 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Simulation Experiment for LLM Policy Optimization
Apr 09, 2026Large language models (LLMs) have significant potential to improve operational efficiency in operations management. Deploying these models requires specifying a policy that governs response quality, shapes user experience, and influences operational value. In this research, we treat LLMs as stochastic simulators and propose a pairwise comparison-based adaptive simulation experiment framework for identifying the optimal policy from a finite set of candidates. We consider two policy spaces: an unstructured space with no parametric assumption, and a structured space in which the data are generated from a preference model. For both settings, we characterize the fundamental data requirements for identifying the optimal policy with high probability. In the unstructured case, we derive a closed-form expression for the optimal sampling proportions, together with a clear operational interpretation. In the structured case, we formulate a regularized convex program to compute the optimal proportions. We then develop an adaptive experimental procedure, termed LLM-PO, for both policy spaces, and prove that it identifies the optimal policy with the desired statistical guarantee while asymptotically attaining the fundamental data requirements. Numerical experiments demonstrate that LLM-PO consistently outperforms benchmark methods and improves LLM performance.
Pragmatic Curiosity: A Hybrid Learning-Optimization Paradigm via Active Inference
Feb 05, 2026Many engineering and scientific workflows depend on expensive black-box evaluations, requiring decision-making that simultaneously improves performance and reduces uncertainty. Bayesian optimization (BO) and Bayesian experimental design (BED) offer powerful yet largely separate treatments of goal-seeking and information-seeking, providing limited guidance for hybrid settings where learning and optimization are intrinsically coupled. We propose "pragmatic curiosity," a hybrid learning-optimization paradigm derived from active inference, in which actions are selected by minimizing the expected free energy--a single objective that couples pragmatic utility with epistemic information gain. We demonstrate the practical effectiveness and flexibility of pragmatic curiosity on various real-world hybrid tasks, including constrained system identification, targeted active search, and composite optimization with unknown preferences. Across these benchmarks, pragmatic curiosity consistently outperforms strong BO-type and BED-type baselines, delivering higher estimation accuracy, better critical-region coverage, and improved final solution quality.
Curiosity is Knowledge: Self-Consistent Learning and No-Regret Optimization with Active Inference
Feb 05, 2026Active inference (AIF) unifies exploration and exploitation by minimizing the Expected Free Energy (EFE), balancing epistemic value (information gain) and pragmatic value (task performance) through a curiosity coefficient. Yet it has been unclear when this balance yields both coherent learning and efficient decision-making: insufficient curiosity can drive myopic exploitation and prevent uncertainty resolution, while excessive curiosity can induce unnecessary exploration and regret. We establish the first theoretical guarantee for EFE-minimizing agents, showing that a single requirement--sufficient curiosity--simultaneously ensures self-consistent learning (Bayesian posterior consistency) and no-regret optimization (bounded cumulative regret). Our analysis characterizes how this mechanism depends on initial uncertainty, identifiability, and objective alignment, thereby connecting AIF to classical Bayesian experimental design and Bayesian optimization within one theoretical framework. We further translate these theories into practical design guidelines for tuning the epistemic-pragmatic trade-off in hybrid learning-optimization problems, validated through real-world experiments.
Policy Gradient Optimzation for Bayesian-Risk MDPs with General Convex Losses
Sep 19, 2025Motivated by many application problems, we consider Markov decision processes (MDPs) with a general loss function and unknown parameters. To mitigate the epistemic uncertainty associated with unknown parameters, we take a Bayesian approach to estimate the parameters from data and impose a coherent risk functional (with respect to the Bayesian posterior distribution) on the loss. Since this formulation usually does not satisfy the interchangeability principle, it does not admit Bellman equations and cannot be solved by approaches based on dynamic programming. Therefore, We propose a policy gradient optimization method, leveraging the dual representation of coherent risk measures and extending the envelope theorem to continuous cases. We then show the stationary analysis of the algorithm with a convergence rate of $O(T^{-1/2}+r^{-1/2})$, where $T$ is the number of policy gradient iterations and $r$ is the sample size of the gradient estimator. We further extend our algorithm to an episodic setting, and establish the global convergence of the extended algorithm and provide bounds on the number of iterations needed to achieve an error bound $O(\epsilon)$ in each episode.
Online Bayesian Risk-Averse Reinforcement Learning
Sep 17, 2025In this paper, we study the Bayesian risk-averse formulation in reinforcement learning (RL). To address the epistemic uncertainty due to a lack of data, we adopt the Bayesian Risk Markov Decision Process (BRMDP) to account for the parameter uncertainty of the unknown underlying model. We derive the asymptotic normality that characterizes the difference between the Bayesian risk value function and the original value function under the true unknown distribution. The results indicate that the Bayesian risk-averse approach tends to pessimistically underestimate the original value function. This discrepancy increases with stronger risk aversion and decreases as more data become available. We then utilize this adaptive property in the setting of online RL as well as online contextual multi-arm bandits (CMAB), a special case of online RL. We provide two procedures using posterior sampling for both the general RL problem and the CMAB problem. We establish a sub-linear regret bound, with the regret defined as the conventional regret for both the RL and CMAB settings. Additionally, we establish a sub-linear regret bound for the CMAB setting with the regret defined as the Bayesian risk regret. Finally, we conduct numerical experiments to demonstrate the effectiveness of the proposed algorithm in addressing epistemic uncertainty and verifying the theoretical properties.
