent work has considered Bayesian optimization of function networks (BOFN), where the objective function is computed via a network of functions, each taking as input the output of previous nodes in the network and additional parameters. Exploiting this network structure has been shown to yield significant performance improvements. Existing BOFN algorithms for general-purpose networks are required to evaluate the full network at each iteration. However, many real-world applications allow evaluating nodes individually. To take advantage of this opportunity, we propose a novel knowledge gradient acquisition function for BOFN that chooses which node to evaluate as well as the inputs for that node in a cost-aware fashion. This approach can dramatically reduce query costs by allowing the evaluation of part of the network at a lower cost relative to evaluating the entire network. We provide an efficient approach to optimizing our acquisition function and show it outperforms existing BOFN methods and other benchmarks across several synthetic and real-world problems. Our acquisition function is the first to enable cost-aware optimization of a broad class of function networks.
Unexpected Improvements to Expected Improvement for Bayesian Optimization
Oct 31, 2023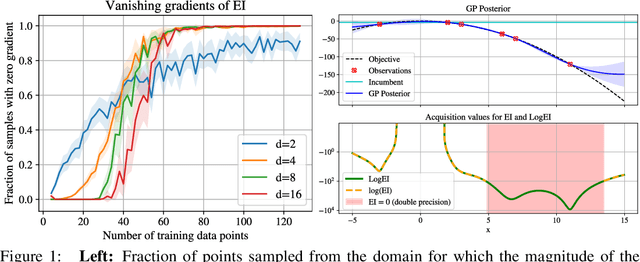

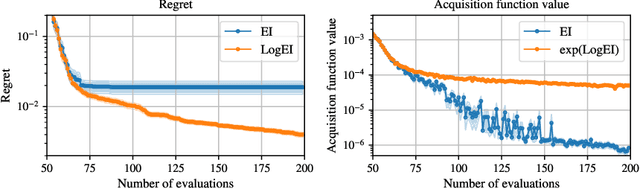
Expected Improvement (EI) is arguably the most popular acquisition function in Bayesian optimization and has found countless successful applications, but its performance is often exceeded by that of more recent methods. Notably, EI and its variants, including for the parallel and multi-objective settings, are challenging to optimize because their acquisition values vanish numerically in many regions. This difficulty generally increases as the number of observations, dimensionality of the search space, or the number of constraints grow, resulting in performance that is inconsistent across the literature and most often sub-optimal. Herein, we propose LogEI, a new family of acquisition functions whose members either have identical or approximately equal optima as their canonical counterparts, but are substantially easier to optimize numerically. We demonstrate that numerical pathologies manifest themselves in "classic" analytic EI, Expected Hypervolume Improvement (EHVI), as well as their constrained, noisy, and parallel variants, and propose corresponding reformulations that remedy these pathologies. Our empirical results show that members of the LogEI family of acquisition functions substantially improve on the optimization performance of their canonical counterparts and surprisingly, are on par with or exceed the performance of recent state-of-the-art acquisition functions, highlighting the understated role of numerical optimization in the literature.