Ranking and Selection with Simultaneous Input Data Collection
Mar 14, 2025In this paper, we propose a general and novel formulation of ranking and selection with the existence of streaming input data. The collection of multiple streams of such data may consume different types of resources, and hence can be conducted simultaneously. To utilize the streaming input data, we aggregate simulation outputs generated under heterogeneous input distributions over time to form a performance estimator. By characterizing the asymptotic behavior of the performance estimators, we formulate two optimization problems to optimally allocate budgets for collecting input data and running simulations. We then develop a multi-stage simultaneous budget allocation procedure and provide its statistical guarantees such as consistency and asymptotic normality. We conduct several numerical studies to demonstrate the competitive performance of the proposed procedure.
Reusing Historical Trajectories in Natural Policy Gradient via Importance Sampling: Convergence and Convergence Rate
Mar 01, 2024



Reinforcement learning provides a mathematical framework for learning-based control, whose success largely depends on the amount of data it can utilize. The efficient utilization of historical trajectories obtained from previous policies is essential for expediting policy optimization. Empirical evidence has shown that policy gradient methods based on importance sampling work well. However, existing literature often neglect the interdependence between trajectories from different iterations, and the good empirical performance lacks a rigorous theoretical justification. In this paper, we study a variant of the natural policy gradient method with reusing historical trajectories via importance sampling. We show that the bias of the proposed estimator of the gradient is asymptotically negligible, the resultant algorithm is convergent, and reusing past trajectories helps improve the convergence rate. We further apply the proposed estimator to popular policy optimization algorithms such as trust region policy optimization. Our theoretical results are verified on classical benchmarks.
Bayesian Risk-Averse Q-Learning with Streaming Observations
May 18, 2023We consider a robust reinforcement learning problem, where a learning agent learns from a simulated training environment. To account for the model mis-specification between this training environment and the real environment due to lack of data, we adopt a formulation of Bayesian risk MDP (BRMDP) with infinite horizon, which uses Bayesian posterior to estimate the transition model and impose a risk functional to account for the model uncertainty. Observations from the real environment that is out of the agent's control arrive periodically and are utilized by the agent to update the Bayesian posterior to reduce model uncertainty. We theoretically