Bayesian Optimization over Discrete and Mixed Spaces via Probabilistic Reparameterization
Oct 18, 2022
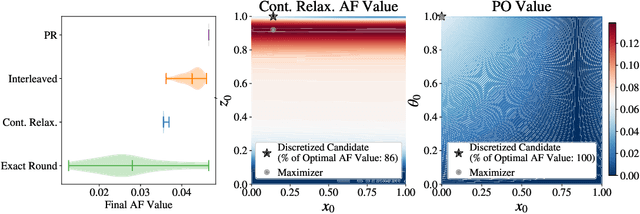

Optimizing expensive-to-evaluate black-box functions of discrete (and potentially continuous) design parameters is a ubiquitous problem in scientific and engineering applications. Bayesian optimization (BO) is a popular, sample-efficient method that leverages a probabilistic surrogate model and an acquisition function (AF) to select promising designs to evaluate. However, maximizing the AF over mixed or high-cardinality discrete search spaces is challenging standard gradient-based methods cannot be used directly or evaluating the AF at every point in the search space would be computationally prohibitive. To address this issue, we propose using probabilistic reparameterization (PR). Instead of directly optimizing the AF over the search space containing discrete parameters, we instead maximize the expectation of the AF over a probability distribution defined by continuous parameters. We prove that under suitable reparameterizations, the BO policy that maximizes the probabilistic objective is the same as that which maximizes the AF, and therefore, PR enjoys the same regret bounds as the original BO policy using the underlying AF. Moreover, our approach provably converges to a stationary point of the probabilistic objective under gradient ascent using scalable, unbiased estimators of both the probabilistic objective and its gradient. Therefore, as the number of starting points and gradient steps increase, our approach will recover of a maximizer of the AF (an often-neglected requisite for commonly used BO regret bounds). We validate our approach empirically and demonstrate state-of-the-art optimization performance on a wide range of real-world applications. PR is complementary to (and benefits) recent work and naturally generalizes to settings with multiple objectives and black-box constraints.
Log-Linear-Time Gaussian Processes Using Binary Tree Kernels
Oct 04, 2022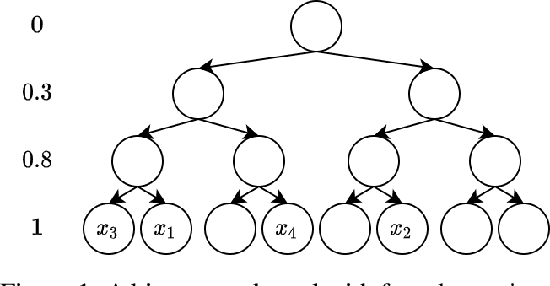
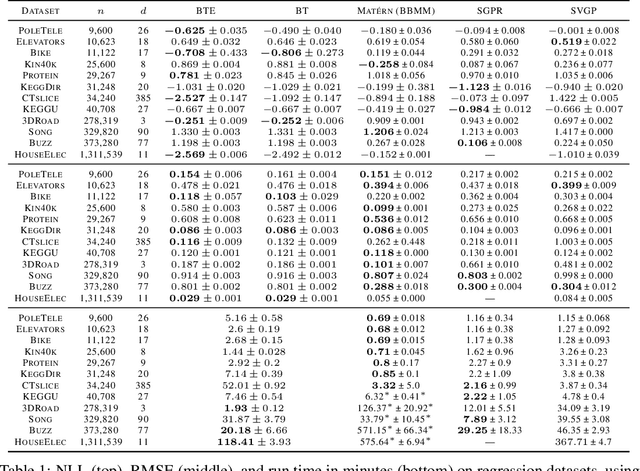
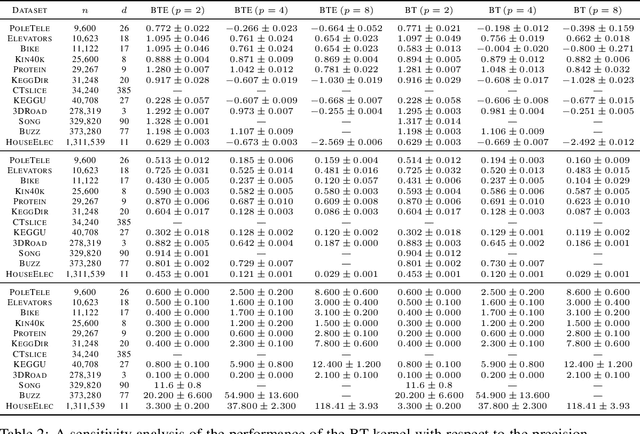
Gaussian processes (GPs) produce good probabilistic models of functions, but most GP kernels require $O((n+m)n^2)$ time, where $n$ is the number of data points and $m$ the number of predictive locations. We present a new kernel that allows for Gaussian process regression in $O((n+m)\log(n+m))$ time. Our "binary tree" kernel places all data points on the leaves of a binary tree, with the kernel depending only on the depth of the deepest common ancestor. We can store the resulting kernel matrix in $O(n)$ space in $O(n \log n)$ time, as a sum of sparse rank-one matrices, and approximately invert the kernel matrix in $O(n)$ time. Sparse GP methods also offer linear run time, but they predict less well than higher dimensional kernels. On a classic suite of regression tasks, we compare our kernel against Mat\'ern, sparse, and sparse variational kernels. The binary tree GP assigns the highest likelihood to the test data on a plurality of datasets, usually achieves lower mean squared error than the sparse methods, and often ties or beats the Mat\'ern GP. On large datasets, the binary tree GP is fastest, and much faster than a Mat\'ern GP.