demonstrate that BRMDP balances the trade-off between robustness and conservativeness, and we further develop a multi-stage Bayesian risk-averse Q-learning algorithm to solve BRMDP with streaming observations from real environment. The proposed algorithm learns a risk-averse yet optimal policy that depends on the availability of real-world observations. We provide a theoretical guarantee of strong convergence for the proposed algorithm.
Risk-averse Contextual Multi-armed Bandit Problem with Linear Payoffs
Jun 24, 2022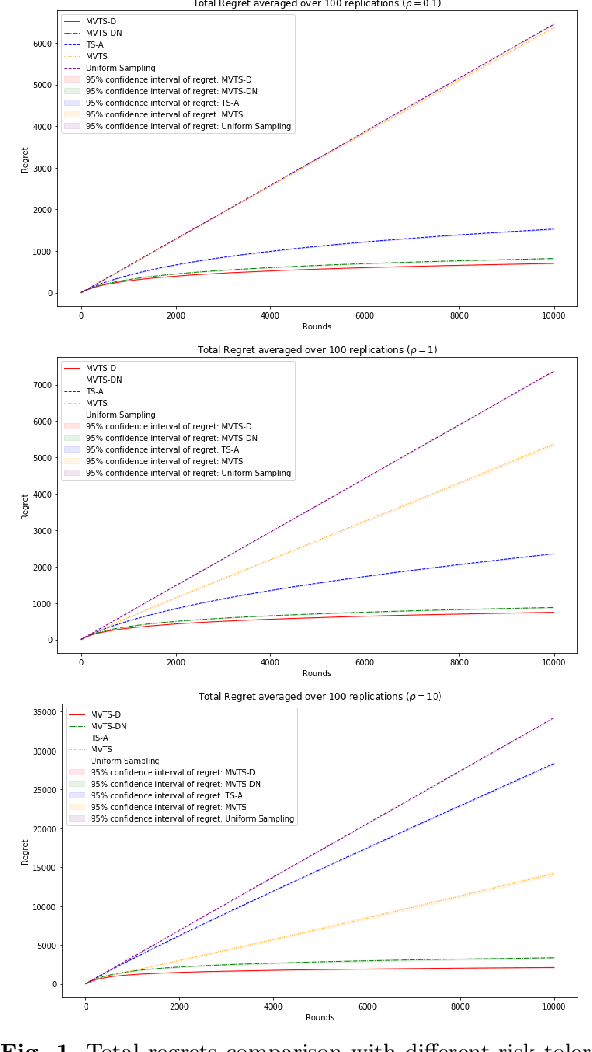
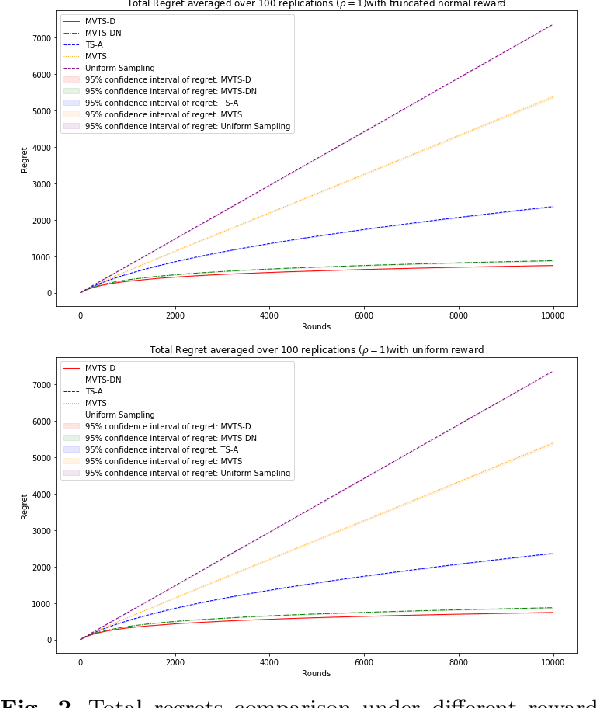
In this paper we consider the contextual multi-armed bandit problem for linear payoffs under a risk-averse criterion. At each round, contexts are revealed for each arm, and the decision maker chooses one arm to pull and receives the corresponding reward. In particular, we consider mean-variance as the risk criterion, and the best arm is the one with the largest mean-variance reward. We apply the Thompson Sampling algorithm for the disjoint model, and provide a comprehensive regret analysis for a variant of the proposed algorithm. For $T$ rounds, $K$ actions, and $d$-dimensional feature vectors, we prove a regret bound of $O((1+\rho+\frac{1}{\rho}) d\ln T \ln \frac{K}{\delta}\sqrt{d K T^{1+2\epsilon} \ln \frac{K}{\delta} \frac{1}{\epsilon}})$ that holds with probability $1-\delta$ under the mean-variance criterion with risk tolerance $\rho$, for any $0<\epsilon<\frac{1}{2}$, $0<\delta<1$. The empirical performance of our proposed algorithms is demonstrated via a portfolio selection problem.
Robust Multi-Objective Bayesian Optimization Under Input Noise
Feb 16, 2022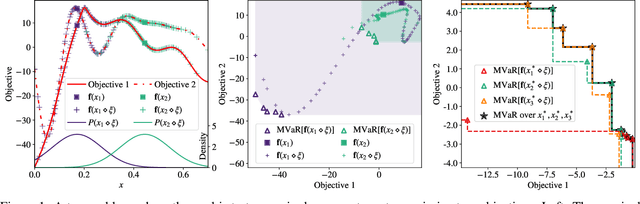
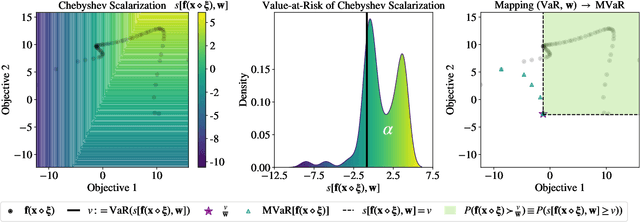
Bayesian optimization (BO) is a sample-efficient approach for tuning design parameters to optimize expensive-to-evaluate, black-box performance metrics. In many manufacturing processes, the design parameters are subject to random input noise, resulting in a product that is often less performant than expected. Although BO methods have been proposed for optimizing a single objective under input noise, no existing method addresses the practical scenario where there are multiple objectives that are sensitive to input perturbations. In this work, we propose the first multi-objective BO method that is robust to input noise. We formalize our goal as optimizing the multivariate value-at-risk (MVaR), a risk measure of the uncertain objectives. Since directly optimizing MVaR is computationally infeasible in many settings, we propose a scalable, theoretically-grounded approach for optimizing MVaR using random scalarizations. Empirically, we find that our approach significantly outperforms alternative methods and efficiently identifies optimal robust designs that will satisfy specifications across multiple metrics with high probability.