Robust Multi-Objective Bayesian Optimization Under Input Noise
Feb 16, 2022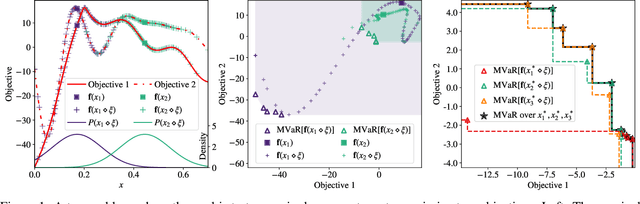
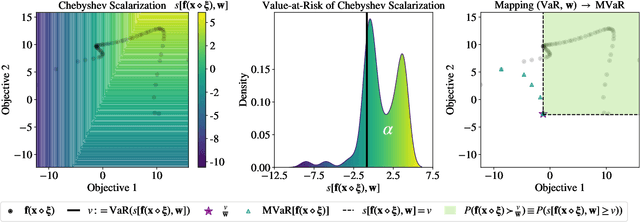
Bayesian optimization (BO) is a sample-efficient approach for tuning design parameters to optimize expensive-to-evaluate, black-box performance metrics. In many manufacturing processes, the design parameters are subject to random input noise, resulting in a product that is often less performant than expected. Although BO methods have been proposed for optimizing a single objective under input noise, no existing method addresses the practical scenario where there are multiple objectives that are sensitive to input perturbations. In this work, we propose the first multi-objective BO method that is robust to input noise. We formalize our goal as optimizing the multivariate value-at-risk (MVaR), a risk measure of the uncertain objectives. Since directly optimizing MVaR is computationally infeasible in many settings, we propose a scalable, theoretically-grounded approach for optimizing MVaR using random scalarizations. Empirically, we find that our approach significantly outperforms alternative methods and efficiently identifies optimal robust designs that will satisfy specifications across multiple metrics with high probability.
Multi-Objective Bayesian Optimization over High-Dimensional Search Spaces
Sep 22, 2021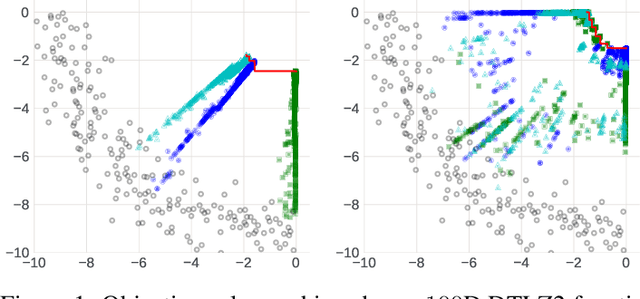

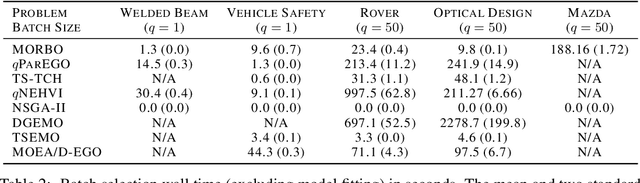
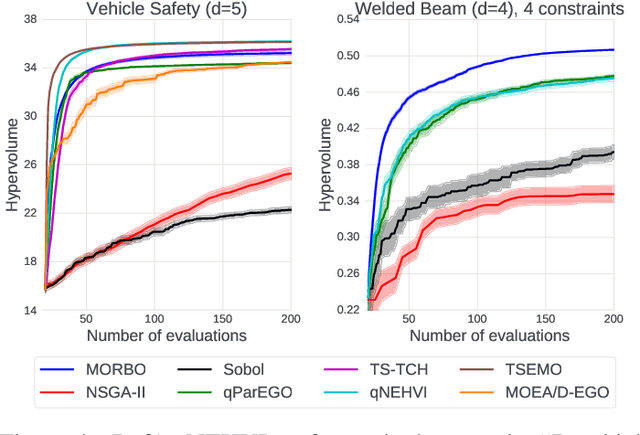
The ability to optimize multiple competing objective functions with high sample efficiency is imperative in many applied problems across science and industry. Multi-objective Bayesian optimization (BO) achieves strong empirical performance on such problems, but even with recent methodological advances, it has been restricted to simple, low-dimensional domains. Most existing BO methods exhibit poor performance on search spaces with more than a few dozen parameters. In this work we propose MORBO, a method for multi-objective Bayesian optimization over high-dimensional search spaces. MORBO performs local Bayesian optimization within multiple trust regions simultaneously, allowing it to explore and identify diverse solutions even when the objective functions are difficult to model globally. We show that MORBO significantly advances the state-of-the-art in sample-efficiency for several high-dimensional synthetic and real-world multi-objective problems, including a vehicle design problem with 222 parameters, demonstrating that MORBO is a practical approach for challenging and important problems that were previously out of reach for BO methods.
Latency-Aware Neural Architecture Search with Multi-Objective Bayesian Optimization
Jun 25, 2021

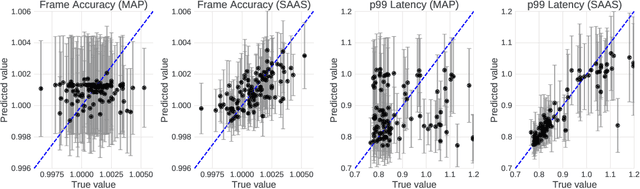
When tuning the architecture and hyperparameters of large machine learning models for on-device deployment, it is desirable to understand the optimal trade-offs between on-device latency and model accuracy. In this work, we leverage recent methodological advances in Bayesian optimization over high-dimensional search spaces and multi-objective Bayesian optimization to efficiently explore these trade-offs for a production-scale on-device natural language understanding model at Facebook.
Parallel Bayesian Optimization of Multiple Noisy Objectives with Expected Hypervolume Improvement
May 17, 2021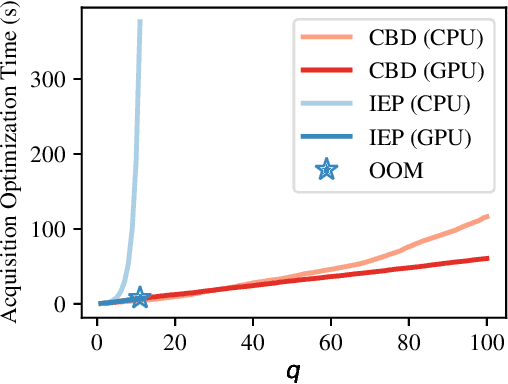
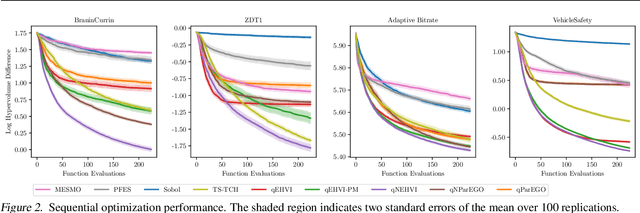

Optimizing multiple competing black-box objectives is a challenging problem in many fields, including science, engineering, and machine learning. Multi-objective Bayesian optimization is a powerful approach for identifying the optimal trade-offs between the objectives with very few function evaluations. However, existing methods tend to perform poorly when observations are corrupted by noise, as they do not take into account uncertainty in the true Pareto frontier over the previously evaluated designs. We propose a novel acquisition function, NEHVI, that overcomes this important practical limitation by applying a Bayesian treatment to the popular expected hypervolume improvement criterion to integrate over this uncertainty in the Pareto frontier. We further argue that, even in the noiseless setting, the problem of generating multiple candidates in parallel reduces that of handling uncertainty in the Pareto frontier. Through this lens, we derive a natural parallel variant of NEHVI that can efficiently generate large batches of candidates. We provide a theoretical convergence guarantee for optimizing a Monte Carlo estimator of NEHVI using exact sample-path gradients. Empirically, we show that NEHVI achieves state-of-the-art performance in noisy and large-batch environments.
Distilled Thompson Sampling: Practical and Efficient Thompson Sampling via Imitation Learning
Dec 08, 2020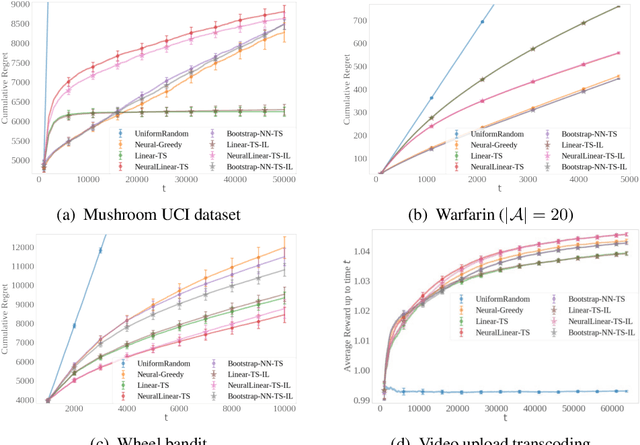
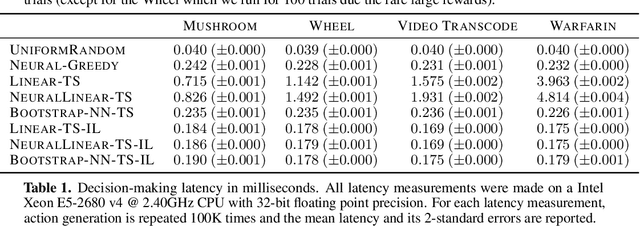
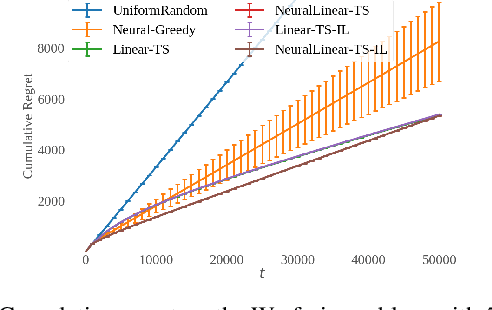

Thompson sampling (TS) has emerged as a robust technique for contextual bandit problems. However, TS requires posterior inference and optimization for action generation, prohibiting its use in many internet applications where latency and ease of deployment are of concern. We propose a novel imitation-learning-based algorithm that distills a TS policy into an explicit policy representation by performing posterior inference and optimization offline. The explicit policy representation enables fast online decision-making and easy deployment in mobile and server-based environments. Our algorithm iteratively performs offline batch updates to the TS policy and learns a new imitation policy. Since we update the TS policy with observations collected under the imitation policy, our algorithm emulates an off-policy version of TS. Our imitation algorithm guarantees Bayes regret comparable to TS, up to the sum of single-step imitation errors. We show these imitation errors can be made arbitrarily small when unlabeled contexts are cheaply available, which is the case for most large-scale internet applications. Empirically, we show that our imitation policy achieves comparable regret to TS, while reducing decision-time latency by over an order of magnitude.